
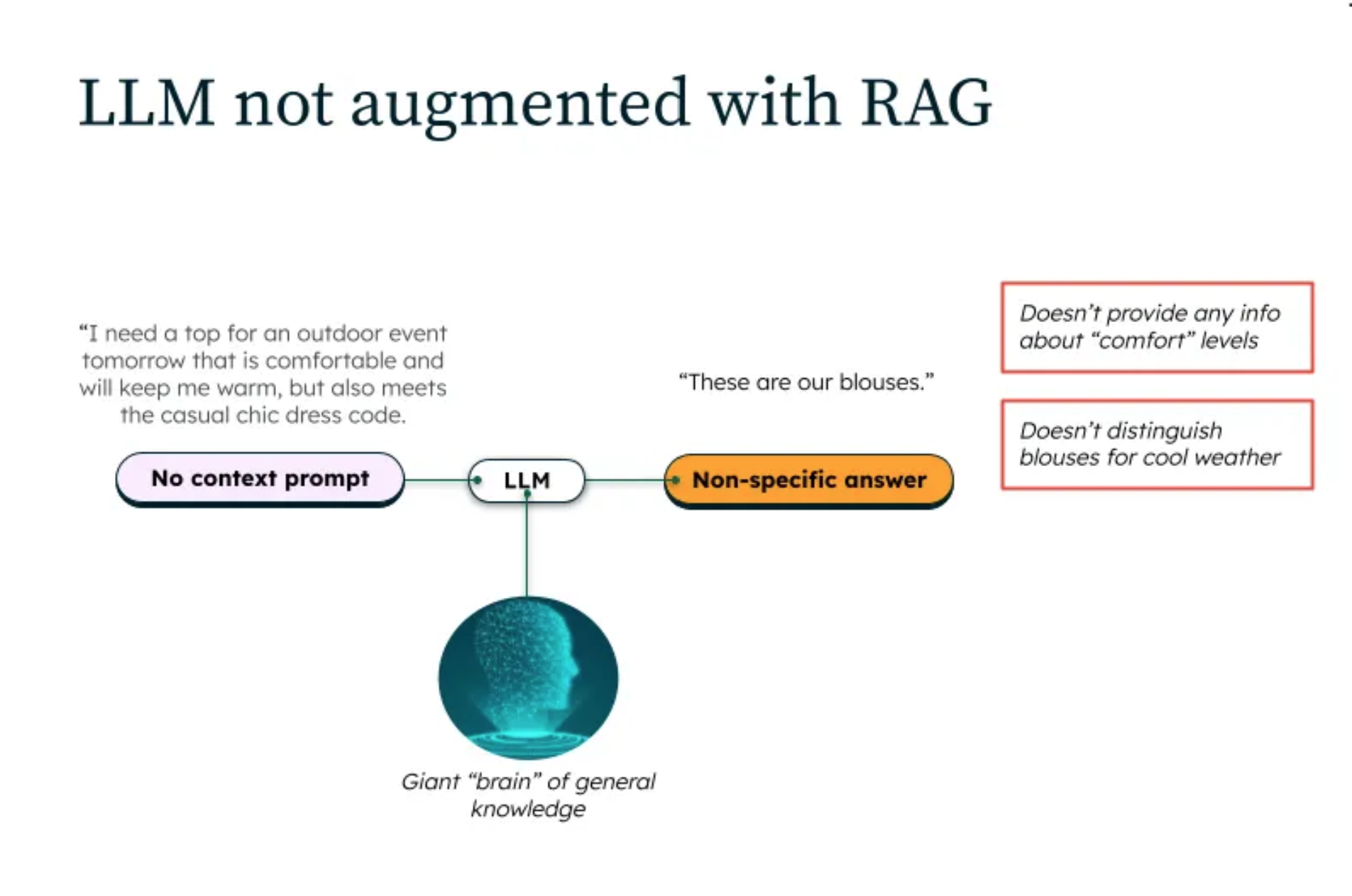
Технология дополненной генерации (RAG) (Retrieval-Augmented Generation) подобна обновлению памяти вашего искусственного интеллекта и добавлению строки поиска Google. Вместо того, чтобы придумывать ответы на основе того, что, по его мнению, он узнал во время обучения, ваша модель теперь может получать релевантную информацию в режиме реального времени — по сути, она перестала галлюцинировать и начала ссылаться на источники.
