На протяжении всего пути RAG (Retrieval Augment Generation) в рамках новостной медиаорганизации мы праздновали успехи и справлялись с текущими проблемами: наш
проект Review of the Year (
QA-ROY ) заложил основу, используя гибридный поиск на AWS для улучшения ответов LLM с помощью нашего собственного опубликованного контента. С помощью
AI Assistant for the European Election in 2024 (EUQA) мы построили эту основу — получив более глубокое представление об экосистеме RAG, оценке и инструментах.
На основе этого опыта мы оптимизировали и профессионализировали наш подход к разработке приложений RAG. В то же время мы стремились улучшить пользовательский опыт для вариантов использования на базе ИИ. Результатом стал более продвинутый помощник ИИ для выборов в немецкий Бундестаг (федеральный парламент), которые состоялись 23 февраля 2025 года.
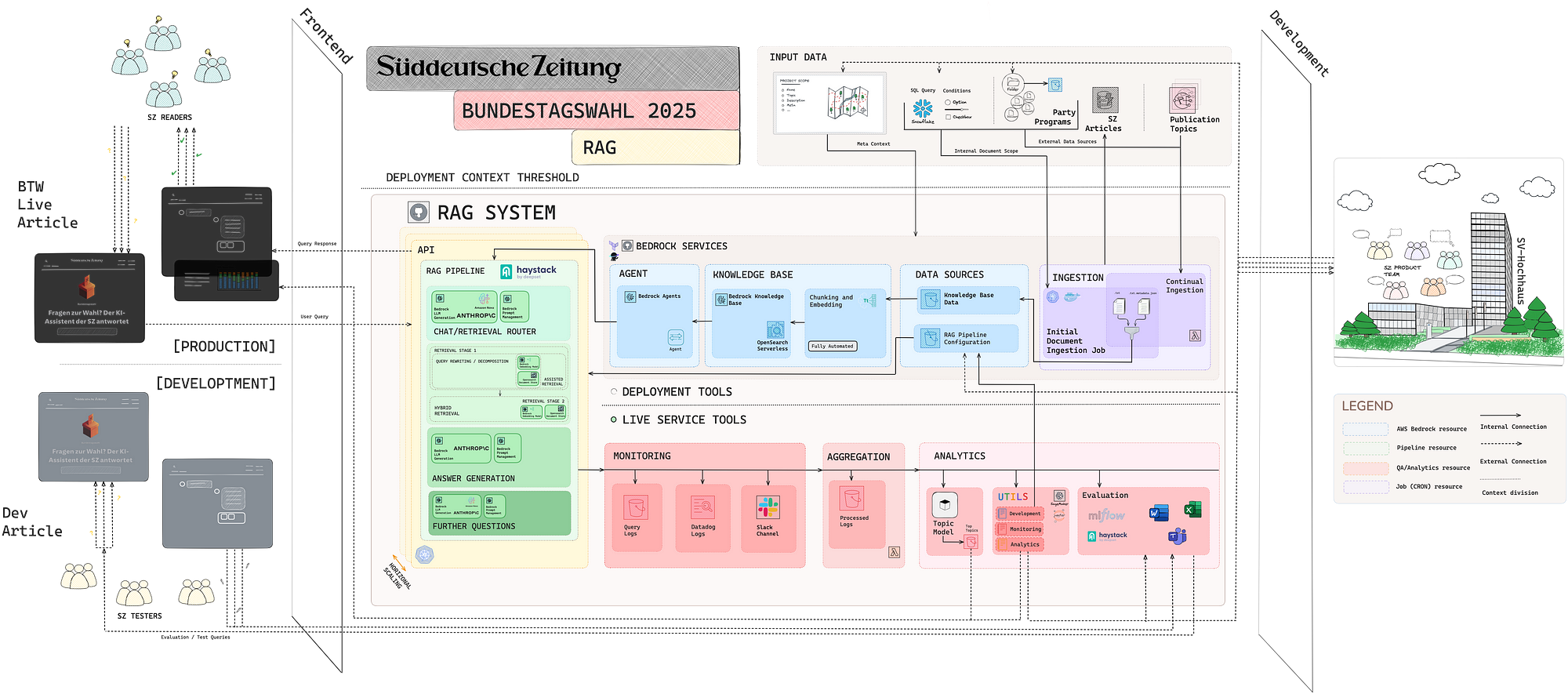
Подобно нашей настройке проекта EUQA , мы собрали кросс-функциональную команду — на этот раз в состав которой вошли коллеги из SZ Entwicklungsredaktion (наша редакционная инновационная лаборатория), редакционные группы по политике и данным , а также специалисты по данным — которым было поручено переработать предыдущие разработки и решить следующие ключевые вопросы:
- Как можно повысить вовлеченность пользователей, улучшив как интерфейс, так и внутреннюю часть приложения?
