
(0:10) Эта команда — Checkmate, это сотрудничество между DPA, которое является немецким агентством печати, (0:15) The Times и The Sun из News UK, Data Critica из Мексики и BBC. (0:20) Checkmate — это инструмент, который может выявлять претензии в режиме реального времени в прямых трансляциях. (0:25) И сегодня, чтобы рассказать нам больше о проекте, у нас есть Надин и Арне, и я передаю их вам.
(0:31) Итак, как нас только что представили, мы — Checkmate, который является инструментом проверки фактов в реальном времени с помощью искусственного интеллекта. (0:39) Итак, мы начали с постановки проблемы: дезинформация является критической проблемой для новостных редакций по всему миру. (0:45) И эта проблема только обостряется, когда происходят значительные события, такие как политические выборы.
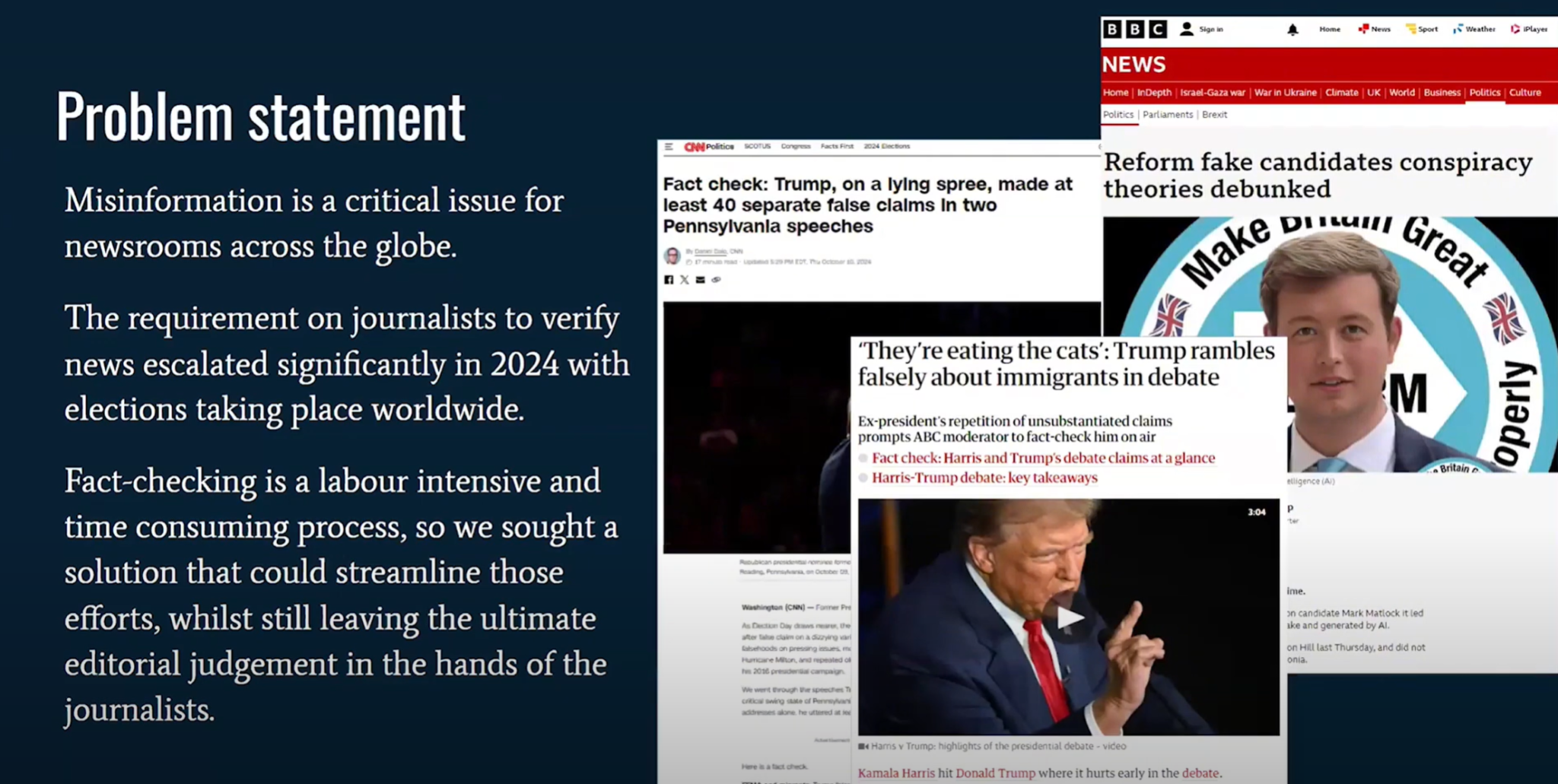
(0:52) Мы увидели это в реальном времени во время недавних выборов в США. Проверка фактов — очень трудоемкий процесс для журналистов. (0:59) Она отнимает у них огромное количество времени, и на них лежит большая ответственность за точность.
(1:03) Поэтому мы искали решение, которое могло бы упростить эти процессы и при этом оставить окончательное редакционное решение в руках журналистов. (1:14) Поэтому, прежде чем начать работу над Checkmate, мы провели несколько первоначальных исследований пользователей. (1:18) Мы сделали это потому, что хотели понять, какие ключевые болевые точки существуют у журналистов, а также какие ожидания они возлагают на подобный инструмент.