Представьте себе ChatGPT, но с доступом к вашим любимым закладкам, PDF-файлам, обсуждениям в Slack и Google Docs со странным названием, о существовании которых вы уже забыли. Это как превратить ваш искусственный интеллект в друга, который читает историю группового чата перед тем, как ответить.
На практике это означает более умные, свежие и гораздо более контекстно-зависимые ответы. Представьте себе ИИ-помощника, который не просто угадывает, но и сначала перепроверяет факты (наконец-то хоть какая-то ответственность в отношениях).
Ниже приведены 10 креативных, подходящих для новичков идей проектов, которые сочетают в себе степень магистра права и RAG. У каждого из них есть запоминающееся название, щепотка цели и как раз нужная доля технической составляющей.
Итак, возьмите свою любимую среду разработки Python (для меня это VS code/Cursor), запустите хранилище векторов, может быть, даже откройте вкладку Streamlit — и позвольте вашему ИИ работать сверхурочно, пока остывает ваш кофе.
Давайте начнем.
1. CodeWhisperer — чат-бот для разработчиков документации
Инструменты и технологии: PyPI (для загрузки кода/документации), LangChain или LlamaIndex (для загрузчиков и цепочек документов), FAISS или Chroma (векторное хранилище), GPT-4 / LLaMA-2 (LLM) и простой интерфейс (Streamlit или бот Slack).
Пошаговое проектирование:
- Собирайте документы: соберите или загрузите документацию проекта (например, файлы Markdown, документацию API).
- Предварительная обработка: разделение больших файлов на фрагменты примерно по 500 токенов и генерация вложений с помощью модели встраивания.
- Индекс: Сохраните все вложения (с указателями на источники) в FAISS.
- Запрос и извлечение: когда пользователь задает вопрос по коду, встраивайте запрос и находите наиболее соответствующие фрагменты документа.
- Сгенерировать: передать эти фрагменты и вопрос LLM (через LangChain) для получения четкого ответа или фрагмента кода.
- Пользовательский интерфейс: отображает ответ с выделением строк исходного текста и позволяет делать дополнительные запросы.
Реальные приложения: внутренняя служба поддержки разработчиков (ответы на вопросы по API), чат-боты для разработки проектов, помощники в стиле Slack или GitHub Copilot. Дополнительные идеи для обновления: добавьте синтаксический анализ, чтобы можно было получать реальные примеры кода, интегрируйтесь с GitHub для поиска кода в реальном времени или создайте расширение VS Code для справки в IDE.
2. LegalEagle — помощник по заключению контрактов на базе искусственного интеллекта
Хотите узнать, что на самом деле означает этот запутанный пункт договора? LegalEagle — это чат-бот RAG для юридических документов. Он загружает законы, контракты или судебную практику и отвечает на вопросы простым языком. Осуществляя поиск по действующим законам и постановлениям, он помогает юристам и помощникам юристов быстро находить нужную информацию. (RAG отлично подходит для юриспруденции, поскольку позволяет ИИ искать не только по судебным решениям, но и по законодательству .)
Инструменты и технологии: Python (PyMuPDF или pdfplumber для PDF-файлов), OpenAI/Anthropic LLM, Pinecone или Qdrant (векторная база данных), LangChain или Haystack, а также фронтенд React или Streamlit.
Пошаговый процесс проектирования:
- Прием данных: загрузка законов, нормативных актов или контрактов (в формате PDF или текста).
- Разделение на части и встраивание: разделение на разделы/абзацы; создание встраиваний.
- Индексирование: сохранение внедрений в векторной базе данных со ссылками на документ и страницу.
- Семантический поиск: по запросу (например, «Каковы мои права в соответствии с положением о конфиденциальности?» ) найдите наиболее подходящие фрагменты.
- Генерация ответов: отправьте полученные фрагменты в LLM с подсказкой типа «Основываясь на этих фрагментах, что говорится в контракте о X?»
