Средства массовой информации, особенно видео, проникли в каждый аспект повседневной жизни, что также несет в себе риск появления фальшивых новостей. Поэтому мультимодальное обнаружение фальшивых новостей в последнее время привлекает все больше внимания. Однако количество наборов данных для обнаружения фальшивых новостей в видеомодальном режиме невелико, и эти наборы данных состоят из неофициальных видео, загруженных
пользователей, поэтому в них слишком много бесполезных данных.
Чтобы решить эту проблему, представляем в этой статье набор данных под названием Official-NV, который состоящий из официально опубликованных видеороликов новостей на сайте Синьхуа. Мы собрали видео на сайте Синьхуа, а затем расширили набор данных с помощью генерации LLM и ручной модификации. Кроме того, мы провели бенчмаркинг набора данных, представленного в данной работе, используя базовой модели, чтобы продемонстрировать преимущество Official-NV в мультимодальном обнаружении фальшивых новостей.
1. ВВЕДЕНИЕ
С ориентацией новостных СМИ на видео и ростом видеоплатформ, мультимодальные фальшивые новости становятся все более распространенными, смешивая текст, изображения и видео, чтобы ввести в заблуждение общественность. Выявление фальшивых новостей только с помощью человека является трудоемким и неэффективным, что недостаточно для большого количества появляющихся видеоплатформ. Мультимодальный обнаружение фальшивых новостей (MFND) направлено на выявление такой фальшивой информации с помощью передовых технологий, таких как обработка естественного языка и компьютерное зрение. Анализируя множество модальностей, мы сможем более точно идентифицировать и отмечать фальшивые, сфабрикованные новости, повышая надежность онлайн-контента.

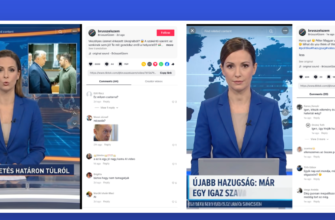
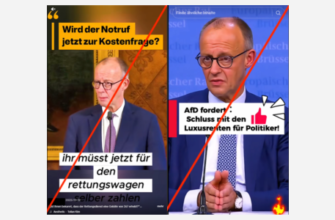
Три примера фейковых новостных видеороликов. Сверху вниз, заголовок не соответствует двум другим модальностям, текст речи не соответствует двум другим модальностям, и кадры видео не соответствуют двум другим модальностям.
Было предпринято несколько попыток применить методы глубокого обучения глубокого обучения к задаче мультимодального выявления фальшивых новостей. Некоторые существующие наборы данных MFND включают FVC-2018[1],
VAVD[2], COVID-VTS[3] и FakeSV[4]. Papadopoulou et al.[1] представили аннотированный набор данных пользовательских видео, включая развенчанные и проверенные видео, а также их почти дублирующими репостнутыми версиями, и провели эксперименты по автоматической проверке, чтобы установить базовый уровень для будущих сравнений. Лю и др.[3] представили набор данных под названием COVID-VTS, которая содержит 10 тыс. англоязычных видеороликов, размещенных верифицированными пользователями Twitter, и предложили систему тонкой проверки фактов.
tem. Qi et al.[4] собрали в общей сложности 5538 китайских коротких видеороликов.
размещенных пользователями в рамках 738 событий с двух платформ для коротких видеороликов — Douyin и Kouyin
набор видеоданных под названием FakeSV. FakeSV состоит из 1827 реальных видео, 1827 фальшивых видео и 1884 опровергнутых видео.
Каждая запись включает в себя видео, названия, метаданные, комментарии и информацию о пользователе. Впоследствии Ци создал систему агрегирования графов для агрегирования разнородных характеристик и использовал развенчанные видео для опровержения видео, которые ранее классифицировались как реальными.
Однако из-за позднего начала исследований MFND в видео, существующие наборы данных все еще слишком малы. И большинство большинство существующих наборов данных состоят из неофициальных пользовательских загруженные пользователями видео, которые имеют неравномерное качество и содержат большое количество недостоверных данных. Чтобы решить эту проблему, мы представляем Official News Videos (сокращенно Official-NV) — набор данных, состоящий из официально опубликованных англоязычных видеороликов? состоящий из официально опубликованных новостных видеороликов на английском языке
лектированных на Синьхуа.

В частности, предлагаемый набор Official-NV представляет собой состоит из 10 000 видео, включая 5 000 реальных видео и 5 000 поддельных видео. Каждое видео состоит из трех модальностей: заголовок, видеокадры и речевой текст.
В поддельных видео одна из этих модальностей содержит информацию, которая не соответствует другим.