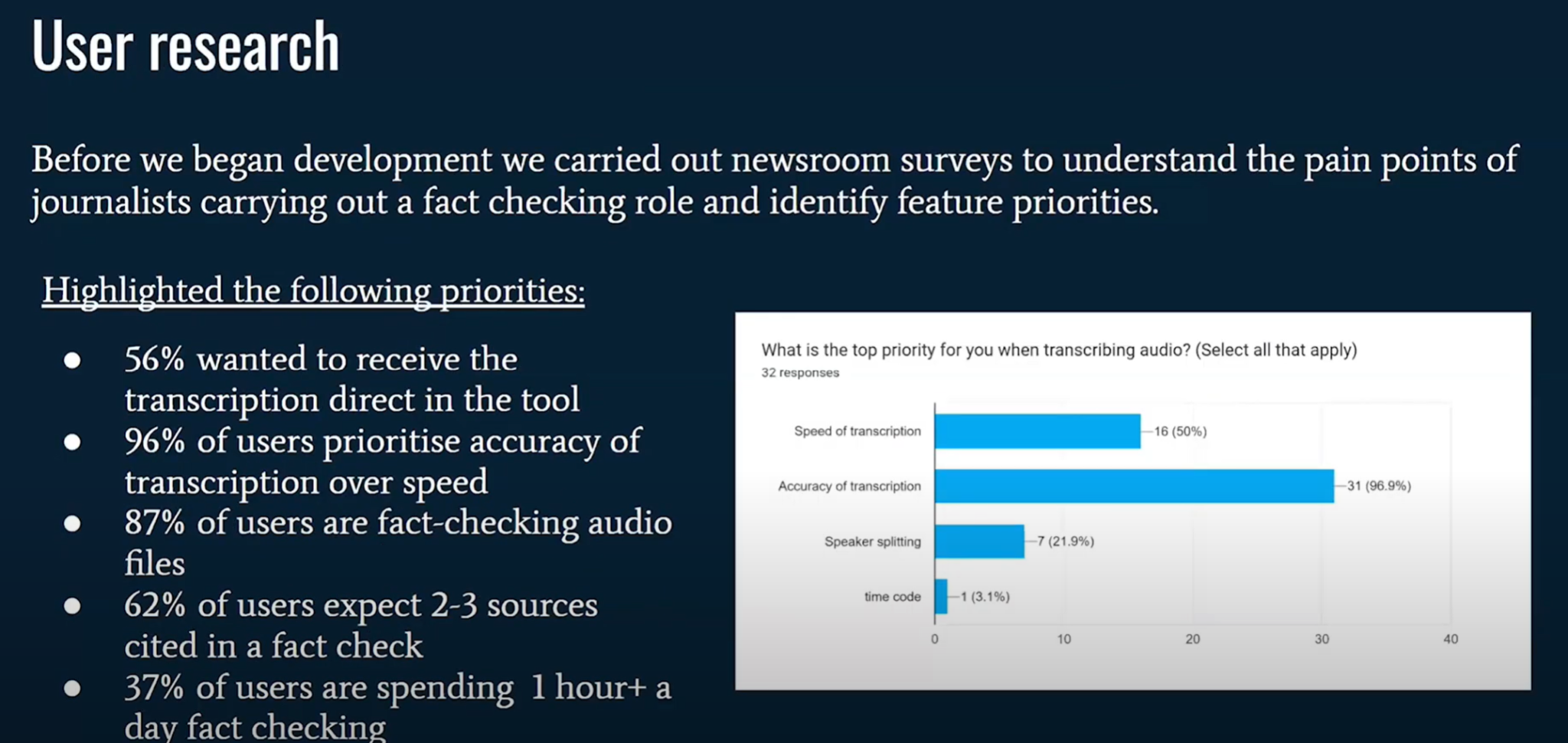
(1:27) Это дало нам несколько действительно интересных основополагающих фактов, от которых мы могли бы отталкиваться. (1:31) Так, например, 96 % пользователей ставят точность транскрипции выше скорости, что помогло нам в принятии будущих решений. (1:42) Я извинюсь, потому что теперь вы увидите меня дважды, когда я буду показывать демонстрацию.
(1:47) Здравствуйте и добро пожаловать на демонстрацию Checkmate. (1:50) Итак, сегодня я собираюсь показать вам инструмент Checkmate. (1:54) Это инструмент проверки фактов в реальном времени для журналистов для видео и аудио.
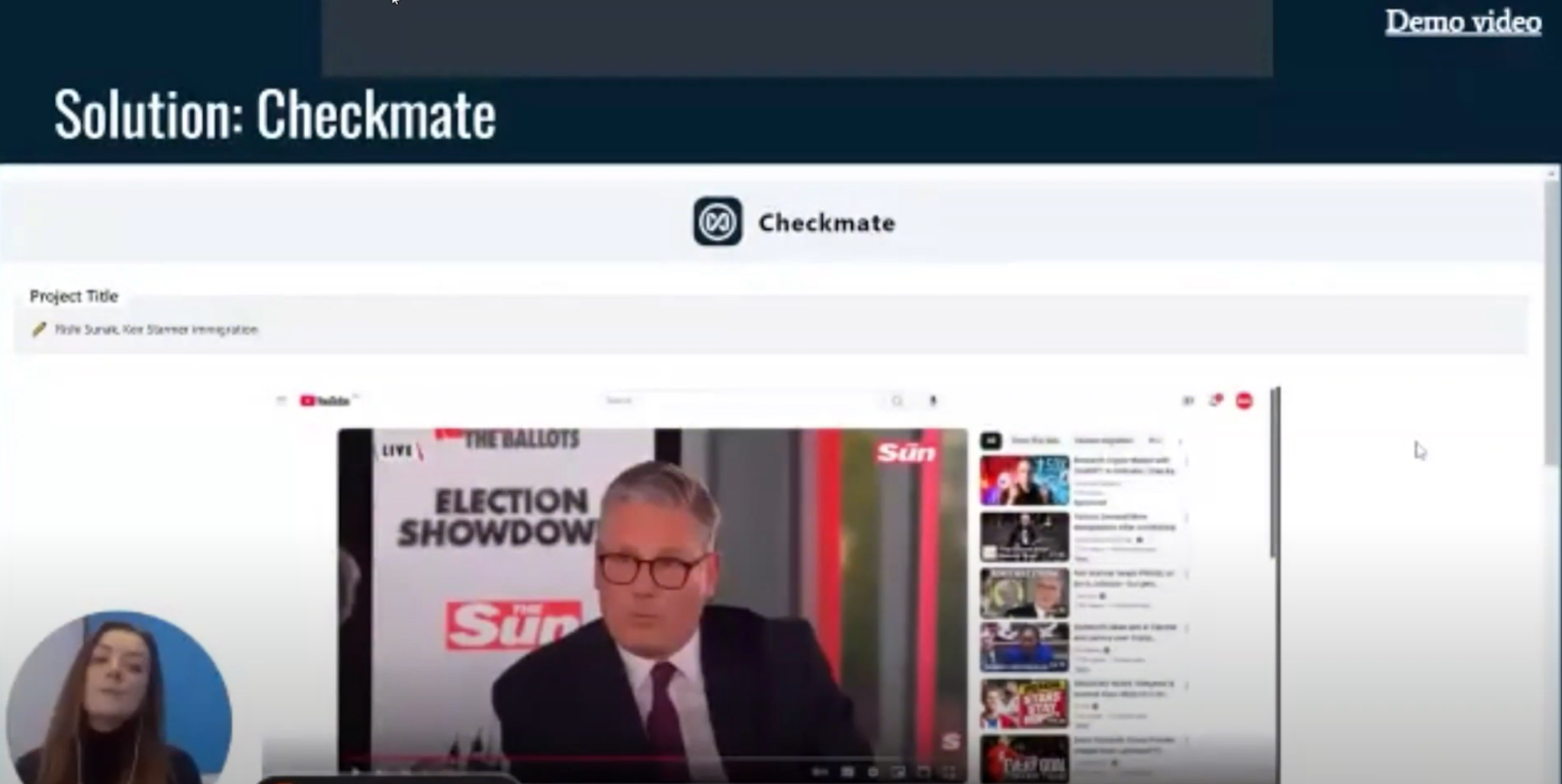
(2:00) Когда вы заходите в Checkmate, первым делом появляется всплывающее окно, которое предлагает вам поделиться видео, воспроизводимым в другой вкладке. (2:15) Для того чтобы сделать это как можно более удобным, я сделал это раньше, чтобы показать вам все возможности. (2:25) Итак, когда видео воспроизводится на другой вкладке, оно начинает подтягиваться к инструменту Checkmate.