- Пользовательский интерфейс и взаимодействие: отображение ответа и выделенного исходного текста, а также возможность «задать уточняющий вопрос» или загрузить краткие изложения.
Реальные области применения: юридические фирмы или отделы по обеспечению соответствия, изучающие внутренние политики, чат-боты для ответов на юридические вопросы потребителей и помощники по проверке контрактов.
Дополнительные идеи для обновления: добавьте фильтры по юрисдикции или дате, поддерживайте несколько языков (например, GDPR на английском языке по сравнению с оригинальным французским), реализуйте цикл обратной связи для уточнения ответов или интегрируйте схему знаний для юридических лиц.
3. MediGuru — AI-помощник по медицинским вопросам и ответам
Представьте себе ИИ, способный быстро находить медицинские рекомендации в научных работах (не замену врача, а очень умного библиотекаря медицинской информации). MediGuru позволяет вам задавать вопросы, например: «Каковы новейшие методы лечения ХОБЛ?», и он ищет ответы в медицинских журналах или руководствах. Поскольку знания в здравоохранении быстро меняются, RAG идеально подходит для этой задачи: ИИ извлекает свежую и актуальную информацию из проверенных источников, а не из устаревших воспоминаний. Кроме того, он, как правило, даёт более точные и актуальные ответы, основанные на реальных данных.
Инструменты и технологии: LangChain (загрузчики документов), модель встраивания Hugging Face/BioMed, хранилище векторов (Chroma или Weaviate), OpenAI/GPT-4 или Claude (LLM) и интерфейс Streamlit или Flask.
Пошаговый процесс проектирования:
- Собирайте данные: извлекайте аннотации/статьи из PubMed, ВОЗ или больничных протоколов.
- Предварительная обработка: чистый текст, разделенный на разделы (например, «Диагноз», «Лечение»).
- Встраивание: создание встраиваний (встраивание текста BioBERT или OpenAI).
- Индекс: Хранить векторы в FAISS/Pinecone со ссылками на документы.
- Запрос и извлечение: пользователь задает медицинский вопрос; система находит соответствующие отрывки.
- Ответ: LLM синтезирует ответ (со ссылками на исходные тексты).
- Пользовательский интерфейс: Представить ответ + ссылку на источники; включить отказ от ответственности и последующие действия «спросить врача».
Реальные приложения: базы знаний больниц для врачей, специалистов по проверке симптомов пациентов (не связанных с диагностикой), медицинских научных сотрудников, подготавливающих резюме статей.
Бонусные идеи для обновления: включите ссылки (например, названия журналов в сносках), доработайте LLM по медицинским вопросам и ответам, добавьте потоки проверки симптомов или подключитесь к данным носимых устройств (частота сердечных сокращений и т. д.) для получения персонализированных советов.
4. LearnBot — персонализированный помощник-репетитор
Нужен напарник по учёбе? LearnBot позволяет учащимся общаться с ИИ-преподавателем, который извлекает ответы из учебников и конспектов. Например, если вы спросите «Объясните второй закон Ньютона», он может найти определения или примеры из научных текстов, а не гадать. Это означает, что ответы будут точными и специфичными для предметной области (системы RAG известны своей более высокой точностью и актуальностью ответов).
Инструменты и технологии: LangChain, открытые образовательные ресурсы (Khan Academy, Wikipedia), VectorDB (Chroma), GPT-4 или доработанный открытый LLM, а также пользовательский интерфейс чата (бот Discord или Streamlit).
Пошаговый процесс проектирования:
- Загрузите учебные материалы: загружайте учебники, конспекты лекций или наборы вопросов и ответов.
- Разделить на части и встроить: разбить главы на небольшие фрагменты и встроить их.
- Индексирование: сохранение векторов в базе данных с тематическими метками.
- Запрос: Студент задает вопрос.
- Семантический поиск: найдите соответствующие отрывки (например, из текста по алгебре или истории).
- Ответ преподавателя: LLM создает объяснение, тест или пример проблемы, используя извлеченный контент.
- Цикл обратной связи: позвольте ученику задавать уточняющие вопросы или оценивать ясность изложения.