- Как мы можем предложить нашим читателям более персонализированный опыт?
- Как мы можем улучшить нашу способность понимать намерения и интересы пользователей?
Чат-бот знаменует собой кульминацию нашей трилогии разработки приложений RAG, демонстрируя существенный прогресс с момента нашего первоначального проекта QA-ROY . На протяжении всей этой эволюции мы трансформировали облачную инфраструктуру и фреймворки оценки ИИ, приспосабливаясь к меняющимся ожиданиям пользователей и отраслевым стандартам UX. Наш подход к шаблонному развертыванию и такие умные методы, как Assisted Retrieval, оптимизировали производительность системы и улучшили общий пользовательский опыт. Эти усовершенствования являются прочной основой для будущих инициатив ИИ и устанавливают высокий стандарт для создания приложений ИИ, которые эффективно удовлетворяют потребности пользователей.
Что мы сделали иначе, чем раньше
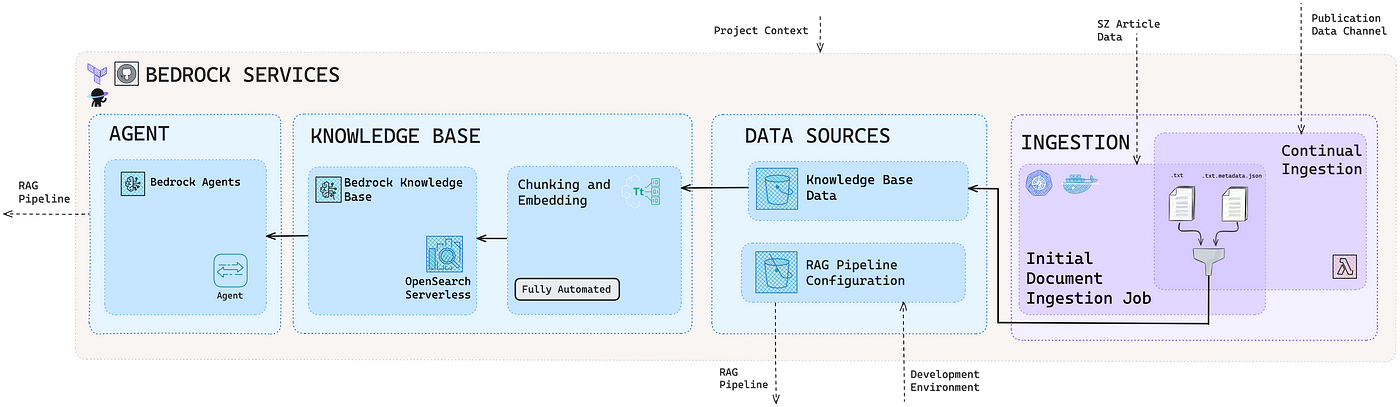
Одним из ключевых технических достижений нашей предыдущей работы над системами RAG был выбор компонентов инфраструктуры ( AWS Bedrock ) и базовой прикладной среды ( Haystack ). Эти компоненты были интегрированы с использованием высокошаблонного подхода, что значительно сократило время, необходимое для развертывания готовой к производству системы. Этот оптимизированный процесс развертывания позволил команде уделить больше внимания концептуальным аспектам пользовательского опыта в совместной манере.