(2:33) Примерно через 30 секунд задержки вы начнете видеть транскрипт. (2:42) Итак, ваше видео будет воспроизводиться в реальном времени в окне, а затем, когда кто-то начнет говорить, начнет подтягиваться расшифровка. (2:49) По мере того как стенограмма будет подтягиваться, она будет искать и определять утверждения в этом предложении.
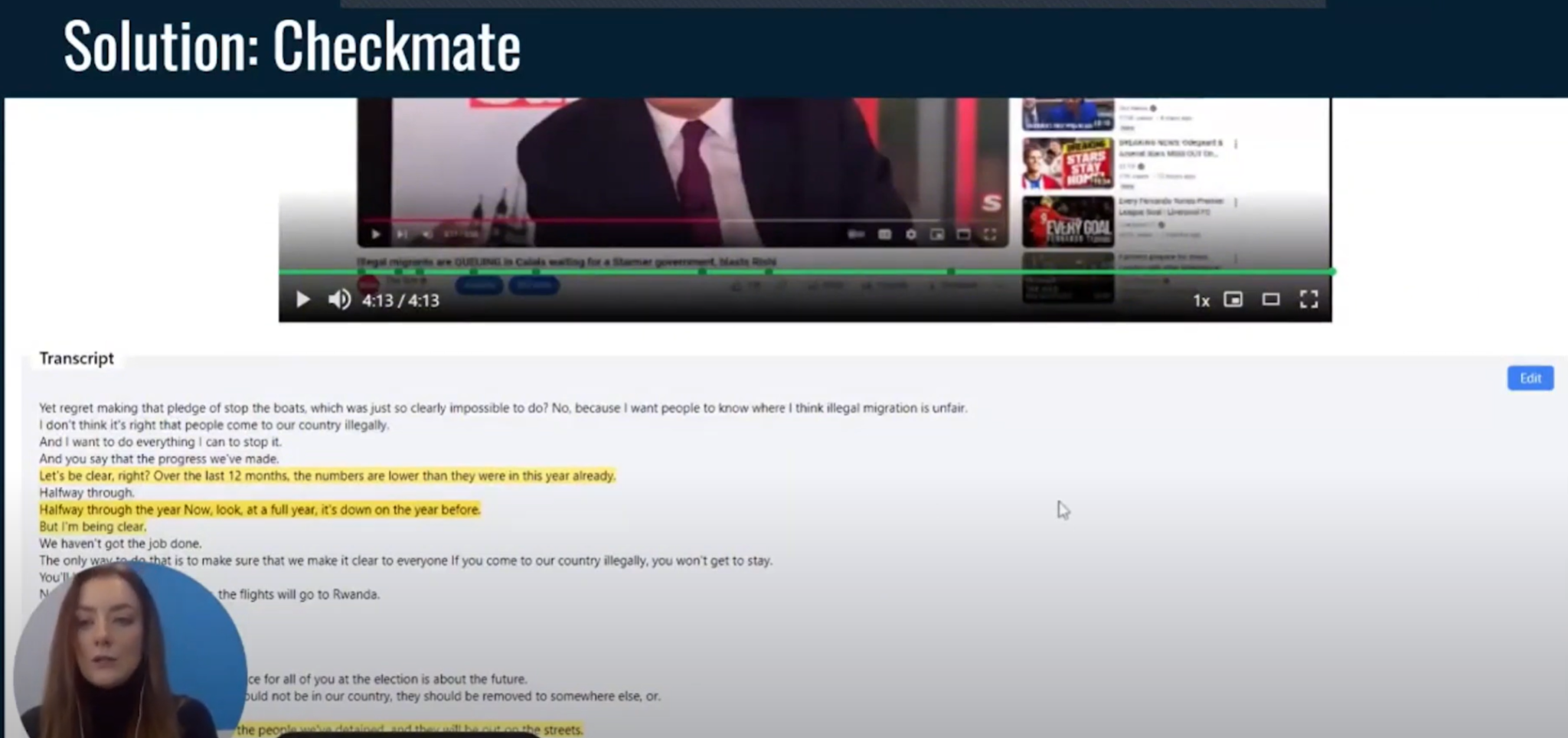
(2:56) Эти утверждения будут выделены желтым цветом. (3:00) После того как они будут выделены желтым цветом и введены в систему, она начнет извлекать утверждения и искать соответствующий источник, который можно привести, чтобы вы могли проверить, является ли это утверждение точным или нет. (3:18) Вы можете видеть, что в этом транскрипте было довольно много утверждений.
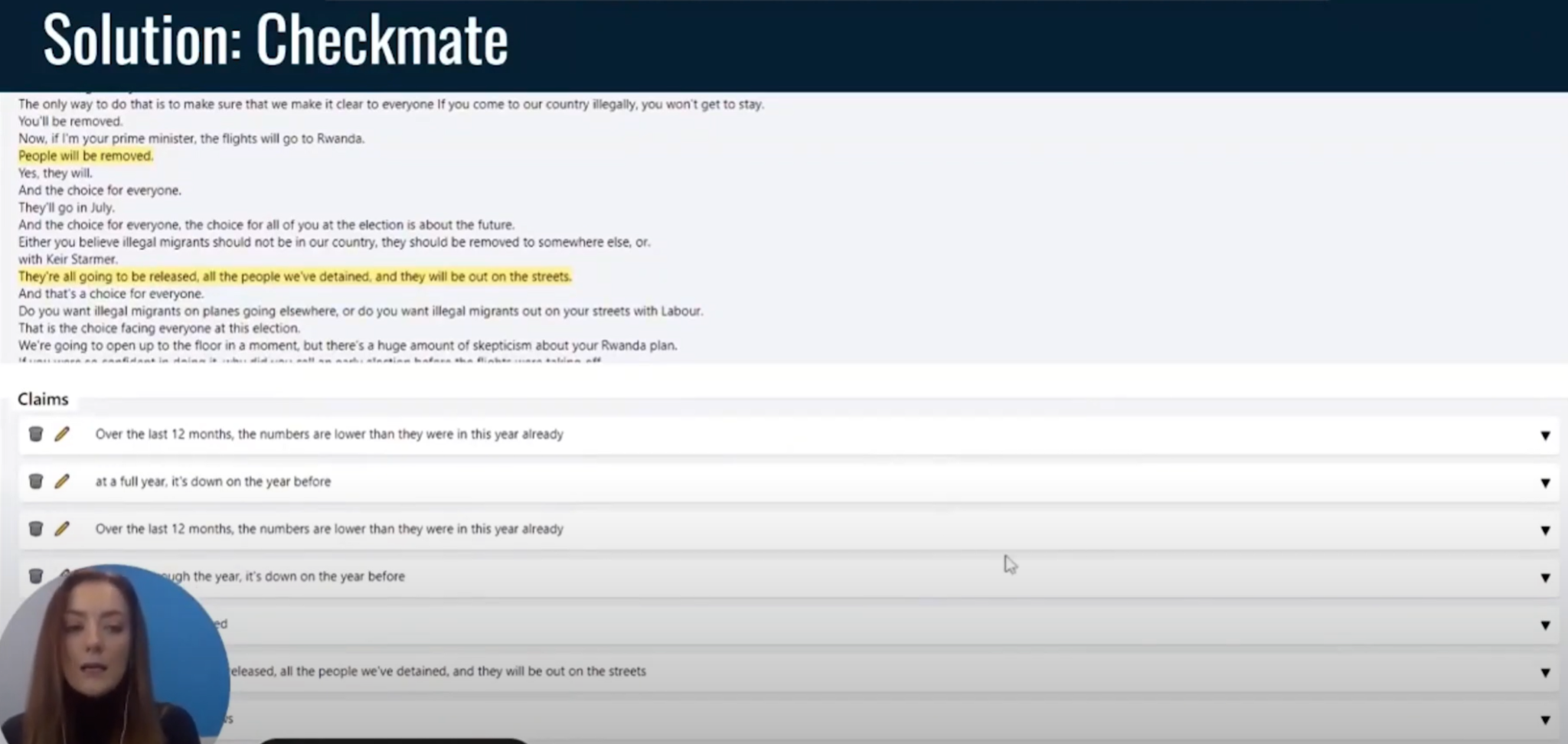
(3:24) Если вы нажмете на стрелку вниз, то увидите дату, когда это утверждение имело место. (3:32) Вы можете увидеть копию претензии. (3:35) И здесь вы можете увидеть, что он ищет соответствующие источники.
