В нынешнюю цифровую эпоху быстрое распространение дезинформации на онлайн-платформах представляет собой существенные проблемы для общественного благополучия, общественного доверия и демократических процессов, влияя на принятие критических решений и общественное мнение.
Для решения этих проблем растет потребность в автоматизированных механизмах обнаружения фейковых новостей. Предварительно обученные большие языковые модели (LLM) продемонстрировали исключительные возможности в различных задачах обработки естественного языка (NLP), побуждая к исследованию их потенциала для проверки новостных заявлений. Вместо того чтобы использовать LLM неагентным способом, когда LLM генерируют ответы на основе прямых подсказок за один раз, наша работа представляет FactAgent, агентский подход использования LLM для обнаружения фейковых новостей. FactAgent позволяет LLM имитировать поведение человека-эксперта при проверке новостных заявлений без какого-либо обучения модели, следуя структурированному рабочему процессу. Этот рабочий процесс разбивает сложную задачу проверки достоверности новостей на несколько подэтапов, где LLM выполняют простые задачи, используя свои внутренние знания или внешние инструменты. На последнем этапе рабочего процесса LLM интегрируют все результаты на протяжении всего рабочего процесса, чтобы определить правдивость новостного утверждения. По сравнению с ручной проверкой человеком FactAgent обеспечивает повышенную эффективность. Экспериментальные исследования демонстрируют эффективность FactAgent в проверке утверждений без необходимости какого-либо процесса обучения. Более того, FactAgent предоставляет прозрачные объяснения на каждом этапе рабочего процесса и во время принятия окончательного решения, предлагая конечным пользователям понимание процесса обоснования обнаружения фейковых новостей. FactAgent обладает высокой степенью адаптации, что позволяет выполнять простые обновления его инструментов, которые LLM могут использовать в рабочем процессе, а также обновления самого рабочего процесса с использованием знаний предметной области. Эта адаптивность позволяет применять FactAgent для проверки новостей в различных доменах.
- 1. Введение
- 2. Связанная работа
- 3. Методология
- 4. Эксперименты и результаты
- 4.1. Экспериментальная установка
- 5. Экспериментальные результаты
- 5.1. Эффективность обнаружения фейковых новостей (RQ1)
- 5.2. Важность знания предметной области (RQ2)
- 5.3. Важность внешней поисковой системы (RQ3)
- 5.4. Исследование абляции стратегии принятия решений (RQ4)
- 6. Исследование случая
- 7. Заключение
- Ссылки
1.Введение
Всепроникающая природа социальных сетей и онлайн-платформ в современную цифровую эпоху усугубила распространение фейковых новостей, характеризующихся ложной или вводящей в заблуждение информацией, замаскированной под достоверные новости. Распространение фейковых новостей создает критические проблемы для общественного благополучия, общественного доверия и демократических процессов (Allcott and Gentzkow,2017) , обладающие потенциалом вызывать страх, влиять на общественное мнение и принятие важных решений (Наим и Бхатти,2020) . Чтобы смягчить последствия распространения фейковых новостей, крайне важно выявлять фейковые новости, особенно на ранних стадиях, прежде чем они широко распространятся на социальных платформах.
В то время как сайты проверки фактов, такие как PolitiFact и Snopes, нанимают профессионалов для ручной проверки фактов, 1 быстрый темп распространения дезинформации в цифровую эпоху делает трудоемкие ручные усилия отнимающими много времени и немасштабируемыми (Грейвс и Амазин,2019) . Поэтому автоматизированные решения имеют важное значение, и в последние годы были разработаны модели на основе глубоких нейронных сетей для проверки фактов (Попат и др . ,2018; Ляо и др . ,2023) . Обнаружение фейковых новостей — это многогранная задача, которая подразумевает оценку таких аспектов, как подлинность, намерение автора и стиль письма. Можно использовать различные точки зрения, например, подход, основанный на знаниях, который сравнивает текстовую информацию из новостных статей с фактическим графом знаний, подход, основанный на стиле, который изучает различия в стиле письма между фейковыми и настоящими новостями, и перспектива достоверности, которая изучает отношения между новостными статьями и такими организациями, как издатели (Zhou et al . ,2019) . Кроме того, методы, основанные на распространении, используют информацию, предоставленную в новостях (Чжоу и др . ,2019) . Существующие контролируемые подходы к обучению для обнаружения фейковых новостей продемонстрировали эффективность в выявлении дезинформации. Однако эти модели часто требуют для обучения аннотированных человеком данных. Это требование может создавать проблемы, поскольку аннотированные наборы данных не всегда могут быть легкодоступны или их сбор на практике может быть дорогостоящим.
LLM продемонстрировали впечатляющие результаты в различных задачах обработки естественного языка (Brown et al . ,2020; Цинь и др . ,2023) , мотивируя нас исследовать их потенциал в обнаружении фейковых новостей. Процесс проверки фактов для профессионалов часто включает сбор информации из нескольких, иногда противоречивых источников в связное повествование (Грейвс и Амазин,2019) , подчеркивая важность проверки данных перед публикацией. В этой работе мы представляем FactAgent, инновационный агентный подход, который использует LLM для обнаружения фейковых новостей. Различие между использованием LLM агентским и неагентским способом заключается в его рабочем режиме: при неагентском подходе LLM отвечает на подсказки или учится в контексте для генерации ответов. Напротив, FactAgent интегрирует LLM в свой процесс принятия решений, разбивая сложные проблемы на управляемые подшаги в рамках структурированного рабочего процесса, используя не только внутренние знания LLM, но и внешние инструменты для завершения каждого компонента и совместного решения общей задачи. Наши основные вклады можно резюмировать следующим образом:
- •
Мы предлагаем FactAgent, агентный подход, который использует LLM для проверки фактов и обнаружения фейковых новостей. FactAgent эмулирует поведение эксперта-человека с помощью структурированного рабочего процесса, где LLM могут интегрировать как внутренние знания, так и внешние инструменты для проверки новостей на всех этапах рабочего процесса. В отличие от экспертов-людей, FactAgent достигает повышенной эффективности, и в отличие от контролируемых моделей, он работает без необходимости в аннотированных данных для обучения. Более того, FactAgent легко адаптируется, что позволяет легко вносить изменения в различные новостные домены путем настройки инструментов в рабочем процессе.