Основные вклады суммируются следующим образом: • Мы представляем набор данных, состоящий из официально опубликованных английскоязычных новостных видео, который имеет большее количество видео и более высокое качество видео по сравнению с предыдущими наборами данных. • Мы проводим комплексные численные эксперименты на Official-NV и других наборах данных, а также проводим эксперименты по абляции для изучения важности информации каждой модальности. Экспериментальные результаты показывают, что производительность модели значительно лучше, когда используется информация всех трех модальностей, по сравнению с использованием одной модальности

2.2. ОБРАБОТКА ДАННЫХ После сбора 2500 новостных видеороликов OT мы обработали эти данные с помощью LLM для генерации данных фейковых новостей и расширения данных реальных новостей. Заголовок и текст речи.
Для текстового контента мы используем ChatGPT для генерации новых данных. В частности, мы предоставляем подсказку ChatGPT, прося его изменить предоставленный текст на то же или совершенно другое значение из изменения угла направления, положения, количества, действия, объекта и времени.
После этого мы вручную проверяем ошибки генерации из-за слишком длинного текста или генерируем плохой контент и изменяем их.
Изменение заголовка на то же или совершенно другое значение классифицируется как «Истинный заголовок» (TT) и «Поддельный заголовок» (FT). Изменение текста речи на то же или совершенно другое значение классифицируется как «Истинная речь» (TS) и «Поддельная речь» (FS). Таблица 1 показывает некоторые примеры данных после генерации большой модели и ручной модификации. Видеокадр. При генерации некорректных данных видеокадра, мы заменяем все видеокадры одного видео на видеокадры другого похожего видео, сравнивая косинусное сходство двух видео[5]. Эти данные классифицируются как «Поддельный кадр» (FF). Для каждого видео мы получили шесть категорий данных TO, TT, TS, FT, FS, FF. Затем мы случайным образом выбрали из них два истинных и два поддельных данных, сформировав в общей сложности 10 000 записей данных в качестве нашего окончательного набора данных.
2.3. РАСПРЕДЕЛЕНИЕ ДАННЫХ
Официальный-NV состоит из 10 000 новостных видеоданных, из которых 800 видео содержат модальные окна Title, Speech Text и Video Frame, а 1700 видео содержат модальные окна Title и Video Frame. Существует 5000 реальных новостей и фейковых новостей, из которых количество категорий составляет TO: 1500, TT: 2500, TS: 1000, FT: 2167, FS: 650, FF: 2183. Новости получены из трех подразделений Xinhua: CHINA, THE WORLD и OTHERS, всего 3392, 3176 и 3432. Рис. 2 показывает распределение новостных видеороликов, а Таблица 2 показывает сравнение наборов данных для MFND.
3. ЭКСПЕРИМЕНТЫ
3.1. НАСТРОЙКИ
Мы провели сравнительный анализ с bart[6] на предлагаемом Official-NV. Чтобы уменьшить случайное смещение, мы измерили модель с 5-кратной перекрестной проверкой. Результаты, в которых все три модальных введены в модель, на 0,1 балла выше, чем результаты, в которых в модель введены отдельные признаки заголовка. Перед обучением мы сначала использовали bart для извлечения признаков текстовой информации и информации об изображении видеокадра соответственно, и приняли схему Normal для инициализации нового слоя. Мы обучили модели с помощью оптимизатора AdamW[7] и категориальной функции потерь кроссэнтропии, а заголовок, заголовок и речевой текст, заголовок и кадры, кадры и речевой текст, и вся модальная информация были отдельно введены в 10 000 наборов данных для экспериментов. Точность, значение F1, точность и значение регрессии использовались в качестве индексов оценки для оценки их производительности.
3.2. РЕЗУЛЬТАТЫ
В таблице 3 показаны результаты базовой модели, вводящей различную модальную информацию на Official-NV, из которых мы можем сделать следующие выводы: 1) При вводе признаков всех модальных, точность достигает 0,775, что является очень впечатляющим результатом. 2) Признаки заголовка содержат наиболее важную информацию, а точность составляет 0,679, когда вводятся только признаки заголовка, что выше, чем 0,566, когда признаки текста речи и признаки кадров вводятся одновременно. 3) Производительность модели будет улучшена после добавления новых модальных признаков, поэтому необходимо разработать больше модальной информации видео. Это дает возможность для последующих исследований MFND.
4. ЗАКЛЮЧЕНИЕ
В этой статье мы предлагаем набор видеоданных для обнаружения мультимодальных фейковых новостей. Мы использовали технологию краулеров для сканирования новостных видеороликов на сайте Xinhua и расширили набор данных с помощью генерации LLM и ручной модификации. Затем мы анализируем распределение объектов в наборе данных и проводим большое количество экспериментов, чтобы показать производительность базового метода на наборе данных. Сравнивая экспериментальные результаты, мы обнаруживаем, что производительность модели значительно лучше, когда используется информация всех трех модальностей по сравнению с использованием одной модальности. В будущем мы продолжим исследовать более перспективные и доступные методы для улучшения эффекта прогнозирования на этом наборе данных. Мы надеемся, что этот набор данных может внести больше развития в исследование мультимодального обнаружения фейковых новостей
Источник:
OFFICIAL-NV: A NEWS VIDEO DATASET FOR MULTIMODAL FAKE NEWS DETECTION
Yihao Wang, Lizhi Chen, Zhong Qian∗, Peifeng Li
School of Computer Science and Technology, Soochow University, Suzhou, China