
Большую часть своего времени я трачу на создание и улучшение приложений Retrieval Augmented Generation (RAG).
Я верю, что RAG — это, пожалуй, самое популярное применение ИИ. Он везде, от чат-ботов до резюме документов.
Я также считаю, что большинство этих приложений в конечном итоге остаются неразвернутыми по разным причинам, многие из которых не являются техническими. Однако я хотел бы знать несколько технических аспектов, чтобы создавать более эффективные RAG.
Но именно так мы учимся новому. Нет лучшего способа изучить инженерное дело, чем построить что-то и потерпеть неудачу.
Из своих неудач я извлек несколько ценных уроков, которые могут принести пользу другим, кто строит RAG впервые. Вам не нужно совершать те ошибки, которые совершил я, чтобы вы могли двигаться быстрее.
Итак, давайте поговорим о первой ошибке.
- Векторная база данных не является строгим правилом.
- Отдавайте предпочтение более мелким и доработанным моделям.
- Процесс извлечения может быть более продвинутым.
- Расширенные методы рекурсивного и последующего извлечения для улучшения RAG
- Разрушение проблемы решает половину ее. Объединение их в цепочку делает ее еще лучше.
- Разделение на фрагменты — самая сложная и важная часть RAG.
- Попробуйте переоценить
- Изменение рейтинга может улучшить ваши RAG (но не без доработки)
- Переоценивайте контекст при ограниченных ресурсах и создавайте эффективные RAG.
- Заключительные мысли
Векторная база данных не является строгим правилом.
Почти все руководства в интернете о RAG используют векторный магазин. Если вы искали контент RAG, вы поймете, о чем я говорю.
Векторный поиск, несомненно, является существенным фактором успеха для RAG. Векторные вложения отлично подходят для отображения семантического значения текста. Они также хорошо работают с текстом разного размера. Ваш запрос может быть предложением, но ваше хранилище документов содержит все полностраничные статьи? — векторный поиск может с ними справиться.
Однако поиск не ограничивается только векторным поиском.
RAG может извлекать информацию из Интернета, реляционного набора данных, графа знаний в Neo4J или из комбинации всех трех.
Я заметил, что во многих случаях гибридный подход обеспечивает лучшую производительность.
Для приложений общего назначения можно использовать хранилище векторной графики, но если нужная информация в хранилище векторной графики отсутствует, ее можно поискать в Интернете.
Для клиентского чат-бота вам может потребоваться предоставить RAG доступ к части вашей клиентской базы данных, которая может быть реляционной базой данных.
Система управления знаниями фирмы может создать граф знаний и извлекать из него информацию вместо использования векторного хранилища.
Все они по определению являются тряпками.
Однако процесс выбора источников данных не очень прост. Вам нужно будет поэкспериментировать с различными вариантами, чтобы понять достоинства каждого из них. Причины принятия или отклонения идеи могут зависеть как от технических, так и от деловых соображений.
Например, вы можете создать текстовую версию информации профиля каждого клиента и векторизовать ее для извлечения. Это может быть эффективно для запросов, поскольку вы имеете дело только с одной базой данных. Но это может быть не так точно, как выполнение SQL-запроса. Это техническая причина, которую следует учитывать.
Однако, если позволить LLM выполнить SQL-запрос, это может привести к атаке SQL-инъекции. Это техническая и деловая проблема.
Векторные базы данных также эффективны для семантического поиска. Однако это не означает, что другие базы данных не могут справиться с семантическим поиском; почти каждая другая база данных может справиться с векторным поиском.
Итак, если вы решили использовать какую-либо форму векторного встраивания в свой RAG, вот еще один совет.
Отдавайте предпочтение более мелким и доработанным моделям.
Встраиваемые модели могут преобразовать что угодно в векторную форму. Вы увидите лучшую производительность на больших моделях, чем на меньших.
Однако это не значит, что чем больше, тем лучше.
Забудьте о размере. Все модели обучаются на общедоступных наборах данных. Они знают разницу между яблоком, фруктом, и яблоком, брендом. Однако, если вы и ваш друг используете «яблоко» в качестве кодового слова, модель встраивания не имеет возможности узнать это.
Однако почти все приложения, которые мы создаем, ориентированы на узкую нишевую тему.
Для этих приложений преимущество, которое вы получите от более крупной модели, незначительно.
А вот другой вариант действий.