Реальные приложения: услуги онлайн-репетиторства, чат-боты для помощи в выполнении домашних заданий, помощники в изучении языков.
Дополнительные идеи для усовершенствования: добавьте многоэтапное обучение (отслеживайте прогресс учащегося в памяти), создавайте практические тесты, включайте голосовое управление (чтобы система зачитывала ответы вслух) или подключайтесь к базе данных для подготовки к экзаменам.
5. NewsDigest — сводка новостей и вопросы и ответы
Слишком много источников новостей, слишком мало времени? NewsDigest сканирует последние статьи, а затем использует RAG для резюмирования или ответа на вопросы. Например, он может извлекать цитаты из нескольких новостных агентств, чтобы ответить на вопрос «Что происходит с мировой экономикой?». Объединяя поиск с генеративным ИИ, он предоставляет контекстно-обогащённые рефераты (RAG, как было показано, улучшает такие задачи, как реферирование и постановка вопросов).
Инструменты и технологии: API новостей или RSS-скраперы, разделители текста, LangChain/Arxiv-lingua (для многоязыкового реферирования), VectorDB (FAISS/Pinecone), GPT или LLM с открытым исходным кодом (для реферирования) и веб-панель управления.
Пошаговый процесс проектирования:
- Сбор новостей: сбор заголовков/статей из RSS-каналов или API.
- Предварительная обработка: фильтрация по дате/ключевому слову, очистка HTML, разбиение длинных статей на части.
- Встраивание: создание векторов для каждого фрагмента.
- Индексирование: хранить внедрения в хронологическом порядке.
- Запрос и поиск: при запросе темы извлекайте наиболее соответствующие фрагменты из недавних статей.
- Составление резюме: LLM составляет краткое резюме или маркированный список ключевых моментов.
- Пользовательский интерфейс: Показывать дайджест со ссылками на исходные статьи, разрешить подписку по теме или электронной почте.
Реальные приложения: сайты-агрегаторы новостей, отчеты о рыночной аналитике, ежедневные информационные письма.
Дополнительные идеи для обновления: добавьте анализ настроений (положительные/отрицательные новости), графики тенденций (с использованием полученных данных), проверку фактов по официальным источникам или многоязычную поддержку.
6. TripPlanner AI — интеллектуальный генератор маршрутов путешествий
Хотите, чтобы ваш ИИ-друг мог спланировать ваш отпуск? TripPlanner AI запрашивает ваши предпочтения (пляж, бюджет, даты) и сканирует данные с туристических сайтов, а затем использует RAG для составления маршрута на каждый день. Например, он может получать информацию об отелях и местных мероприятиях из актуальных источников. Это идеально подходит для планирования путешествий, поскольку позволяет получать данные в режиме реального времени (погоду, статус рейса и т. д.) вместо устаревшей информации.
Инструменты и технологии: веб-скраперы (для авиакомпаний, отелей, обзоров), API Google Карт, LangChain (для обработки запросов), VectorDB (Qdrant), GPT-4o (для планирования естественного языка), а также React или мобильный пользовательский интерфейс.
Пошаговый процесс проектирования:
- Сбор данных: сбор данных о пунктах назначения (фотографии, достопримечательности, транспорт) из TripAdvisor, Wikipedia и т. д.
- Предварительная обработка: геотеговая информация, фрагмент по местоположению или теме.
- Встраивание: создание векторов для достопримечательностей, советов, обзоров.
- Индекс: Хранить векторы с геоданными.
- Запрос: Пользователь вводит «3-дневный маршрут по Лондону для семей».
- Поиск: извлечение соответствующих описаний (музеи, парки, рестораны).
- Генерация ответов: LLM организует их в виде расписания с пояснениями. 8. Пользовательский интерфейс: отображение маршрута с картами и ссылками для бронирования.
Реальные приложения: чат-боты туристических агентств, приложения для планирования отпуска, голосовые помощники (например, навык Alexa).
Дополнительные идеи для улучшения: добавьте интеграцию с системами бронирования (авиабилеты, отели), пользовательские рейтинги для уточнения предложений, динамическую корректировку (если вы остаетесь дольше, выполните перерасчет) или функции дополненной реальности (наведите камеру и спросите, что находится поблизости).