- •
FactAgent способен выявлять потенциальные фейковые новости на ранних этапах процесса их распространения, не полагаясь на информацию социального контекста. Он предоставляет явное обоснование подлинности новостей на каждом этапе рабочего процесса, улучшая интерпретируемость и облегчая понимание пользователем.
- •
Мы проводим эксперименты на трех реальных наборах данных, демонстрируя эффективность FactAgent в достижении высокой производительности. Мы сравниваем производительность FactAgent после структурированного экспертного рабочего процесса и автоматически самостоятельно разработанного рабочего процесса. Наши эксперименты подчеркивают критическую роль экспертного проектирования рабочего процесса на основе знания предметной области для FactAgent.
2.Связанная работа
Обнаружение фейковых новостей Существующие подходы к обнаружению фейковых новостей, которые не используют социальный контекст, можно разделить на две основные группы: основанные на содержании и основанные на доказательствах. Подходы, основанные на содержании, больше фокусируются на текстовом шаблоне внутри самих новостных статей, включая стиль написания и позицию статьи (Popat et al . ,2016) . Эти подходы могут использовать методы НЛП для анализа (Пшибыла,2020) такой, что LSTM (Хохрайтер и Шмидхубер,1997) и BERT (Девлин и др . ,2018) . Подходы, основанные на доказательствах, проверяют достоверность новостей, исследуя семантическое сходство или конфликты в парах утверждение-доказательство, часто извлекая доказательства из графов знаний или веб-сайтов. Например, Попат и др. (Popat et al . ,2018) представили DeClarE, используя BiLSTM и сеть внимания для моделирования семантических отношений утверждения-доказательства. Сюй и др. (Сюй и др . ,2022) разработали GET, унифицированную графовую модель для фиксации семантической зависимости на больших расстояниях. Ляо и др. (Ляо и др . ,2023) представил MUSER, многоступенчатую структуру улучшения поиска доказательств для обнаружения фейковых новостей. С недавним развитием LLM исследователи изучили, могут ли LLM эффективно обнаруживать фейковые новости, используя внутренние знания. Например, Вэй и др. (Wei et al . ,2022) исследовали свой потенциал, используя такие методы, как подсказка zero-shot, подсказка zero-shot Chain-of-Thought (CoT), подсказка few-shot и few-shot CoT. Они также использовали сгенерированные LLM обоснования для повышения производительности контролируемой модели, такой как BERT, в задачах обнаружения фейковых новостей.
Однако вышеупомянутые подходы по-прежнему требуют аннотированных данных для обучения модели, что ограничивает их способность обрабатывать новости, требующие знаний, отсутствующих в обучающих данных. Напротив, наш предлагаемый FactAgent устраняет необходимость в обучении модели, интегрируя семантическое понимание LLM с внешней поисковой системой для поиска доказательств. Чжан и др. (Чжан и Гао,2023) предложил HiSS, иерархический пошаговый подход к подсказкам, который объединяет LLM для разложения новостного заявления на подзаявления и использует внешнюю поисковую систему для ответа на запросы, когда LLM не уверены. В отличие от HiSS, который использует LLM неагентским образом, наш предложенный FactAgent использует LLM агентским образом, позволяя LLM строго следовать рабочему процессу для сбора доказательств на каждом подэтапе процесса. FactAgent использует как внутренние знания LLM, так и внешние поисковые системы для проверки достоверности новостного заявления.
Агент LLM Развитие LLM привело к созданию агентов LLM с разнообразными приложениями в различных областях. Например, Part et al. (Park et al . ,2023) разработали среду-песочницу, в которой виртуальные сущности наделены описаниями персонажей и системами памяти для имитации человеческого поведения. Лян и др. (Лян и др . ,2023) исследовали многоагентную структуру дебатов, демонстрируя возможности совместного решения проблем агентами LLM. Подходы на основе LLM предлагают несколько преимуществ, включая возможность предоставлять обоснования на основе эмоций, содержания, текстовых описаний, здравого смысла и фактической информации. Используя эти преимущества, FactAgent предназначен для интерпретации разнообразных подсказок и реальных контекстов для обнаружения фейковых новостей. В отличие от существующих подходов, которые позволяют LLM автономно разрабатывать собственные планы решения проблем (Ge et al . ,2024) FactAgent позволяет магистрам права придерживаться структурированного рабочего процесса, имитируя работу людей-проверяющих факты, чтобы выполнить задачу по обнаружению фейковых новостей, используя внутренние знания магистра права и внешние инструменты.
3.Методология
В то время как FactAgent предназначен для использования LLM агентским способом, имитируя поведение эксперта-человека для проверки фактов путем разложения задач на несколько подэтапов в рабочем процессе и сбора доказательств с различных точек зрения с использованием как внутренних знаний LLM, так и внешних инструментов, наша основная методология или фокус заключается в том, чтобы позволить LLM следовать структурированному экспертному рабочему процессу, разработанному с использованием знаний предметной области таким агентским способом.
Учитывая многогранный характер обнаружения фейковых новостей и необходимость детального понимания разнообразных подсказок и реального контекста, такого как стиль письма и здравый смысл (Чжоу и др . ,2019) в сочетании с сильными способностями понимания текста у LLM и возможностью возникновения галлюцинаций (Li et al . ,2023) мы классифицируем инструменты, разработанные для LLM, которые можно использовать в структурированном экспертном рабочем процессе, на две группы: одна группа использует только внутренние знания LLM (т. е. инструменты Phrase, Language, Commonsense, Standing), а другая интегрирует внешние знания (т. е. инструменты URL и Search). Каждый инструмент разработан с учетом конкретных предположений о фейковых новостях, как описано ниже.
Phrase_tool : Этот инструмент предназначен для проверки новостных заявлений путем проверки наличия сенсационных тизеров, провокационного или эмоционально заряженного языка или преувеличенных заявлений. Он работает на основе предположения, что фейковые новости часто используют эти приемы для привлечения внимания читателей.
Language_tool : Этот инструмент предназначен для выявления грамматических ошибок, ошибок в формулировках, неправильного использования кавычек или слов, написанных заглавными буквами в новостных заявлениях. Он предполагает, что фейковые новости часто включают такие ошибки, чтобы подчеркнуть достоверность или привлечь читателей.