(3:39) Просто посмотрите, не попадется ли что-нибудь. (3:42) Да, вот так. (3:44) Теперь вы можете видеть, что он привлек два источника из BBC.
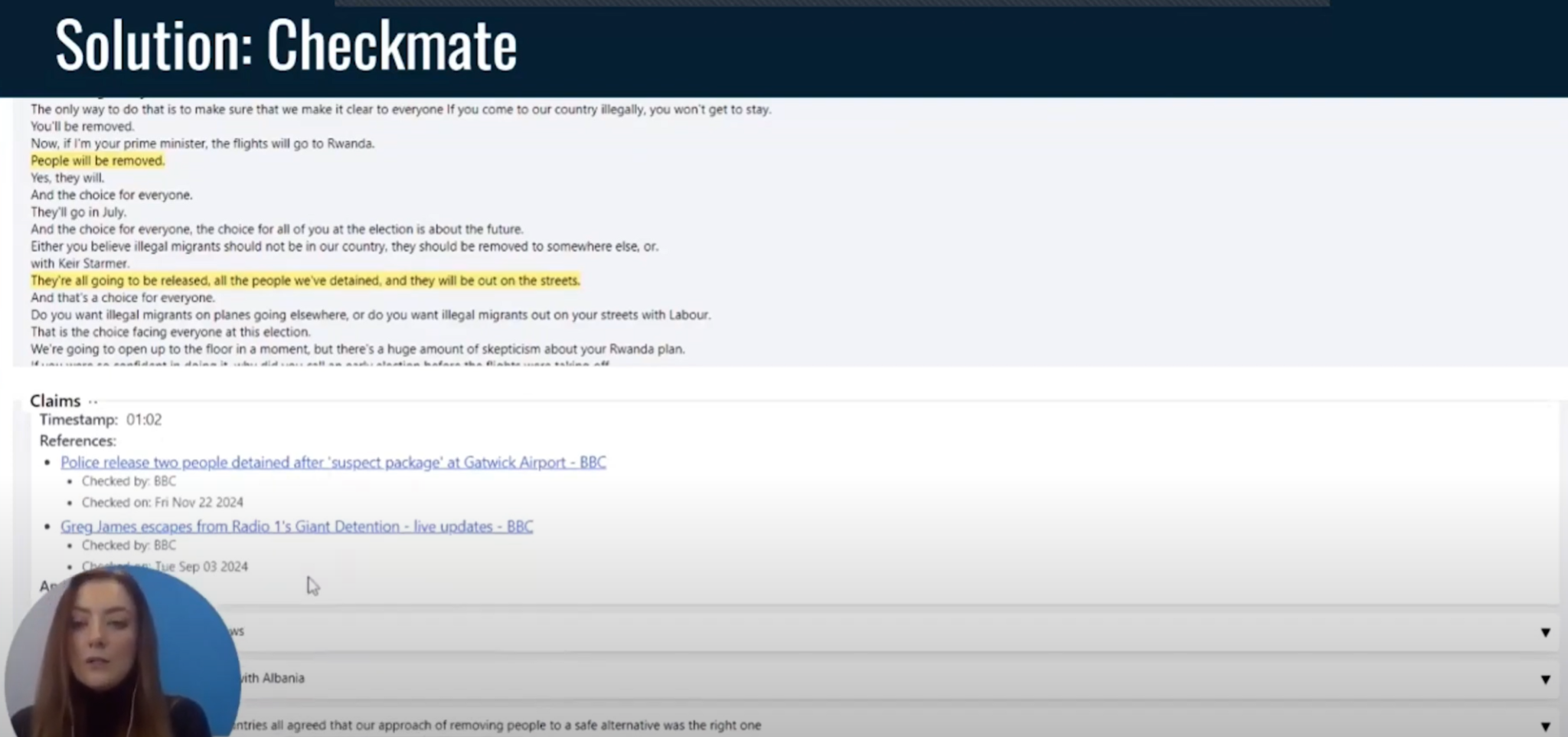
(3:46) Вы можете нажать на них, а затем просмотреть статью, чтобы понять, является ли это точным утверждением или вам нужно получить информацию из другого места. (4:04)
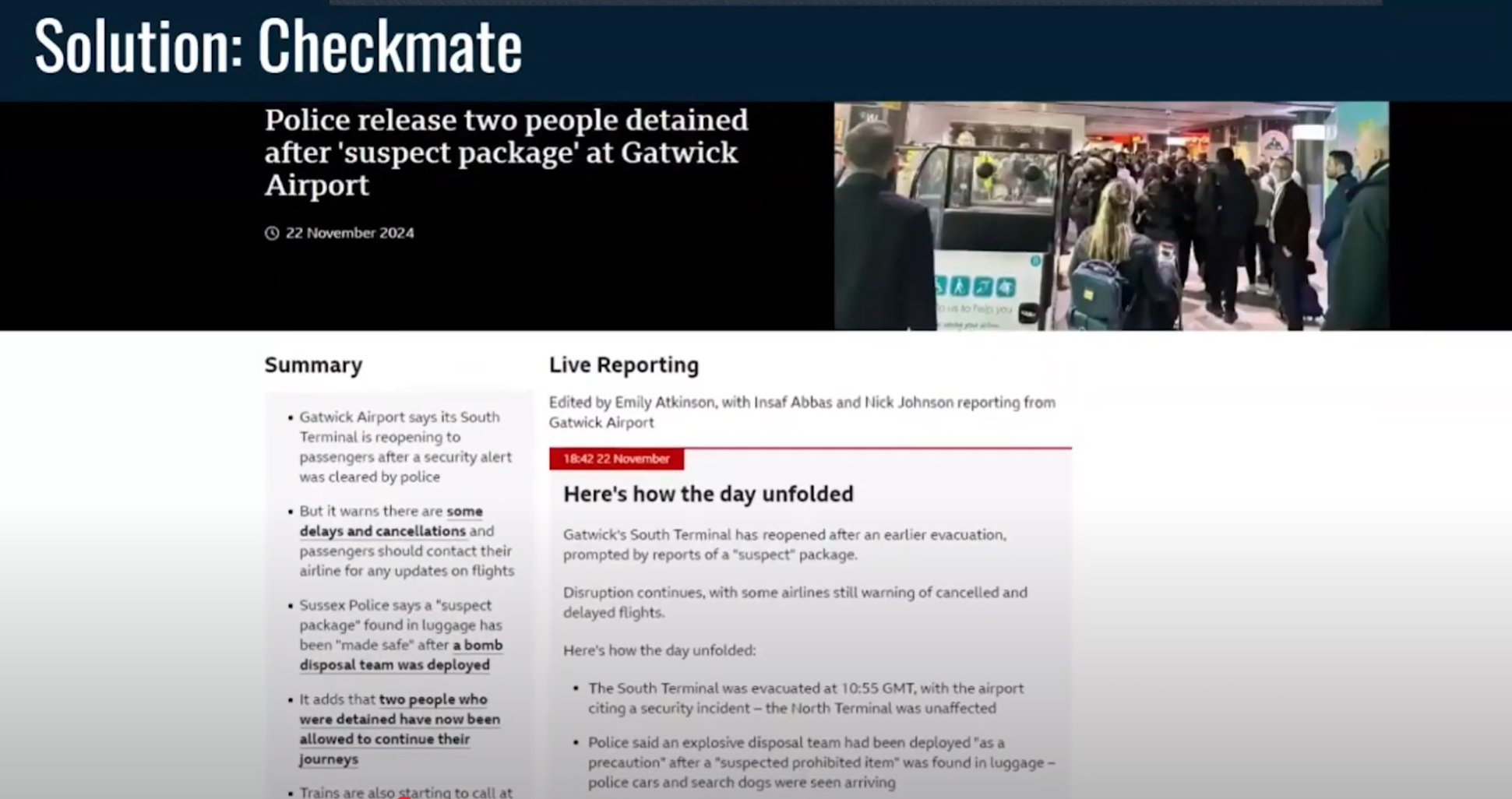
После того как вы вернетесь в систему и просмотрите свои заявления, вы также сможете отредактировать любое из поступивших заявлений. (4:10) Например, если кто-то говорит название места или чье-то имя, в транскрипте может быть пропущено место, где это должно быть.
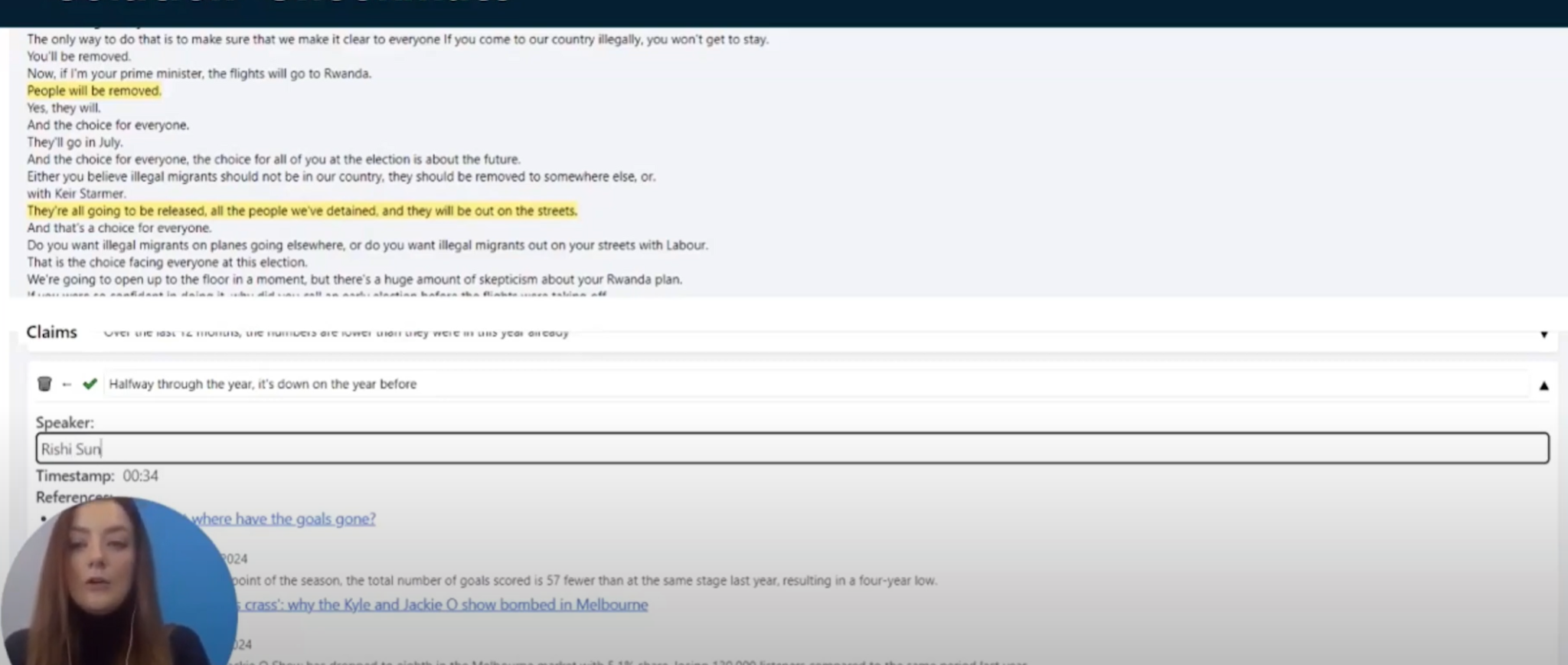
(4:21) Редактировать очень просто. (4:22) Вы просто нажимаете на выпадающий список и маленький значок карандаша и можете исправить все, что вам нужно изменить. (4:30) Вы также можете указать спикера, который сказал это утверждение.
(4:34) Это очень полезно, если вы сотрудничаете с другим журналистом или кем-то еще в вашей компании. (4:40) Итак, я вижу, что это сказал Риши Сунак, и теперь эта претензия будет отнесена к нему, и я нажму на эту маленькую галочку. (4:50) И теперь следующий человек, который придет посмотреть на этот проект, увидит: «ОК, эта претензия была подана Риши Сунаком».
(4:56) Когда вы вернетесь к проигрывателю, и стенограмма будет завершена, и вы перестанете загружать ее в Checkmate, (5:03) вдоль полосы соскребания он также выделит претензии, которые программа обнаружила для вас. (5:10) И вы также можете увидеть небольшое резюме того, что это за претензия. (5:14) Это позволяет вам легко перейти к повторному просмотру определенного момента в видео.
(5:20) И тогда вы сможете получить более широкий контекст вокруг этого момента. (5:27) Вы также можете дать название своему проекту. Итак.
(5:31) Это можно редактировать в любое время. (5:33) Это облегчает поиск в системе, чтобы проверить, какая часть работы является таковой. (5:40) И затем вы можете перейти на главную страницу Checkmate, где вы можете увидеть все свои предыдущие проекты.