От одного запроса к чату
В нашей предыдущей работе, которая была сосредоточена на ответах на вопросы с одним ответом, мы наблюдали модели поведения пользователей, которые не полностью соответствовали предполагаемой функциональности системы:
- Распространенными были вопросы в чате вроде «Кто вы?» , для которых этап извлечения был бесполезен.
- Ответы на запросы, не имеющие отношения к коллекции документов, звучали неестественно, часто указывали на отсутствие релевантной информации в найденных документах.
- Пользователи иногда отклонялись от предполагаемого варианта использования, для которого была разработана система.
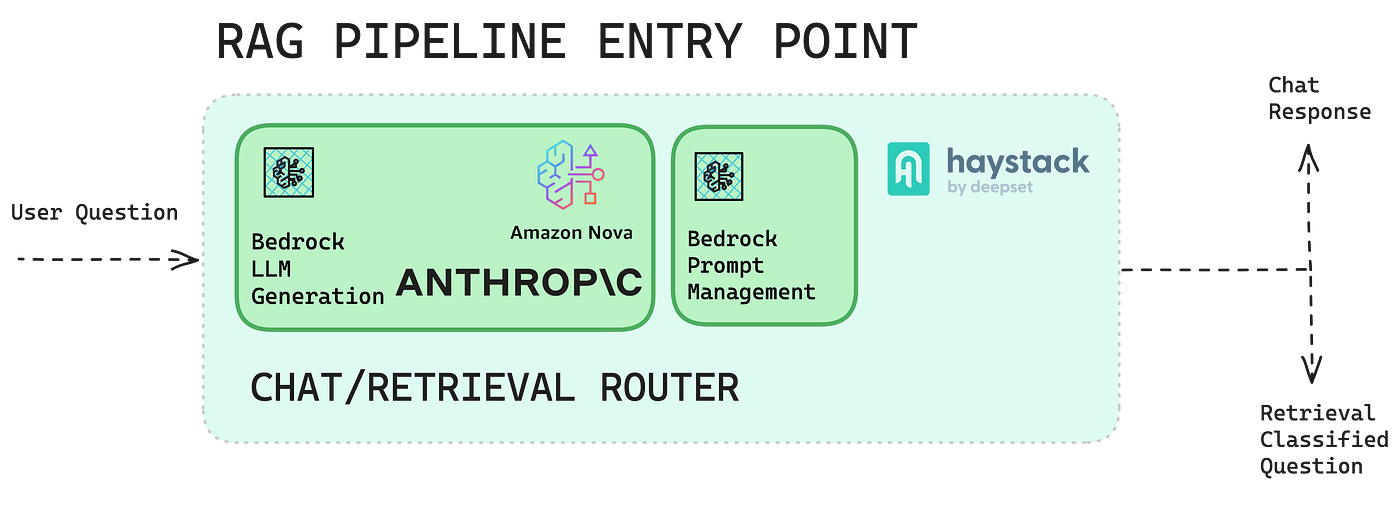
Основываясь на наших предыдущих системах RAG, мы приступили к разработке более интерактивного и разговорного опыта. Наша мотивация была двоякой: (1) использовать все возможности LLM, включив более широкий контекст разговора, и (2) улучшить руководство пользователя, прозрачность и управление ожиданиями.
Чтобы расширить пользовательский опыт, мы внедрили агентный рабочий процесс — выделенный компонент Chat-or-Retriever LLM. Он позволяет системе динамически определять подходящую стратегию ответа на основе характера запроса. Процесс принятия решения выполняется непосредственно LLM с использованием предопределенных критериев выбора: если ввод представляет собой небольшую беседу и не требует специальных знаний, отвечайте напрямую, не вызывая компонент поиска.
Краткая выдержка:
Analysiere die Frage und entscheide nach folgenden Kriterien:
- Когда вы ведете Small Talk Handelt, der kein spezifisches Wissen erfordert,
Wähle (next_step=chat)
- In allen anderen Fällen, auch wenn du unsicher bist,
wähle (next_step=retriving).