Commonsense_tool : Этот инструмент использует внутренние знания LLM для оценки обоснованности новостных заявлений и выявления любых противоречий со здравым смыслом. Он работает на основе предположения, что фейковые новости могут напоминать сплетни, а не фактическую информацию, и могут содержать элементы, противоречащие общепринятым знаниям.
Standing_tool : Этот инструмент специально создан для новостей, имеющих отношение к политике, и направлен на то, чтобы определить, продвигают ли новости определенную точку зрения, а не представляют ли они объективные факты. Он работает на основе предположения, что фейковые политические новости часто усиливают существующие убеждения или предубеждения целевой аудитории. Кроме того, он может способствовать поляризации, изображая политических оппонентов в негативном свете или демонизируя определенные группы.
Search_tool : Этот инструмент использует SerpApi для поиска любой противоречивой информации, сообщаемой другими медиаресурсами. 2 Он предполагает, что фейковые новости часто содержат неподтвержденную информацию с небольшим количеством доказательств в поддержку заявлений. Использование Serpapi API также может смягчить проблему галлюцинаций LLM, используя внешние знания для перекрестных ссылок и проверки новостного заявления.
URL_tool : Этот инструмент объединяет внутренние и внешние знания LLM для оценки того, исходит ли новостное утверждение из URL-адреса домена, которому не хватает достоверности. Сначала он использует внутренние знания LLM для получения обзора URL-адреса домена. Затем он использует внешние знания, такие как прошлый опыт, хранящийся в базе данных, содержащей URL-адреса, проверенные на наличие реальных и фейковых новостей, для улучшения понимания URL-адреса домена. Предположение, лежащее в основе этого инструмента, заключается в том, что фейковые новости часто исходят из доменов, которые не заслуживают доверия. Внешняя база данных знаний может обновляться всякий раз, когда проверяется новостная статья, что обеспечивает ее своевременную точность и надежность.
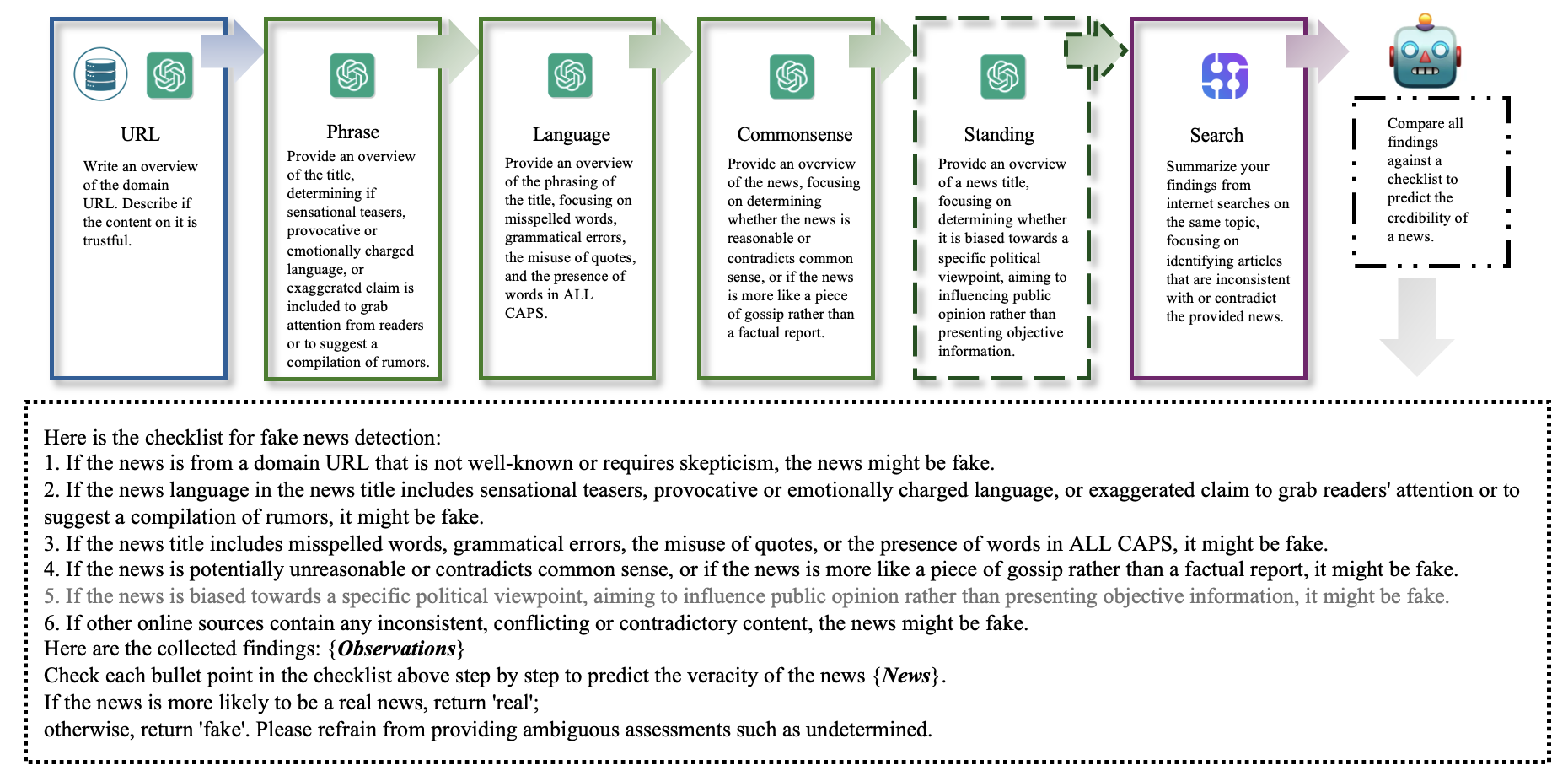
Рисунок 1 изображает структурированный экспертный рабочий процесс, который использует вышеупомянутые инструменты шаг за шагом для сбора доказательств для проверки новостного заявления. Получив новостное заявление, FactAgent сначала позволяет LLM использовать свои контекстные возможности для определения того, касается ли статья политики. Если это так, то новостное заявление будет проанализировано с использованием всех предоставленных инструментов в структурированном экспертном рабочем процессе; в противном случае Standing_tool будет пропущен. На последнем этапе все доказательства собираются и сравниваются с экспертным контрольным списком для обобщения и прогнозирования правдивости новостного заявления.