(5:50) Вы можете увидеть, что некоторые из них не были названы. (5:53) Но вот еще один. И вы можете просто нажать кнопку «Открыть».
(6:00) И зайти в него, чтобы посмотреть в любое время. В общем, это краткий обзор Checkmate. (6:09) Надеюсь, вам понравится пользоваться этим инструментом.
И большое спасибо за просмотр. (6:15) Большое спасибо, Надин. Я постараюсь объяснить, что происходит под капотом.
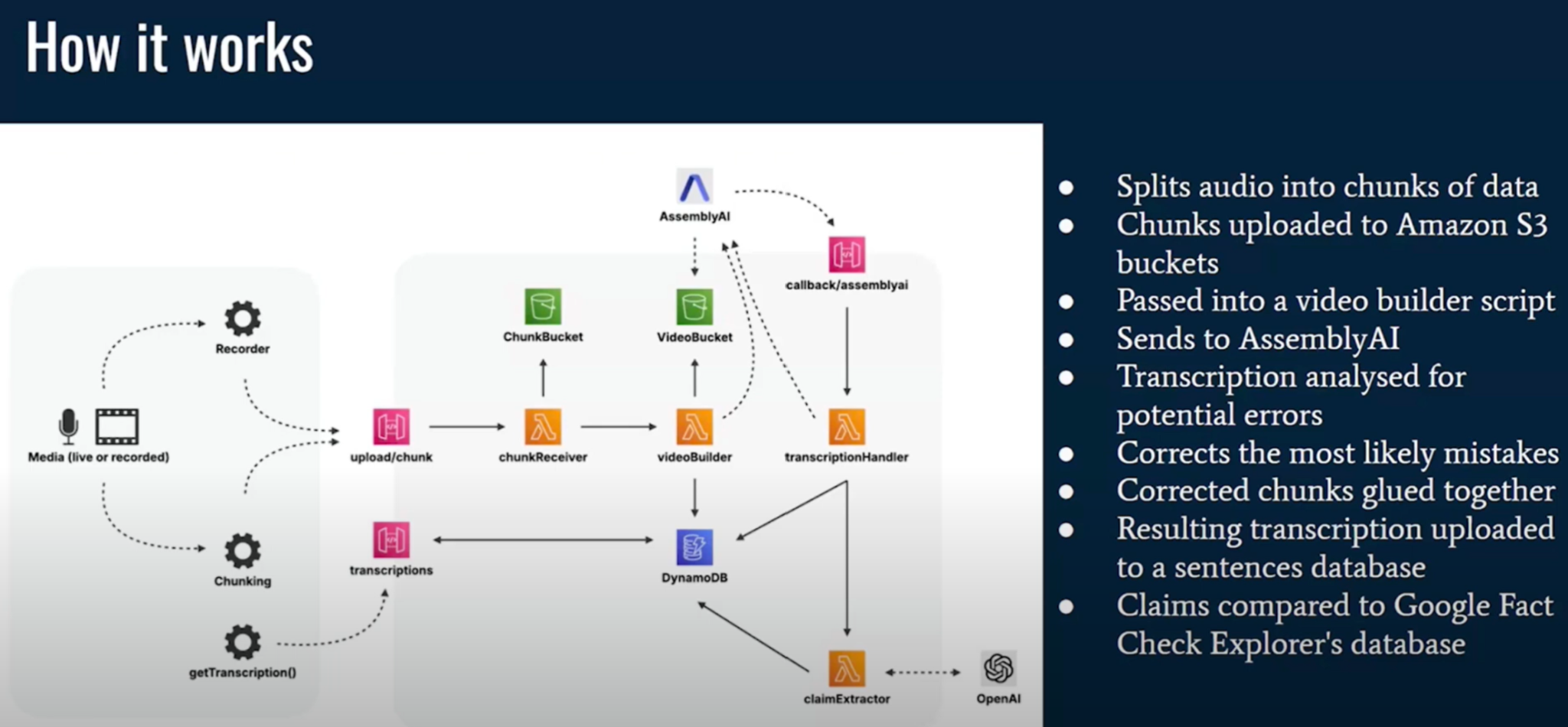
(6:21) То, что вы видите слева на картинке, — это то, что мы видели на переднем плане, (6:25) где все изменения могут быть сделаны в отношении транскрипта или претензий. (6:30) А то, что вы видите справа, — это архитектура бэкэнда. (6:35) Когда фронтэнд отправляет фрагменты в бэкэнд, например, секундные клипы видео, (6:42) они хранятся там и собираются заново.
(6:45) Поэтому всякий раз, когда у нас появляется новая порция в 10 секунд, мы запрашиваем расшифровку этих 10 секунд (6:53) на внешнем сервисе Assembly AI, который вы можете видеть справа вверху. (6:58) Но мне кажется, что сейчас что-то накладывается на общий экран. (7:02) Да, что-то не так.
(7:04) Нет, мы это видим. Идеально. (7:06) И что делает ИИ Ассамблеи, так это расшифровывает эти 10 секунд и отправляет нам обратно.
(7:12) И вы можете представить, что если у вас есть только временные метки, например, (7:16) что вы хотите расшифровать видеофайл с 40-й по 50-ю секунду, (7:22) то у вас не будет идеальных предложений, верно? (7:25) У вас будут предложения, которые начинаются в середине предложения или даже в середине одного единственного слова. (7:33) И поэтому обработчик транскрипции, который вы видите справа, должен склеить транскрипты обратно (7:39) и избавиться от всех ошибок, которые были сделаны ИИ Ассамблеи. (7:44) Затем мы сохраняем предложения в нашей базе данных.
(7:48) И вот тут происходит волшебство, или генеративный ИИ вступает в игру. (7:52) Затем мы берем отдельные предложения, отправляем их в OpenAI (7:59) и запрашиваем фактические утверждения, которые были сделаны в этом предложении. (8:04) Так, например, если Дональд Трамп скажет: «Позвольте мне сказать вам, что в Спрингфилде едят собак и кошек», (8:10) OpenAI вернется с ответом и скажет, что фактическая часть предложения была (8:15) «В Спрингфилде едят собак и кошек».
(8:18) Мы сохраним это утверждение в нашей базе данных вместе с предложением и будем искать похожие утверждения в нашей собственной базе данных, (8:26) а также во внешних базах данных, в данном случае в Google Fact Check Explorer, (8:31) где мы можем просто найти другие новостные статьи или статьи с проверкой фактов об этом утверждении. (8:37) А затем мы можем отправить всю эту кучу обратно с помощью транскрипции (8:43) и снова направить из нашего бэкэнда в наш фронтэнд. (8:47) Во время разработки Checkmate нам пришлось преодолеть некоторые препятствия.

(8:54) Так, например, время от времени было трудно оценить необходимое количество времени для выполнения той или иной задачи. (9:02) Мы часто недооценивали, насколько большими могут быть задачи. (9:06) А иногда у нас были блокирующие факторы.