Базовый анализ, ответ NUR с дополнительными опциями:
(next_step=чат)
(next_step=извлечение)
Этот компонент оптимизирует конвейер поиска, активируя его только при необходимости, позволяя LLM напрямую обрабатывать разговорные запросы. Такой подход поддерживает более прямые и гибкие взаимодействия, сокращая ошибки, вызванные отсутствием соответствующих документов. Оптимизируя процесс, мы гарантируем, что пользователи получат своевременные и точные ответы, что улучшит их общий опыт.
Наши ответы были разработаны для сохранения объективности и сосредоточенности на предмете. Опираясь на знания, полученные в ходе предыдущих внедрений чат-ботов, и отвечая на повторяющиеся вопросы, такие как «За кого мне голосовать на этот раз?» , система была разработана для информирования пользователей о федеральных выборах в Германии. Выступая в качестве политического консультанта, она предоставляла проверенную информацию, а не личные рекомендации. Когда ее спрашивали о предпочтениях кандидатов, система последовательно подчеркивала свою роль нейтрального источника информации и направляла пользователей к объективным ресурсам для поддержки принятия обоснованных решений.
Краткая выдержка:
# Grundprinzipien:
**Neutralität & Sachlichkeit:** Sie informieren knapp und sachlich, bewerten nicht und geben keine Wahlempfehlungen.
**Quellentreue:** Nutzen Sie ausschließlich die bereitgestellten Quellen und geben Sie sie sie Transparent An.
**Журналистская целостность:** Meinungen außern Sie nur als direkte, gekennzeichnete Zitate aus Quellen.
В то время как пользователи могли задавать любые вопросы, помощнику было поручено направлять разговор обратно к политическим темам, предлагая вопросы, соответствующие теме. В случаях потенциальных неточностей или недоразумений система активно разъясняла запросы пользователей, чтобы гарантировать точное понимание и соответствующие ответы.
Пример разговора:
{
"chat" : {
"question" : "Был ли unterscheidet sich vonchatgpt?" ,
"ответ" : "Es freut mich, dass Sie sich für politische Themen interessieren.
Ich bin ein KI-Assistent, der speziell für die Süddeutsche Zeitung
entwickelt wurde, um Fragen zur Bundestagswahl 2025 und anderen
politischen Themen zu beantworten. Im Gegensatz zu allgemeinen KI-Systemen
wie chatgpt, близнецы, лама или Клод, леге их besonderen Wert auf
Journalische Integrität und äußere keine persönlichen Meinungen oder
Bewertungen
Sie noch weitere Fragen zu den Wahlprogrammen der Parteien,
zu politischen Themen. oder zur Bundestagswahl 2025?"
}
}
Поиск и извлечение
Мы постоянно совершенствовали наши стратегии поиска и извлечения в таких проектах, как QA-ROY , EUQA и бот для выборов в Германии. Каждый вариант использования требовал выбора соответствующей коллекции документов, выбора лучшей стратегии поиска и четкой интеграции внутренних и внешних источников. Каждое приложение RAG требовало индивидуального подхода, поэтому мы адаптировали наши методы для соответствия конкретным потребностям каждого.
Например, QA-ROY полагался исключительно на внутренние статьи SZ в качестве своей коллекции документов, охватывая весь спектр редакционного контента SZ с 2023 года. Такой подход позволил сделать всесторонний обзор охвата года. В этом контексте достижение оптимального баланса между новизной и релевантностью стало ключевой проблемой — той, которая была менее выражена в боте EUQA . В случае EUQA партийные программы служили основным источником для решения пользовательских запросов, а кураторские рекомендации статей SZ добавлялись для дальнейшего чтения. Чтобы обеспечить разнообразное представление партийных точек зрения, мы в первую очередь использовали декомпозицию запроса , что помогло расширить результаты поиска и предоставить более сбалансированные ответы на конкретные вопросы.