4.Эксперименты и результаты
Мы проводим экспериментальные исследования, чтобы ответить на следующие исследовательские вопросы:
- •
RQ1: Как работает FactAgent со структурированным экспертным рабочим процессом по сравнению с другими базовыми показателями обнаружения фейковых новостей?
- •
RQ2: Как знание предметной области влияет на эффективность FactAgent при обнаружении фейковых новостей?
- •
RQ3: Какое влияние оказывает внешняя поисковая система на эффективность FactAgent?
- •
RQ4: Как стратегия принятия решений влияет на эффективность FactAgent?
4.1.Экспериментальная установка
Набор данных Мы оцениваем производительность FactAgent, используя структурированный экспертный рабочий процесс с тремя англоязычными наборами данных: Snopes (Popat et al . ,2017) , PolitiFact и GossipCop (Шу и др . ,2020) . PolitiFact и GossipCop выбраны потому, что они не только предоставляют заголовки новостей, но и исходные URL-адреса для каждого новостного утверждения. Учитывая, что один инструмент в экспертном рабочем процессе ищет соответствующие статьи в Интернете и выявляет противоречивые отчеты, мы гарантируем, что исходные URL-адреса источников выборочных тестовых данных содержат даты их публикации. Эта информация используется для установки ограничений для SerpAPI, чтобы избежать проблемы утечки онлайн-данных, при которой события, происходящие на текущем временном шаге, ошибочно включаются в результаты поиска, даже если они еще не произошли на момент публикации статьи. Для набора данных Snopes, где исходные URL-адреса недоступны для новостных утверждений, мы демонстрируем гибкость FactAgent, настраивая инструменты, используемые в экспертном рабочем процессе, на основе доступной информации. Мы случайным образом выбираем 100 новостных статей из каждого набора данных для оценки, гарантируя, что соотношение реальных новостей к фейковым новостям в тестовых данных составляет менее 1:2.
Базовые показатели Чтобы проверить эффективность FactAgent с использованием структурированного экспертного рабочего процесса, мы сравниваем его со следующими методами:
- •
LSTM (Хохрайтер и Шмидхубер,1997) : Применяет LSTM для кодирования текстовой информации из новостных заявлений.
- •
ТекстCNN (Ким,2014) : использует CNN для сбора локальных закономерностей и представлений новостных заявлений.
- •
BERT (Девлин и др . ,2018) : реализует архитектуру преобразователя для фиксации контекстных связей и понимания новостных утверждений.
- •
HiSS (Чжан и Гао,2023) : представляет иерархический метод подсказок, который предписывает магистрам права разбивать утверждения на подутверждения и проверяет их с помощью этапов вопросов и ответов, используя поисковую систему для получения внешней информации.
- •
Стандартная подсказка Zero-shot: использует подсказку, содержащую только описание задачи и предоставленное новостное утверждение.
- •
Zero-shot CoT: Применяет CoT (Wei et al . ,2022) побуждающий подход к нулевому выводу.
- •
Zero-shot (инструмент): использует индивидуально разработанные инструменты, упомянутые в разделе 3 , за исключением Standing_tool, поскольку не все новости касаются политики.
Подробности реализации Мы используем фреймворк LangChain и модель gpt-3.5-turbo в качестве базовой LLM для всех инструментов, используемых в аналитической машине. 3 Параметр температуры установлен на 0, чтобы обеспечить воспроизводимость. Каждая статья представлена с использованием ее заголовка, URL-адреса домена и даты публикации для наборов данных PolitiFact и GossipCop. Для набора данных Snopes используется только информация о заголовке из-за отсутствия URL-адресов. Другие базовые данные в нашем сравнении использовали только заголовок новости для анализа. Статистика базовых данных обучения обобщена в Таблице 1 .
Для базового уровня HiSS (Чжан и Гао,2023) мы напрямую используем ту же подсказку, которую предоставили исследователи, с той разницей, что метки «полуправда», «едва ли правда» и «ложь» группируются вместе как «ложь», а метки «полуправда», «в основном правда» и «верно» группируются как «верно» в соответствии с Рашкиным и др. (Рашкин и др . ,2017) .
Чтобы обеспечить справедливое сравнение LLM, использующих индивидуально разработанные инструменты и FactAgent, следуя разработанному экспертному рабочему процессу, мы сохраняем результаты анализа на каждом этапе каждого инструмента в течение всего рабочего процесса, а затем применяем один и тот же пункт для каждого инструмента в методологии рисунка 1, чтобы получить окончательные результаты достоверности прогноза для LLM, используя каждый инструмент с нулевой отметкой.
Для оценки эффективности мы используем различные показатели, включая точность, оценку F1, а также оценки F1 специально для классификации реальных и фейковых новостей, чтобы получить комплексную оценку эффективности модели в обнаружении фейковых новостей.
| GossipCop | PolitiFact | Сноупс | |
|---|---|---|---|
| #Настоящие новости | 3586 | 456 | 1050 |
| #Фейковые новости | 2884 | 327 | 1500 |
5.Экспериментальные результаты
5.1.Эффективность обнаружения фейковых новостей (RQ1)
Сравнение производительности различных моделей приведено в Таблице 2. Наши наблюдения показывают, что FactAgent, следуя экспертному рабочему процессу, достигает превосходной производительности по сравнению с другими базовыми моделями на всех наборах данных.
В отличие от контролируемых базовых линий, которые неявно изучают контекстные шаблоны или стили написания фейковых новостей из помеченных данных, разработанные инструменты явно используют внутренние знания LLM и возможности контекстного понимания для оценки конкретного существования общих фраз или стилей языка, указывающих на фейковые новостные заявления. FactAgent также извлекает выгоду из внешних инструментов, которые расширяют возможности LLM за пределы того, чего могут достичь контролируемые базовые линии. Например, FactAgent позволяет LLM искать связанные новостные заявления в Интернете и обнаруживать противоречивые отчеты, используя внешние источники для повышения оценки их достоверности. Кроме того, FactAgent позволяет LLM проверять достоверность доменных URL-адресов, используя как внутренние знания доменных URL-адресов, так и внешние базы данных, содержащие последние доменные URL-адреса, связанные с проверенными фейковыми новостями. Эти возможности позволяют FactAgent со структурированным экспертным рабочим процессом иметь улучшенные характеристики без необходимости обучения модели и процессов настройки гиперпараметров, обычно связанных с контролируемыми моделями обучения.