(9:08) Например, у нас был один баг с Assembly AI, и мы всю дорогу думали: ладно, это должно быть на нашей стороне. (9:14) Но в итоге выяснилось, что это была ошибка на стороне Assembly AI. (9:18) И когда мы связались с разработчиками Assembly AI, (9:21) они были очень рады, что мы обратились к ним и рассказали, что у них была ошибка (9:25), когда дело доходило до расшифровки коротких видео и аудио.
(9:31) Тогда нам пришлось немного сузить область применения. (9:36) И по другим причинам мы решили не транскрибировать живое видео или настоящее живое видео, как мы называем это здесь на слайде. (9:44) Это означает, что транскрипт поступает в тот момент, когда говорит спикер или поступает видео.
(9:51) Сейчас у нас есть задержка примерно в 30 секунд между выступлением спикера и появлением транскрипции. (9:58) Это связано, например, с тем, что мы хотим сделать сервис Assembly AI взаимозаменяемым. (10:05) Так что если вы решите использовать другой сервис, который не умеет транскрибировать на лету, то вы сможете использовать и его.
(10:14) И вы можете себе представить, что баланс редакционных и технических задач в ходе проекта сильно смещался туда-сюда. (10:22) Так, например, в начале нам приходилось много заниматься организационными вопросами. (10:26) В середине было много технической работы.
И в конце, да, у нас просто было много работы. (10:32) И мы были немного ограничены в технических возможностях команды. (10:36) Поэтому мы обратились к нашим редакциям, и они нам помогли.
(10:39) А ограничение ресурсов привело к тому, что нам пришлось отказаться от некоторых функций в доказательстве концепции. (10:45) Например, мы хотели разделить дикторов или даже обнаружить дикторов, чтобы инструмент сказал вам: (10:52) Хорошо, это сказал Дональд Трамп, но это, возможно, другой стипендиат. (10:59)
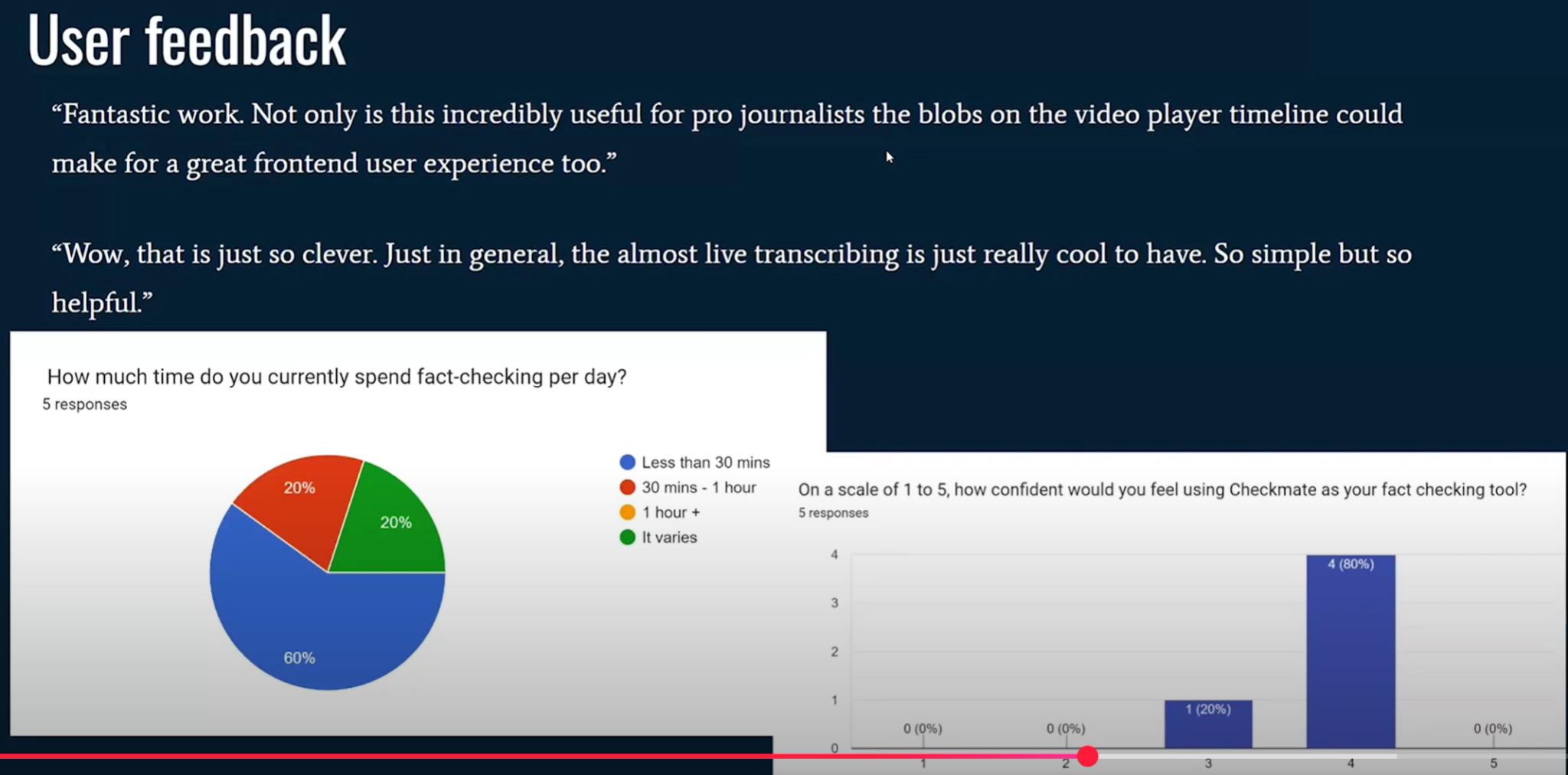
Итак, создав доказательство концепции, мы провели небольшое количество первоначальных отзывов пользователей, (11:04) и на данный момент они были в подавляющем большинстве положительными от людей в новостном отделе, которые активно решили использовать его.
(11:11) Большинство из них заявили, что будут рады использовать такой инструмент, как Checkmate, в своей будущей работе. (11:18) Однако, поскольку они журналисты и любят задавать вопросы, они также прислали список пожеланий к будущим функциям. (11:26) Они подсказали нам, куда мы можем направить Checkmate в будущем.