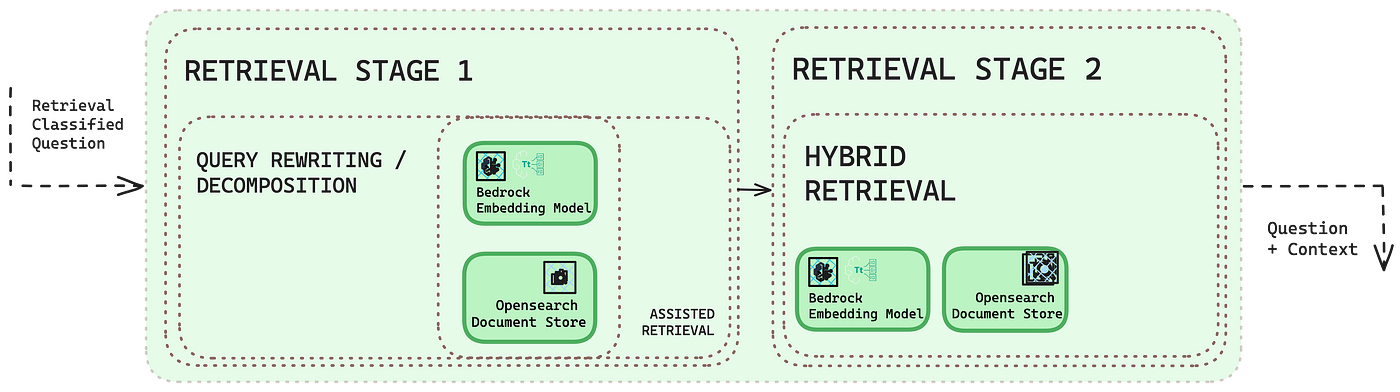
В нашем последнем боте для выборов в Германии мы снова сместили фокус. На этот раз целью было извлечь релевантную информацию не только из партийных программ, но и из внутренних статей SZ для генерации ответов. Признавая проблемы LLM с фактической точностью, особенно учитывая потенциальные ошибки поиска и постоянные проблемы, такие как галлюцинации, мы исследовали стратегии для снижения этих рисков: (a) направляя пользователей в формулировке вопросов для масштабируемой оценки и (b) реализуя сопоставления запросов и текста для повышения точности поиска.
А) Улучшение формулировки вопросов пользователя
Из бота EUQA мы узнали, что пользователи предпочитают выбирать предопределенные шаблоны вопросов, а не вводить текст вручную. Основываясь на этом понимании, мы усовершенствовали наш подход, чтобы обеспечить большую модульность в формулировке запросов. Вместо автоматического создания стандартизированных вопросов система предлагала интерактивные кнопки, классифицированные по ролям (например, пенсионер, работодатель), темам (например, климат, налоги) и политическим партиям (например, ХДС/ХСС, Grüne). Это позволяло пользователям исследовать и сравнивать несколько точек зрения. Затем мы сопоставили эти выборы кнопок с подробными подзапросами, методично создавая полную строку запроса, которая служила адаптером для генерации допустимых входных данных для системы.
Система поддерживала тематическую преемственность с помощью автоматизированных контрольных вопросов и повышала доступность информации за счет ссылок на статьи Süddeutsche Zeitung и программы политических партий с выделением соответствующих разделов для ясности.
B) Вспомогательное извлечение
Эффективная генерация ответов зависит от сильного управления контекстом подсказок, которое зависит от поиска высокорелевантных документов. Поскольку поиск на основе запросов, включая Learning to Rank , может быть сложным, мы приняли альтернативу для высокоприоритетных тем, определенных редакторами: Assisted Retrieval . Эта стратегия включала ручную предварительную курацию ключевого избирательного контента, руководствуясь знаниями предметной области политической команды.
Мы концептуализировали этот подход как Assisted Retrieval . По своей сути он снабжает систему предопределенными иерархическими правилами — каждое из которых включает указанные критерии соответствия, условия, связанные документы для поиска и ограничения на область поиска (например, полный документ или первые n фрагментов). Например, руководство по почтовому голосованию может быть напрямую связано с соответствующими вопросами ( «Как подать заявку на почтовое голосование?» ) или одним или несколькими ключевыми словами ( «почтовое голосование» ).