Сравнивая результаты LLM, использующих различные методы подсказок (например, стандартные подсказки, подсказки CoT), или принимая решения на основе результатов каждого разработанного инструмента, мы видим, что LLM, использующие подсказки CoT, не всегда превосходят стандартные методы подсказок. Это наблюдение согласуется с предыдущими исследованиями (Чжан и Гао,2023) , который также выделил схожие выводы. После анализа ошибок, связанных с подходом CoT, мы также наблюдаем пропуск необходимой мысли, что подтверждает выводы Чжана и др. (Чжан и Гао,2023) . Более низкие показатели стандартного подсказывания и подсказывания CoT по сравнению с LLM, принимающими решения на основе здравого смысла и фразовых наблюдений во всех трех наборах данных, подчеркивают важность явного руководства процессом рассуждения LLM с определенной точки зрения для эффективного использования его возможности текстового понимания. Кроме того, превосходная производительность FactAgent с экспертным рабочим процессом по сравнению с LLM, использующим отдельные инструменты, подчеркивает важность изучения новостного заявления с разных точек зрения.
Наш подход отличается от HiSS, который использует LLM и внешние поисковые системы в первую очередь в качестве метода подсказки. Напротив, FactAgent разлагает проблему обнаружения фейковых новостей на простые задачи, причем каждая задача полагается на LLM для предоставления ответов. Превосходство FactAgent над HiSS объясняется строгим использованием внешних инструментов, интегрированных в структурированный экспертный рабочий процесс, наряду с изучением внутреннего здравого смысла LLM. Напротив, HiSS полагается на внешние поисковые системы только тогда, когда самому LLM не хватает уверенности, чтобы ответить на конкретные вопросы, что потенциально ограничивает его объем и глубину анализа по сравнению с FactAgent.
В целом, превосходная производительность FactAgent по сравнению с базовыми показателями демонстрирует преимущество использования LLM агентским способом для имитации поведения экспертов-людей, тщательного изучения новостного утверждения с разных точек зрения и интеграции внешнего процесса поиска после экспертного рабочего процесса для проверки его достоверности.
| Модель | PolitiFact | GossipCop | Сноупс | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ф1 | В соотв. | F1_реальный | F1_подделка | Ф1 | В соотв. | F1_реальный | F1_подделка | Ф1 | В соотв. | F1_реальный | F1_подделка | |
| LSTM | 0,79 | 0,79 | 0,79 | 0,79 | 0,77 | 0,77 | 0,76 | 0,77 | 0,65 | 0,66 | 0,64 | 0,67 |
| ТекстCNN | 0,80 | 0,80 | 0,79 | 0,82 | 0,79 | 0,79 | 0,78 | 0,79 | 0,62 | 0,64 | 0,55 | 0,69 |
| БЕРТ | 0,85 | 0,85 | 0,85 | 0,85 | 0,79 | 0,79 | 0,78 | 0,80 | 0,63 | 0,63 | 0,59 | 0,67 |
| ХиСС | 0,62 | 0,62 | 0,58 | 0,65 | 0,66 | 0,66 | 0,69 | 0,63 | 0,58 | 0,60 | 0,47 | 0,68 |
| Стандартная подсказка Zero-shot | 0,73 | 0,73 | 0,70 | 0,76 | 0,61 | 0,61 | 0,65 | 0,56 | 0,61 | 0,62 | 0,55 | 0,67 |
| Запрос CoT Zero-shot | 0,64 | 0,63 | 0,56 | 0,69 | 0,64 | 0,64 | 0,63 | 0,65 | 0,59 | 0,63 | 0,46 | 0,72 |
| Инструмент для изучения языка с нуля | 0,73 | 0,72 | 0,77 | 0,67 | 0,53 | 0,48 | 0,64 | 0,32 | 0,60 | 0,62 | 0,53 | 0,68 |
| Инструмент для фраз с нулевой точностью | 0,83 | 0,83 | 0,85 | 0,80 | 0,69 | 0,69 | 0,71 | 0,67 | 0,66 | 0,68 | 0,75 | 0,57 |
| Инструмент нулевого URL-адреса | 0,81 | 0,81 | 0,83 | 0,79 | 0,63 | 0,63 | 0,64 | 0,62 | —— | —— | —— | —— |
| Инструмент поиска Zero-shot | 0,78 | 0,78 | 0,77 | 0,79 | 0,66 | 0,66 | 0,67 | 0,65 | 0,72 | 0,73 | 0,67 | 0,77 |
| Инструмент здравого смысла с нулевым выстрелом | 0,80 | 0,80 | 0,80 | 0,80 | 0,76 | 0,75 | 0,71 | 0,79 | 0,66 | 0,66 | 0,61 | 0,70 |
| FactAgent с экспертным рабочим процессом | 0,88 | 0,88 | 0,89 | 0,88 | 0,83 | 0,83 | 0,83 | 0,83 | 0,75 | 0,75 | 0,75 | 0,75 |
5.2.Важность знания предметной области (RQ2)
В этом подразделе проводятся два эксперимента для оценки важности знаний предметной области при создании экспертного рабочего процесса для FactAgent по проверке достоверности новостных утверждений.
Рабочий процесс эксперта против автоматически разработанного рабочего процесса На рисунке 2 показаны инструкции для LLM по автоматическому созданию самостоятельно разработанного рабочего процесса для проверки новостного заявления с использованием предоставленных инструментов. Затем агент выполняет выбранные инструменты шаг за шагом для сбора результатов, связанных с новостным заявлением. Этот процесс аналогичен рабочему процессу, показанному на рисунке 1. На последнем этапе LLM сравнивает свои результаты с пунктами контрольного списка, соответствующими выбранным инструментам, чтобы определить правдивость новостного заявления.