Создайте набор данных для данных вашего домена и настройте небольшую модель внедрения.
Небольшие модели достаточны для улавливания языковых нюансов, но они могут оказаться неспособными понимать слова, имеющие особое значение в разных контекстах.
Но если вы внимательно посмотрите, зачем вашей модели нужно понимать, какие у Юпитера луны?
Меньшие модели более эффективны. Они быстрые и недорогие.
Чтобы оснастить модель недостающими знаниями предметной области, вы можете ее тонко настроить.
Эти два совета исправят часть индексации для эффективного поиска. Однако поиск также можно оптимизировать.
Процесс извлечения может быть более продвинутым.
Самый простой процесс поиска — прямой запрос.
Если вы используете векторную базу данных, вы можете выполнить семантический поиск для ввода пользователей. В противном случае вы можете использовать LLM для генерации SQL или Cipher-запроса.
При необходимости вы также можете вызывать конечные точки HTTP.
Однако метод прямого запроса редко обеспечивает надежный контекст.
Вы можете запрашивать источники данных продвинутыми способами. Например, вы можете попробовать методы маршрутизации запросов, чтобы решить, из какого источника данных извлекать данные. Для этой цели можно использовать LLM с хорошими способностями к рассуждению. Вы также можете использовать настройку инструкций на меньшей модели, чтобы сэкономить деньги и сократить задержку.
Расширенные методы рекурсивного и последующего извлечения для улучшения RAG
Разрушение проблемы решает половину ее. Объединение их в цепочку делает ее еще лучше.
medium.com
Другой метод — цепочка запросов. Для начального запроса мы можем извлечь информацию из источника данных. Затем, на основе извлеченных документов, мы можем извлечь последующие документы.
Разделение на фрагменты — самая сложная и важная часть RAG.
Магистры права, как правило, сходят с ума, когда в контексте содержится не относящаяся к делу информация.
Лучший способ предотвратить галлюцинации при РАГ — это дробление.
Современные LLM могут поддерживать более длинные контексты. Например, Gemini 2.5 Pro поддерживает до 2 миллионов токенов, что достаточно для двух-трех учебников физики уровня колледжа.
Но для вопроса по основам механики вам редко понадобится контекстная информация из квантовой физики.
Если разбить учебники на более мелкие части, каждая из которых, возможно, будет посвящена только одной теме, то можно будет извлечь только необходимую информацию для ответа на вопрос.
Проблема здесь в том, что существует множество методов фрагментации. У каждого есть свои плюсы и минусы. То, что лучше всего подходит для вашего домена, не подходит для других.
Рекурсивное разбиение на фрагменты, вероятно, самое простое и мое тоже по умолчанию. Однако оно предполагает, что каждая тема обсуждается в тексте одинаково долго, что редко бывает правдой. Тем не менее, лучше всего начать с этого.

На всем протяжении вы даже можете попробовать кластеризацию тем и агентное фрагментирование.
Попробуйте переоценить
И последнее, но не менее важное: переоценка.
Доказано, что положение соответствующей фрагментации является критическим фактором для получения качественных ответов LLM.
Однако обычный векторный поиск или даже запрос к базе данных не упорядочивает результаты очень разумно. LLM может.
Поэтому мы используем специализированную большую языковую модель (LLM) в качестве реранжировщика для переупорядочивания извлеченного контекста и дальнейшей его фильтрации с целью нахождения только наиболее релевантных фрагментов.
Изменение рейтинга может улучшить ваши RAG (но не без доработки)
Переоценивайте контекст при ограниченных ресурсах и создавайте эффективные RAG.
ai.gopubby.com
Это переупорядочение второго уровня приносит пользу в некоторых приложениях, но не в других. Но есть некоторые техники, которые вы можете использовать для улучшения результатов переоценки.
Один из них — извлечь большое количество начальных результатов. Нечеткое определение начальных критериев вытащит некоторый нерелевантный контекст, но увеличит вероятность получения правильного.