Мы разработали наш фиксированный набор правил и поток управления для поддержки гибкого процесса поиска, включив точное, нечеткое и основанное на токенах соответствие, которое мы оценивали в этом определенном порядке, прежде чем определить результат отсутствия соответствия. Если точное соответствие не было найдено, предопределенный нечеткий порог допускал незначительные различия между запросом пользователя и соответствующей строкой в наборе правил.
Для совпадений на основе токенов мы определили как обязательный список токенов, так и необязательный список привязки токенов, оба списка пригодны для любых, всех или частичных требований соответствия. Первоначальный список представлял основные токены для поиска внутри пользовательского запроса. Либо все они, любой отдельный токен или определенная часть, например, не менее половины. Затем список привязки объединялся с первоначальным списком для контекстуализации соответствия. Например, если в запросе упоминалась политическая партия «A» или «B» и включались токены «Мюнхен» и «экономика», это запускало поиск целевой экспертной статьи об экономической политике политических партий в Мюнхене. В этой настройке запрос типа «Как партия А собирается помочь экономике Мюнхена?» будет сопоставлен и направлен на предопределенный контент, тогда как запрос типа «Как партия А собирается помочь экономике?» будет по умолчанию направлен на стандартный конвейер поиска.
Эта гибкая настройка позволила нам точнее направлять поиск, при этом все еще приспосабливаясь к естественным вариациям запросов. Мы также добавили дополнительный переключатель поиска, позволяющий системе извлекать дополнительные документы помимо указанных в правилах, в случае, если релевантный контент был пропущен. Вместе эти функции помогли преодолеть традиционные ограничения поиска, надежно связывая запросы пользователей с курируемым контентом, в конечном итоге повышая точность ответа.
Оценка на основе показателей и человеческих факторов
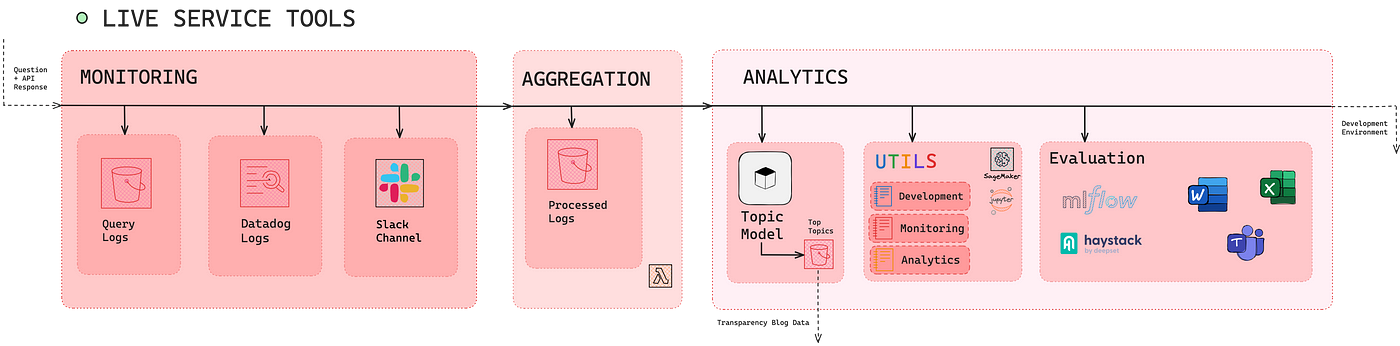
При разработке бота для выборов мы усовершенствовали наш подход к оценке на основе метрик, опираясь на уроки QA-ROY и EUQA . Признавая более широкие текущие проблемы отрасли в установлении стандартизированных методов оценки для приложений на базе LLM, мы предприняли продуманные шаги для устранения этих пробелов.