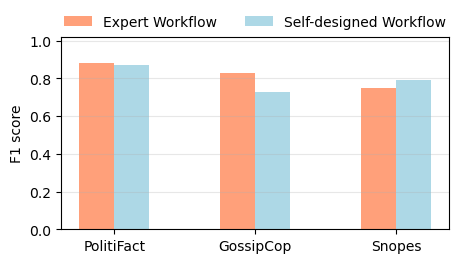
На рисунке 3 сравнивается производительность FactAgent с экспертным рабочим процессом с производительностью автоматически самостоятельно разработанного рабочего процесса. Замечено, что разрешение FactAgent с LLM автоматически разрабатывать свой собственный рабочий процесс для обнаружения фейковых новостей приводит к более низкой производительности по сравнению с указанием агенту придерживаться экспертного рабочего процесса для набора данных GossipCop. Производительность аналогична для набора данных PolitiFact и показывает немного лучшую производительность для набора данных Snopes. Мы далее анализируем соотношение использования инструментов среди тестовых образцов для каждого набора данных, когда LLM разрабатывает свой собственный рабочий процесс на рисунке 4. Из рисунка 4 мы видим, что когда LLM разрабатывает рабочий процесс с использованием предоставленных инструментов, он имеет тенденцию отдавать предпочтение инструментам, которые больше фокусируются на текстовом контенте новостей, при этом игнорируя другие важные факторы, такие как URL-адрес домена, несмотря на наличие URL-адреса домена в описании новости.


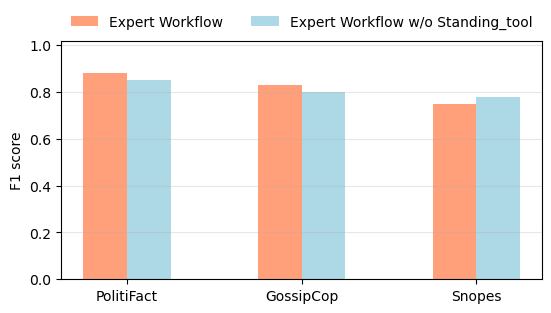
Интеграция Standing_tool для политических новостей Standing_tool специально разработан для проверки новостных заявлений, которые LLM определяет как имеющие отношение к политике. На рисунке 5 мы проводим эксперимент, в котором удаляем Standing_tool из экспертного рабочего процесса, показанного на рисунке 1. В результате все новостные статьи, независимо от их отношения к политике, обрабатываются с использованием оставшихся общих инструментов (за исключением URL_tool для набора данных Snopes). Для наборов данных PolitiFact и GossipCop применяются все оставшиеся инструменты. На рисунке 5 показаны результаты этого эксперимента, которые указывают на снижение производительности для наборов данных PolitiFact и GossipCop и немного более высокую производительность для набора данных Snopes.
Объединяя приведенные выше наблюдения из рисунков 3 , 4 и 5 в контексте данных PolitiFact, мы приходим к выводу, что Standing_tool, который анализирует политические взгляды, имеет большее значение, чем URL_tool. Напротив, для данных GossipCop мы приходим к выводу, что чрезмерное использование Standing_tool и недостаточное использование URL_tool дает худшие результаты по сравнению со сценариями, в которых используется URL_tool, но Standing_tool опускается. Учитывая, что данные GossipCop в основном сосредоточены на развлечениях, сплетнях о знаменитостях и слухах, а не на политике, акцент на обнаружении политической предвзятости с помощью Standing_tool в самостоятельно разработанном рабочем процессе LLM может быть не столь актуален для этого набора данных.
Для набора данных Snopes как использование, так и неиспользование Standing_tool показывают улучшение производительности. Это говорит о том, что определение того, имеют ли новости отношение к политике, менее критично для набора данных Snopes. Внешний Search_tool, по-видимому, играет значительную роль в достижении хорошей производительности из Таблицы 2. Объединение Search_tool с инструментами анализа текстовых шаблонов кажется достаточным для LLM, чтобы суммировать общие результаты при объединении с результатами внешнего поиска.
Эти наблюдения подчеркивают важность структурирования экспертного рабочего процесса, включающего знания предметной области для разработки соответствующих инструментов, специфичных для предметной области набора данных, а не позволяя LLM автоматически разрабатывать свой собственный рабочий процесс для FactAgent. Такой подход гарантирует, что разработанный рабочий процесс будет более адаптирован и подходит для характеристик анализируемой новостной области. Одним из ключевых преимуществ FactAgent является гибкость и простота добавления, удаления или изменения определенных инструментов в рабочем процессе на основе требований, специфичных для предметной области. Эта гибкость позволяет адаптироваться к различным наборам данных и контекстам, повышая эффективность и применимость FactAgent в различных сценариях.
5.3.Важность внешней поисковой системы (RQ3)
Таблица 2 показывает, что опора исключительно на внешние поиски для обнаружения противоречивых сообщений как на средство проверки новостных заявлений не дает оптимальной производительности, особенно для набора данных GossipCop. Этот результат может быть связан с тем фактом, что хотя онлайн-поиск может предоставить доказательства, один и тот же слух или дезинформация могут также сообщаться на нескольких онлайн-ресурсах, что приводит к снижению доверия, а не к четкой проверке.
Несмотря на неоптимальную производительность опоры исключительно на внешние поиски, в этом подразделе оценивается влияние включения внешнего поискового инструмента в экспертный рабочий процесс для FactAgent. Чтобы проверить важность Search_tool, мы исключаем его из экспертного рабочего процесса, оставляя LLM оценивать достоверность исключительно на основе доступных инструментов, которые в первую очередь используют внутренние знания LLM. Рисунок 6 показывает, что производительность ухудшается без Search_tool, что говорит о том, что опора исключительно на внутренние знания LLM недостаточна для эффективного обнаружения фейковых новостей.
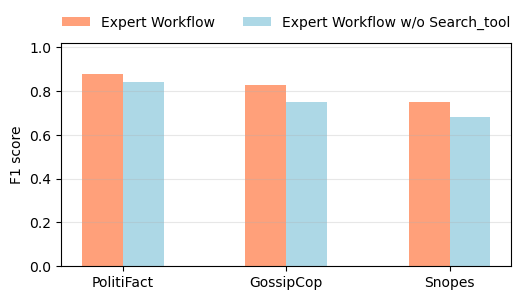
5.4.Исследование абляции стратегии принятия решений (RQ4)
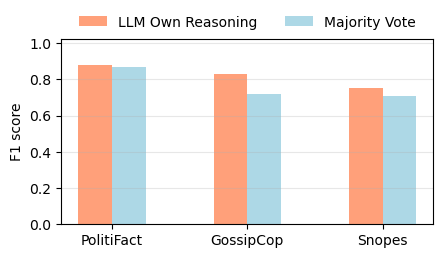
В этом подразделе рассматривается стратегия принятия окончательного решения, используемая LLM на последнем этапе FactAgent с экспертным рабочим процессом. В настоящее время LLM автономно сравнивает собранную информацию из различных инструментов и принимает окончательное решение без предопределенных правил принятия решений, например, полагаясь на прогноз каждого инструмента и используя стратегию большинства голосов.