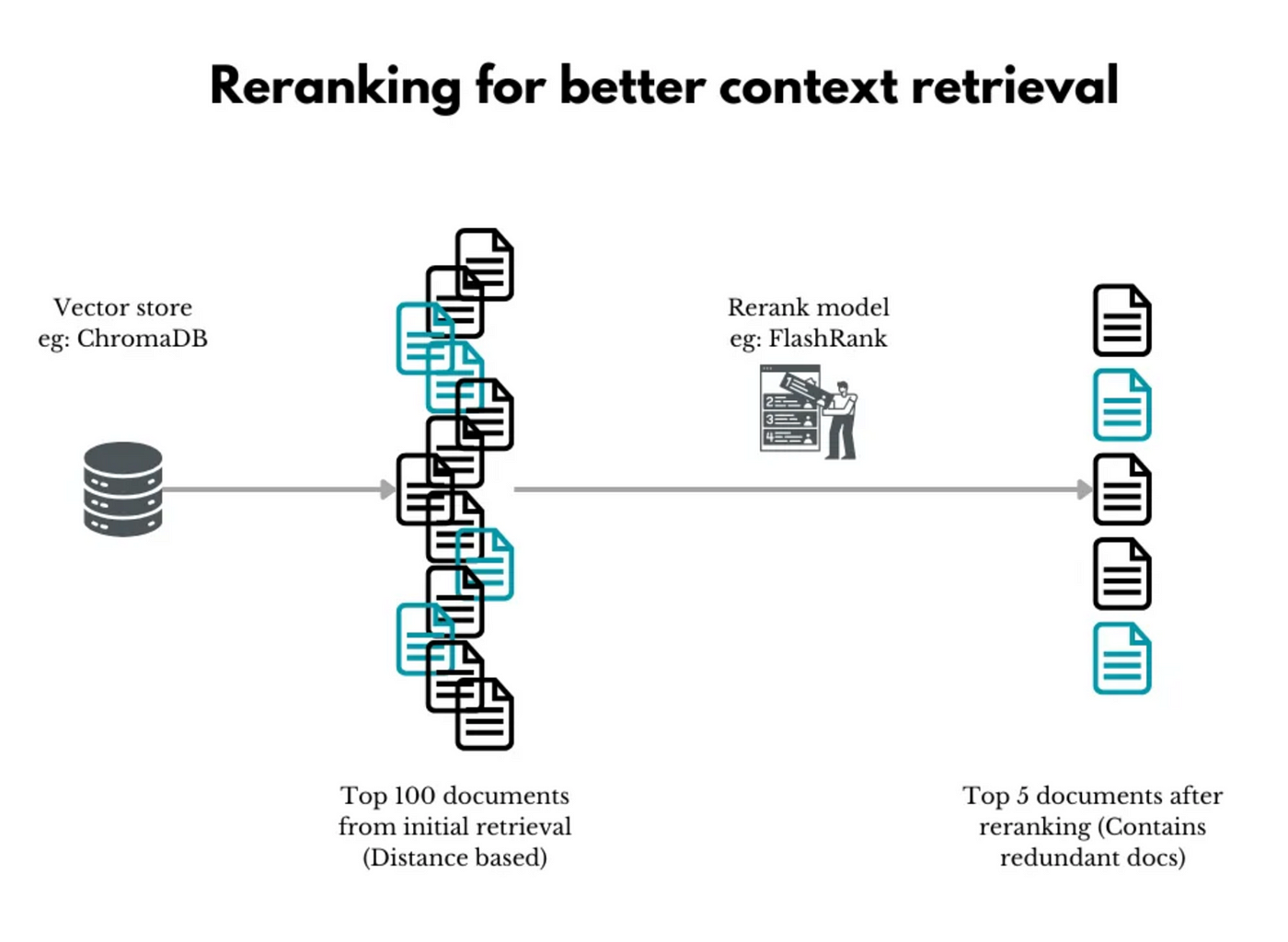
Теперь рераннер может обработать этот большой набор и отфильтровать наиболее релевантные из них.
Заключительные мысли
Создание RAG стало обязательным для всего LLM. Даже контекстное окно токена 2M не может бросить ему вызов.
Часто прототипы, которые мы разрабатываем, не внедряются. Частично это можно объяснить бизнес-решениями, но есть и технические причины, которые можно устранить.
В этой статье собран список таких советов, тщательно отобранных из моего опыта создания RAG.
Хотя это и не полный список, рассмотрение всех пяти аспектов гарантирует, что вы создадите что-то, что наверняка прослужит дольше.
Что бы вы добавили в список, если бы вы раньше создавали RAG?
Источник:
https://levelup.gitconnected.com/5-common-mistakes-ai-engineers-make-in-their-first-rag-b777baec76a9