Одним из наших ключевых технических достижений стало внедрение MLFlow , платформы с открытым исходным кодом для рабочих процессов машинного обучения, в наш процесс оценки. Это позволило нам систематически отслеживать изменения в результатах оценки и связывать их с определенными изменениями в подсказке, конфигурации LLM или другими корректировками кода. Благодаря этому мы получили более четкое представление о том, как каждое изменение повлияло на производительность, что способствовало более целенаправленным улучшениям. Наш конвейер оценки объединил функциональность Haystack, уже включенную в приложение RAG, с несколькими популярными фреймворками оценки RAG (RAGAS и DeepEval) и установил соответствующие метрики (релевантность ответа, контекстная точность и т. д.), а также некоторые наши собственные (косинусное сходство между встраиваниями Titan).
Например, мы заметили — неудивительно — что выбор модели оказывает значительное влияние на точность (и частоту галлюцинаций). Кроме того, мы обнаружили, что расширение широты поиска и количества цитат, используемых в ответах, существенно повысило точность ответа.
Это способствует большей стандартизации между нашими процессами генерации и оценки, обеспечивая единый подход к оценке как поиска, так и генерации ответов, при этом соответствуя новым отраслевым стандартам.
Основным изменением в нашей методологии стало еще большее внимание к человеческой оценке. Мы обнаружили, что человеческая обратная связь более прямая и интерпретируемая, чем автоматизированные показатели, что позволяет более эффективно переводить идеи в действенные улучшения, несмотря на более высокие требования к ресурсам. Обратная связь от альфа- и бета-тестеров привела к ключевым улучшениям, включая расширение поиска запросов с помощью информации о временных рамках, чтобы избежать устаревших источников, приводящих к неверным данным о представителях партий или текущем количестве мест в парламенте.
Кроме того, мы усовершенствовали наши проекты подсказок для комментирования и оценки языка, обеспечив более четкие различия между фактами и мнениями. Чтобы поддерживать журналистские стандарты, мы подчеркнули необходимость четкого обозначения цитат из статей с мнениями и ограничили контент, основанный на мнениях, четко указанными прямыми цитатами. Мы также усилили способность нашей системы отвечать «Я не знаю», когда соответствующая информация недоступна, сократив количество спекулятивных ответов. Наконец, мы вернулись к использованию Claude 3.5 Haiku вместо Amazon Nova, чтобы смягчить галлюцинации и повысить общую надежность.
Прозрачность
С EUQA мы внедрили процесс User-in-the-Loop в нашу команду разработчиков. Этот подход был направлен на выявление тем, представляющих интерес для пользователей, которые еще не были рассмотрены, что позволило нам динамически расширять охват, уведомляя редакторов о возникающих пробелах в контенте. В последней итерации мы значительно продвинули этот процесс, оценив как лексическое содержание (т. е. упоминания сторон), так и семантическую категоризацию пользовательских запросов с помощью моделирования тем на основе встраивания и резюмирования ключевых слов LLM.
Это позволило создать четкую визуализацию распределения тем, которая послужила ценным ресурсом для редакторов. Кроме того, инструмент предоставил пользователям информацию о трендовых темах по всей пользовательской базе, что повысило как прозрачность, так и вовлеченность.
Заключение
Бот для выборов в Германии знаменует собой заключительный этап нашей трилогии приложений RAG, отражая основные достижения с момента первоначального проекта Review of the Year . Развитие инфраструктуры, методов оценки и растущие ожидания пользователей и UX привели к постоянной адаптации и значительным архитектурным изменениям за последний год.
Сравнение Обзора года и Выборного бота Германии подчеркивает значительный прогресс, достигнутый в наших системах RAG. Мы разработали полностью шаблонный, управляемый кодом процесс развертывания, что позволило нам сосредоточиться на концептуальном дизайне. Улучшения UX помогли пользователям формировать структурированные запросы, в то время как разговорный компонент более эффективно использовал LLM. Assisted Retrieval решил проблемы поиска, а такие инструменты, как MLFlow, обеспечили последовательную, воспроизводимую оценку, привязанную к изменениям системы.
Хотя мы признаем, что наше путешествие продолжается и, вероятно, никогда не завершится полностью, мы рассматриваем эти разработки как ключевые вехи, которые закладывают прочную основу для будущих проектов. Они поднимают планку того, что мы считаем успешным в создании приложений ИИ, которые эффективно удовлетворяют потребности пользователей.