Чтобы исследовать влияние использования стратегии большинства голосов во время окончательного процесса проверки, мы вручную применяем большинство голосов ко всем решениям инструментов, используемых LLM. Рисунок 7 показывает, что использование большинства голосов приводит к худшей производительности во всех трех наборах данных по сравнению с инструкцией LLM сравнивать с контрольным списком для окончательного прогноза. Это расхождение в производительности подчеркивает, что когда LLM сравнивает наблюдения с контрольным списком на последнем этапе FactAgent, он не слепо полагается на большинство голосов. Вместо этого это предполагает, что предоставление LLM гибкости для суммирования общего прогноза на основе его рассуждений и идей может дать лучшие результаты, чем навязывание жестких правил принятия решений, таких как большинство голосов.
6.Исследование случая
В контексте обнаружения фейковых новостей интерпретация имеет решающее значение для обеспечения ясности и понимания для конечных пользователей. Рисунок 8 иллюстрирует процесс рассуждения LLM на каждом этапе рабочего процесса в FactAgent. LLM выводит явные наблюдения из каждого инструмента на естественном языке и предоставляет рассуждения на последнем этапе, сравнивая каждое наблюдение с соответствующим пунктом контрольного списка, чтобы прийти к выводу. Это контрастирует с обычными контролируемыми моделями, которым может не хватать явной прозрачности в их путях принятия решений. Процесс проверки и рассуждения также может информировать конечных пользователей о том, какие аспекты следует тщательно изучить, чтобы не попасться на удочку фейковых новостей.

7.Заключение
Мотивированная богатыми внутренними знаниями, встроенными в LLM, наша работа предлагает FactAgent, который использует LLM агентским образом для имитации человеческого экспертного поведения при оценке новостных заявлений через структурированный рабочий процесс. Наши результаты показывают, что FactAgent с экспертным рабочим процессом превосходит контролируемые модели обучения, стандартные подсказки, методы подсказок CoT и одноаспектный анализ. Строго интегрируя внешний поиск и здравый смысл LLM в рабочий процесс, FactAgent также превосходит HiSS, который также использует LLM и внешнюю поисковую систему для проверки фактов. Кроме того, наши эксперименты подчеркивают важность использования знаний экспертов в предметной области для проектирования рабочего процесса FactAgent и подчеркивают гибкость изменения рабочего процесса и окончательной стратегии принятия решений.
Преимущества нашего подхода по сравнению с существующими многочисленны. В отличие от моделей контролируемого обучения, которые требуют аннотированных данных для обучения и трудоемкой настройки гиперпараметров, наш метод не требует никакого обучения или настройки. Это делает наш подход высокоэффективным и доступным, устраняя необходимость в обширных вручную маркированных наборах данных. Более того, наши эксперименты показывают, что производительность FactAgent зависит от экспертных знаний в предметной области, используемых для проектирования рабочего процесса. Хотя экспертный рабочий процесс, разработанный в этой работе, может быть неоптимальным, ключевым преимуществом FactAgent является его гибкость при включении новых инструментов в рабочий процесс. Когда эксперты обнаруживают новые индикаторы фейковых новостей в определенной области, они могут легко интегрировать эти знания в инструмент и бесшовно объединить его с существующим рабочим процессом. Затем FactAgent может поручить LLM смоделировать их процесс проверки фактов. Эти преимущества имеют значительные последствия, такие как использование FactAgent с тщательно разработанным рабочим процессом для помощи людям в аннотировании данных для обучения контролируемых моделей для обнаружения фейковых новостей. Кроме того, FactAgent предоставляет четкое обоснование для каждого шага рабочего процесса, повышая интерпретируемость процесса проверки фактов на естественном языке.
Некоторые ограничения в нашей работе указывают на потенциальные направления для будущих исследований. Например, наш подход в настоящее время опирается на заголовки новостей и URL-адреса доменов, если они доступны, но рассмотрение социального контекста, такого как отношения ретвитов, может быть важным для обнаружения фейковых новостей в процессе распространения (Zubiaga et al . ,2018) . Кроме того, включение мультимодального подхода путем анализа элементов веб-дизайна также может улучшить возможности обнаружения фейковых новостей. Более того, некоторые заголовки новостей сами по себе не могут напрямую определять правдивость новостного заявления. Может быть полезно интегрировать полное содержание новостных статей и оценивать, точно ли заголовок отражает содержание или вводит в заблуждение, чтобы привлечь внимание пользователей (т. е. является кликбейтом). Наконец, изучение интеграции экспертных стратегий принятия решений для повышения производительности представляет собой еще одно потенциальное направление для будущего исследования.
Ссылки
- (1)
- Оллкотт и Генцков (2017)Хант Оллкотт и Мэтью Генцков. 2017.Социальные сети и фейковые новости на выборах 2016 года.Журнал экономических перспектив 31, 2 (2017), 211–236.
- Браун и др . (2020)Том Браун, Бенджамин Манн, Ник Райдер, Мелани Суббия, Джаред Д. Каплан, Прафулла Дхаривал, Арвинд Нилакантан, Пранав Шьям, Гириш Састри, Аманда Аскелл и др . 2020.Языковые модели усваиваются с небольшим количеством попыток.Достижения в области нейронных систем обработки информации 33 (2020), 1877–1901.
- Девлин и др . (2018)Джейкоб Девлин, Минг-Вэй Чан, Кентон Ли и Кристина Тутанова. 2018.Берт: Предварительная подготовка глубоких двунаправленных преобразователей для понимания языка.Препринт arXiv arXiv:1810.04805 (2018).