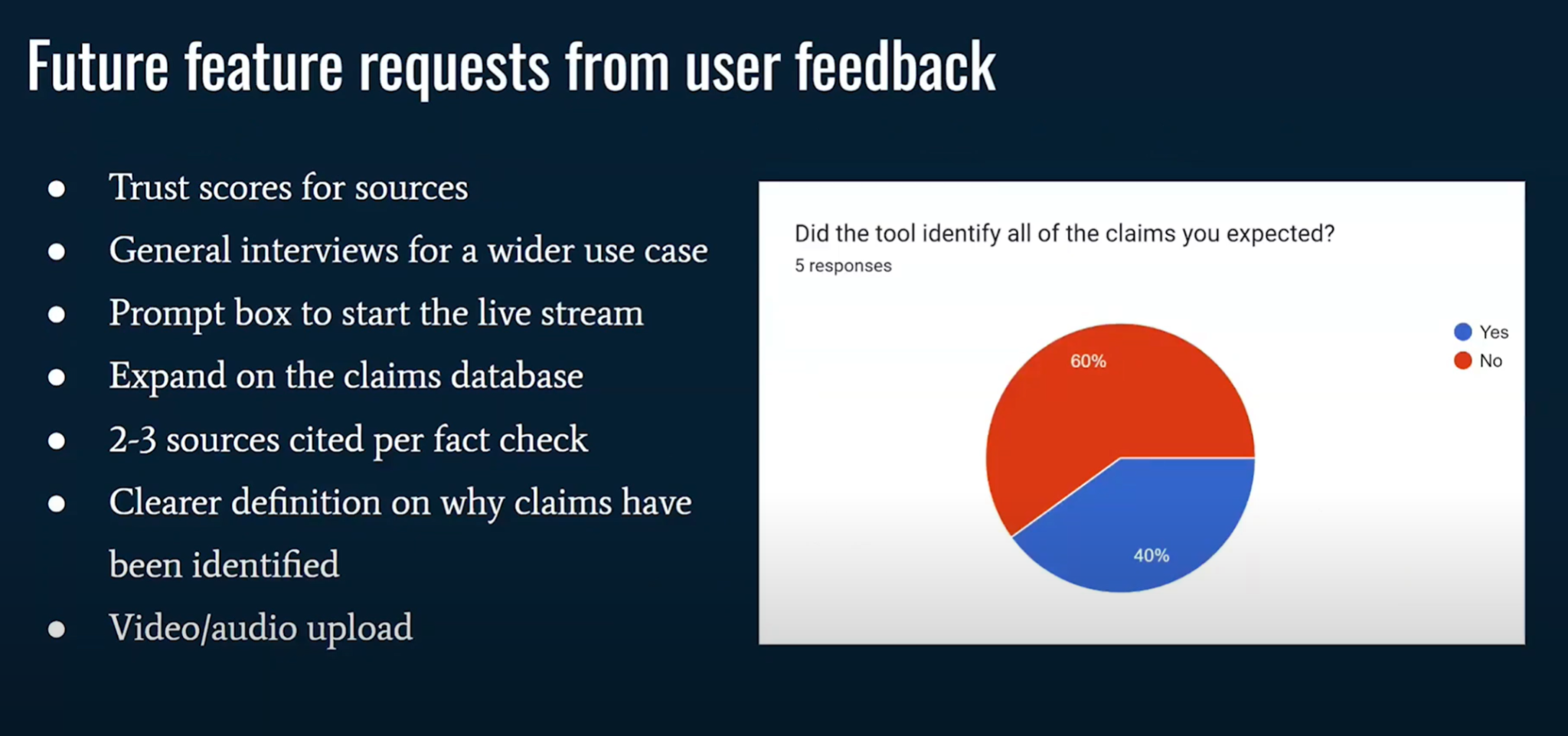
(11:31) Некоторые из них включают в себя расширение нашей базы данных претензий. Это позволит нам ссылаться на большее количество источников. (11:38) В идеале журналисты запрашивают от двух до трех источников для каждой проверки фактов, в то время как мы сейчас предоставляем от одного до двух.
(11:44) А также любопытство, если они захотят узнать, почему те или иные утверждения выявляются в рамках этого процесса. (11:54) Итак, если говорить о будущем Checkmate, то следующая цель — довести его до совершенства. (11:59)

Мы хотим расширить набор функций и возможностей и начать встраивать некоторые из тех функций, о которых просили журналисты.
(12:05) Но также и некоторые из тех, которые выходили за рамки этого проекта. (12:08) У DPA и всех редакций есть желание продолжить этот проект и превратить Checkmate из ранней пробы концепции в надежный инструмент для редакций. (12:22) Вот команда, которая собрала Checkmate вместе.

К счастью для всех, я не был техническим специалистом, но это был большой совместный проект наших редакций. (12:31) Для тех, кому интересно, вы можете отсканировать QR-код и получить доступ к нашему GitHub, где есть немного больше подробностей. (12:40) Большое спасибо.
(12:43) Потрясающе. Спасибо, Надин, и спасибо, Арне, за вашу отличную презентацию и за то, что рассказали нам о работе этого инструмента. (12:50) Если у вас есть вопросы к команде, пожалуйста, задайте их в поле для вопросов и ответов.
(12:55) Прямо сейчас есть два вопроса. Итак, мы переходим к первому вопросу Хенрика: какие источники он использует и обходит ли он протокол исключения роботов? (13:06) Если да, то как? (13:08) Я не совсем понимаю, что вы имеете в виду, говоря о протоколе исключения роботов, но, кажется, я знаю. (13:14) Но, пожалуйста, поправьте меня, если я ошибаюсь.
Итак, сначала позвольте мне ответить на вопрос об источниках. (13:18) У нас есть источники, в основном наши собственные статьи для проверки фактов, но мы также подключили Google Fact Check Explorer, чтобы мы могли передавать утверждения через API в Google и запрашивать аналогичные проверки фактов. (13:33) И я не совсем уверен, считаете ли вы, что наш инструмент не требует, я полагаю, протокола исключения роботов, поскольку мы используем видео и аудио с определенной вкладки и транскрибируем их.
(13:49) И да, для всей той магии, которую вы только что видели в видео или презентации. (13:54) Надеюсь, это ответ на вопрос. (13:55) Спасибо, Армин.
И Хенрик, если у вас есть еще вопросы, вы можете просто начать добавлять их в поле вопросов и ответов. (14:03) Варда хочет знать, проверяет ли ваша команда ИИ-инструментов подлинность видео, например, является ли оно правильным и действительным или нет? (14:12) Нет, он просто транскрибирует сказанное и помогает редакторам выявлять претензии, которые были сделаны. (14:19) Это не полностью автоматический инструмент, так что он просто поможет вам с проверкой фактов и не заменит редакторов в какой-то момент.
(14:31) Да, я думаю, вы уже ответили на этот вопрос, и он вроде как не требует пояснений, но я все равно спрошу. Арлин хочет знать, есть ли на данный момент реальные истории, созданные Checkmate? (14:41) Мы провели много исследований, и у нас есть некоторые части или некоторый интерес в наших отделах новостей. (14:49) Например, в нашем отделе новостей в DPA было много мыслей о том, как использовать его, не только в отделе проверки фактов DPA, но и в других.
(15:01) И да, особенно команда по проверке фактов использует его, может быть, не ежедневно, но использует. (15:08) Великолепно. И последний вопрос: вы оценили стоимость использования части инструмента OpenAI? Кажется, что подсказок много.
(15:17) Это не так много, как мы думали, потому что, особенно когда дело доходит до отправки всех предложений в OpenAI и обеспечения некоторого контекста, мы отправляем не только само предложение, но и четыре предыдущих предложения. (15:32) Мы думали, что это будет очень дорого, но в итоге оказалось, что это не так. За всю стипендию, я думаю, это стоило меньше 100 долларов за полгода.
(15:48) Спасибо, Надин. Спасибо, Арне, за прекрасную презентацию.