7.ShopAdvisor — помощник клиента электронной коммерции
Превратите руководства по продуктам и часто задаваемые вопросы в умного помощника по покупкам. ShopAdvisor позволяет покупателям задавать вопросы, например: «Подходит ли этот чехол для iPhone 14?», а затем находит ответы в характеристиках и отзывах. В сфере обслуживания клиентов RAG собирает реальную информацию о продуктах и историю покупок, чтобы давать персонализированные ответы — гораздо лучше, чем стандартные ответы чат-бота.
Инструменты и технологии: VectorDB (Weaviate или Pinecone), LangChain (цепочка RetrieverQA), данные каталога продуктов (CSV или Shopify API), GPT-4o (LLM) и веб-интерфейс или чат-интерфейс (Zendesk/WhatsApp).
Пошаговый процесс проектирования:
- Импорт данных о продукте: загрузка описаний, руководств, спецификаций.
- Разделение текста: разбейте спецификации/обзоры на части.
- Встраивание: создание встраиваний и их индексация.
- Запрос: Клиент задает вопрос о продукте.
- Поиск: извлечение соответствующих фрагментов (изображений, текста).
- Ответ и объяснение: магистр права составляет ответ и может даже процитировать руководство.
- Пользовательский интерфейс: показать ответ и ссылки на страницы продуктов, дать пользователю возможность «нажать, чтобы купить».
Реальные приложения: чат-боты для розничной торговли, автоматизированные страницы часто задаваемых вопросов, послепродажная поддержка (например, устранение неисправностей устройств).
Дополнительные идеи для обновления: добавьте голосовую поддержку (колл-центр), перевод вопросов и ответов для клиентов по всему миру, интегрируйте данные учетных записей клиентов для персонализации или продавайте сопутствующие продукты.
8. JobMate — инструктор по AI-резюме и собеседованиям
Получите работу быстрее с помощью карьерного коуча на основе искусственного интеллекта. JobMate обрабатывает описания вакансий и статьи с советами по карьере. Когда вы спрашиваете: «Как составить резюме для должности специалиста по анализу данных?» , JobMate находит соответствующие советы (навыки, ключевые слова) и даже составляет список основных пунктов. JobMate также может моделировать вопросы для собеседования, находя распространённые вопросы в вашей области.
Инструменты и технологии: данные, полученные из Indeed/LinkedIn (объявления о вакансиях), StackOverflow (для технических вопросов и ответов), LangChain, FAISS, GPT (или открытого LLM-курса, предназначенного для собеседований), а также простого веб-приложения.
Пошаговый процесс проектирования:
- Сбор данных: соберите образцы объявлений о вакансиях и успешных резюме.
- Предварительная обработка: извлечение обязанностей и требуемых навыков.
- Встраивание: векторизация требований к вакансиям и советов по составлению резюме.
- Индексирование: сохранение внедрений.
- Запрос: Пользователь вводит свой профиль и целевую роль.
- Поиск: поиск соответствующих навыков и ключевых слов.
- Сгенерировать: LLM предлагает редактирование резюме или общие вопросы для собеседования.
- Пользовательский интерфейс: позволяет пользователю уточнять ответы, экспортировать резюме.
Реальные применения: университетские центры карьеры, платформы поиска работы, службы коучинга талантов.
Бонусные идеи для улучшения: добавьте практические собеседования в реальном времени (преобразование речи в текст), подключитесь к LinkedIn для автоматического заполнения информации, включите тенденции заработной платы или используйте обучение с подкреплением для оценки лучших формулировок в резюме.
9. BrainyBinder — персональная база знаний
Создайте свой собственный «второй мозг». BrainyBinder берёт ваши заметки, PDF-файлы и закладки, а затем позволяет вам обращаться к вашему личному архиву. Например, вы можете спросить: «Что я узнал о нейронных сетях в первом вопросе?» , и система найдёт ответы в ваших сохранённых документах. По сути, ИИ становится вашим мемориальным библиотекарем , объединяя все источники, чтобы ничего не забыть.