- Ге и др . (2024)Инцян Гэ, Вэньюэ Хуа, Кай Мэй, Цзюньтао Тан, Шуюань Сюй, Цзэлун Ли, Юнфэн Чжан и др . 2024.Openagi: Когда llm встречается с экспертами в предметной области.Достижения в области нейронных систем обработки информации 36 (2024).
- Грейвс и Амазин (2019)Лукас Грейвс и Мишель Амазин. 2019.Фактчекинг как идея и практика в журналистике.(2019).
- Хохрайтер и Шмидхубер (1997)Зепп Хохрайтер и Юрген Шмидхубер. 1997.Длительная кратковременная память.Нейронные вычисления 9, 8 (1997), 1735–1780.
- Ким (2014)Y Ким. 2014.Свёрточные нейронные сети для классификации предложений.В материалах конференции 2014 года по эмпирическим методам обработки естественного языка (EMNLP) (2014), 1746–1751.
- Ли и др . (2023)Цзюньи Ли, Сяосюэ Чэн, Уэйн Синь Чжао, Цзянь-Юнь Не и Цзи-Ронг Вэнь. 2023.Хельма: масштабный тест оценки галлюцинаций для больших языковых моделей.Препринт arXiv arXiv:2305.11747 (2023).
- Лян и др . (2023)Тянь Лян, Чживэй Хэ, Вэньсян Цзяо, Син Ван, Ян Ван, Жуй Ван, Юйцзю Ян, Чжаопэн Ту и Шумин Ши. 2023.Поощрение дивергентного мышления в крупных языковых моделях посредством многоагентных дебатов.Препринт arXiv arXiv:2305.19118 (2023).
- Ляо и др . (2023)Хао Ляо, Цзяхао Пэн, Чжани Хуан, Вэй Чжан, Гуанхуа Ли, Кай Шу и Син Се. 2023.MUSER: Многошаговая структура улучшения поиска доказательств для обнаружения фейковых новостей. В трудах 29-й конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных . 4461–4472.
- Наим и Бхатти (2020)Салман бин Наим и Рубина Бхатти. 2020.«Инфодемия» COVID-19: новый фронт для специалистов в области информации.Журнал медицинской информации и библиотек 37, 3 (2020), 233–239.
- Парк и др . (2023)Джун Сон Пак, Джозеф О’Брайен, Кэрри Джун Кай, Мередит Рингель Моррис, Перси Лян и Майкл С. Бернстайн. 2023.Генеративные агенты: Интерактивные симулякры человеческого поведения. В трудах 36-го ежегодного симпозиума ACM по программному обеспечению и технологиям пользовательского интерфейса . 1–22.
- Попат и др . (2016)Кашьяп Попат, Субхабрата Мукерджи, Янник Стрётген и Герхард Вейкум. 2016.Оценка достоверности текстовых заявлений в Интернете. В трудах 25-й международной конференции ACM по управлению информацией и знаниями . 2173–2178.
- Попат и др . (2017)Кашьяп Попат, Субхабрата Мукерджи, Янник Стрётген и Герхард Вейкум. 2017.Где кроется правда: объяснение достоверности новых заявлений в Интернете и социальных сетях. В трудах 26-й Международной конференции по World Wide Web Companion . 1003–1012.
- Попат и др . (2018)Кашьяп Попат, Субхабрата Мукерджи, Эндрю Йейтс и Герхард Вейкум. 2018.Declare: Разоблачение фейковых новостей и ложных утверждений с использованием глубокого обучения на основе фактических данных.Препринт arXiv arXiv:1809.06416 (2018).
- Прибыла (2020)Пётр Пшибила. 2020.Улавливая стиль фейковых новостей. В трудах конференции AAAI по искусственному интеллекту , том 34. 490–497.
- Цинь и др . (2023)Чэнвэй Цинь, Астон Чжан, Чжуошэн Чжан, Цзяао Чен, Мичихиро Ясунага и Дийи Ян. 2023.Является ли chatgpt универсальным средством решения задач обработки естественного языка?Препринт arXiv arXiv:2302.06476 (2023).
- Рашкин и др . (2017)Ханна Рашкина, Ынсол Чой, Джин Йе Чан, Светлана Волкова и Еджин Чой. 2017.Правда разных оттенков: анализ языка в фейковых новостях и политическая проверка фактов. В трудах конференции 2017 года по эмпирическим методам обработки естественного языка . 2931–2937.
- Шу и др . (2020)Кай Шу, Дипак Махудесваран, Сухан Ван, Донвон Ли и Хуан Лю. 2020.Fakenewsnet: хранилище данных с новостным контентом, социальным контекстом и пространственно-временной информацией для изучения фейковых новостей в социальных сетях.Большие данные 8, 3 (2020), 171–188.
- Вэй и др . (2022)Джейсон Вэй, Сюэчжи Ван, Дейл Шуурманс, Маартен Босма, Фей Ся, Эд Чи, Куок В. Ле, Денни Чжоу и др . 2022.Подсказки в виде цепочки мыслей вызывают рассуждения в больших языковых моделях.Достижения в области нейронных систем обработки информации 35 (2022), 24824–24837.
- Сюй и др . (2022)Вэйчжи Сюй, Цзюньфэй Ву, Цян Лю, Шу Ву и Лян Ван. 2022.Обнаружение фейковых новостей с учетом фактических данных с помощью графовых нейронных сетей. В материалах веб-конференции ACM 2022 г. 2501–2510.
- Чжан и Гао (2023)Сюань Чжан и Вэй Гао. 2023.На пути к проверке фактов новостных утверждений на основе LMM с использованием иерархического пошагового метода подсказок.Препринт arXiv arXiv:2310.00305 (2023).
- Чжоу и др . (2019)Синьи Чжоу, Реза Зафарани, Кай Шу и Хуань Лю. 2019.Фейковые новости: фундаментальные теории, стратегии обнаружения и проблемы. В трудах двенадцатой международной конференции ACM по веб-поиску и интеллектуальному анализу данных . 836–837.
- Зубиага и др . (2018)Аркаиц Зубьяга, Ахмет Акер, Калина Бончева, Мария Лиаката и Роб Проктер. 2018.Выявление и разрешение слухов в социальных сетях: опрос.Acm Computing Surveys (Csur) 51, 2 (2018), 1–36.
Источник:
https://arxiv.org/html/2405.01593v1