Инструменты и технологии: LangChain или LlamaIndex (для различных загрузчиков данных: Git, Google Docs, Markdown), локальное хранилище векторов (Chroma или Qdrant), GPT-4o (LLM) и Electron или веб-интерфейс.
Пошаговый процесс проектирования:
- Загрузка личных файлов: подключение Google Drive, Notion или локальных папок.
- Разделение на фрагменты и встраивание: обработка каждого документа/заметки, генерация встраиваний.
- Индекс: ведите единую схему знаний по всем темам.
- Запрос: Пользователь спрашивает о чем-либо (подробностях проекта, прошедшей лекции и т. д.).
- Извлечь: найти наиболее соответствующие заметки или электронные письма.
- Ответ: LLM синтезирует связное резюме или ответ.
- Пользовательский интерфейс: отображать ответ со ссылками на исходные заметки; разрешать добавлять теги и оценки.
Реальные применения: исследователи, управляющие литературой, студенты, организовывающие учебные материалы, специалисты, отслеживающие встречи/идеи.
Дополнительные идеи для обновления: семантическая маркировка и фильтрация (дата, проект), мобильная синхронизация (поиск на телефоне), проактивные напоминания («Вы не просматривали этот файл целый месяц — сводка?») или многоагентная настройка (один агент для каждой области знаний).
10. ChefAI — помощник по кулинарии и рецептам
Больше никогда не будете гадать, что приготовить на ужин! ChefAI может обсуждать рецепты и кулинарные советы. Вы указываете ему любимые кулинарные книги или кулинарные блоги, а затем спрашиваете: «Что можно приготовить из шпината и нута?» Он находит подходящие рецепты и даже предлагает варианты (безглютеновые заменители, уровень остроты).
Инструменты и технологии: набор данных рецептов (Kaggle или скопированные сайты), встраивание OpenAI или Sentence Transformers, LangChain (для цепочек контроля качества), GPT-4o или многоязычный LLM (кулинарные термины) и пользовательский интерфейс (мобильное приложение или веб-сайт).
Пошаговый процесс проектирования:
- Собирайте рецепты: извлекайте информацию с сайтов с рецептами или импортируйте книгу рецептов (структурированную по ингредиентам и инструкциям).
- Предварительная обработка: нормализация ингредиентов, разделение шагов на предложения.
- Встраивание: векторизуйте каждый список ингредиентов или шаг.
- Индекс: Магазин в FAISS.
- Запрос: Пользователь перечисляет доступные ингредиенты или идеи блюд.
- Извлечь: найти похожие рецепты.
- Сгенерировать: Магистр права предлагает рецепт или адаптирует его («Добавить больше чеснока» и т. д.).
- Пользовательский интерфейс: отображение рецепта, информации о пищевой ценности и возможность внесения изменений (порций, диеты).
Реальные приложения: умные помощники на кухне, приложения для планирования диеты, кулинарные чат-боты для ресторанов.
Бонусные идеи для обновления: интеграция с голосовыми помощниками (Alexa, Google Home), добавление отслеживания остатков продуктов в кладовой (напоминание о том, что у вас осталось), создание списков покупок или автоматическое преобразование единиц измерения.
Каждый из этих проектов демонстрирует, как объединить LLM с системой поиска данных для создания более интеллектуальных приложений ИИ. Основывая модель на реальных данных (через RAG), вы делаете её более полезной и надёжной. Выберите один (или два!), который вас вдохновляет, и начните работу — ваше портфолио станет доказательством того, что вы можете сделать ИИ не только умным, но и практичным и увлекательным в 2025–26 годах.
Если вы интересуетесь наукой о данных, искусственным интеллектом/машинным обучением и разработкой искусственного интеллекта, смело беритесь за разные типы проектов. Всегда старайтесь читать и реализовывать проекты. Работайте над свежими идеями. Мой принцип ясен: учиться -> создавать -> показывать -> получать работу.
Источник:
https://techwithram.medium.com/top-10-llm-rag-projects-for-your-ai-portfolio-2025-26-582cc7ab6507







