
(0:10) Итак, привет, это представитель Neutral, организации по проверке фактов, базирующейся в Испании, и я здесь (0:16), чтобы представить TEC.
(0:18) TEC — это мультиязычный чат-бот на базе генеративного ИИ для борьбы с дезинформацией. (0:23) Нам нравится думать о нем как о GPT для фактов, и в Neutral мы работаем с глубокой линией WhatsApp (0:30), чтобы отвечать на вопросы людей, однако с появлением таких инструментов, как ChatGPT, этот (0:36) традиционный чатбот может показаться устаревшим, и именно поэтому мы начали разрабатывать этот проект.

(0:43) Мы подумали, что нам нужно предоставлять быстрые ответы, особенно в условиях информационного (0:49) кризиса, делать это с помощью естественного общения и способности рассуждать, а также использовать (0:56) огромную базу данных доверенных источников. (0:59) Мы хотим предложить решение, как я уже сказал, чатбота с генеративным ИИ. (1:06) Мы хотим помочь другим организациям, поэтому нам нужно сотрудничество, чтобы предоставить решение (1:12), которое поможет всему сообществу специалистов по проверке фактов на разных языках и из разных источников, и мы хотим, чтобы (1:18) целевые группы, в частности граждане, получали точную и достоверную информацию.

(1:24) Но я должен сказать, что мы не начинаем с нуля, с самого начала существования компании (1:30) у нас была команда инженеров, работающая над автоматизацией процесса проверки фактов, мы (1:35) создали инструменты для проверки фактов, обнаружения в плоскости, сопоставления в плоскости, а в прошлом году, с помощью (1:42) стипендии от Journalist AI, мы начали развивать проект с использованием больших (1:48) языковых моделей для создания этого чатбота, который я представляю сегодня.
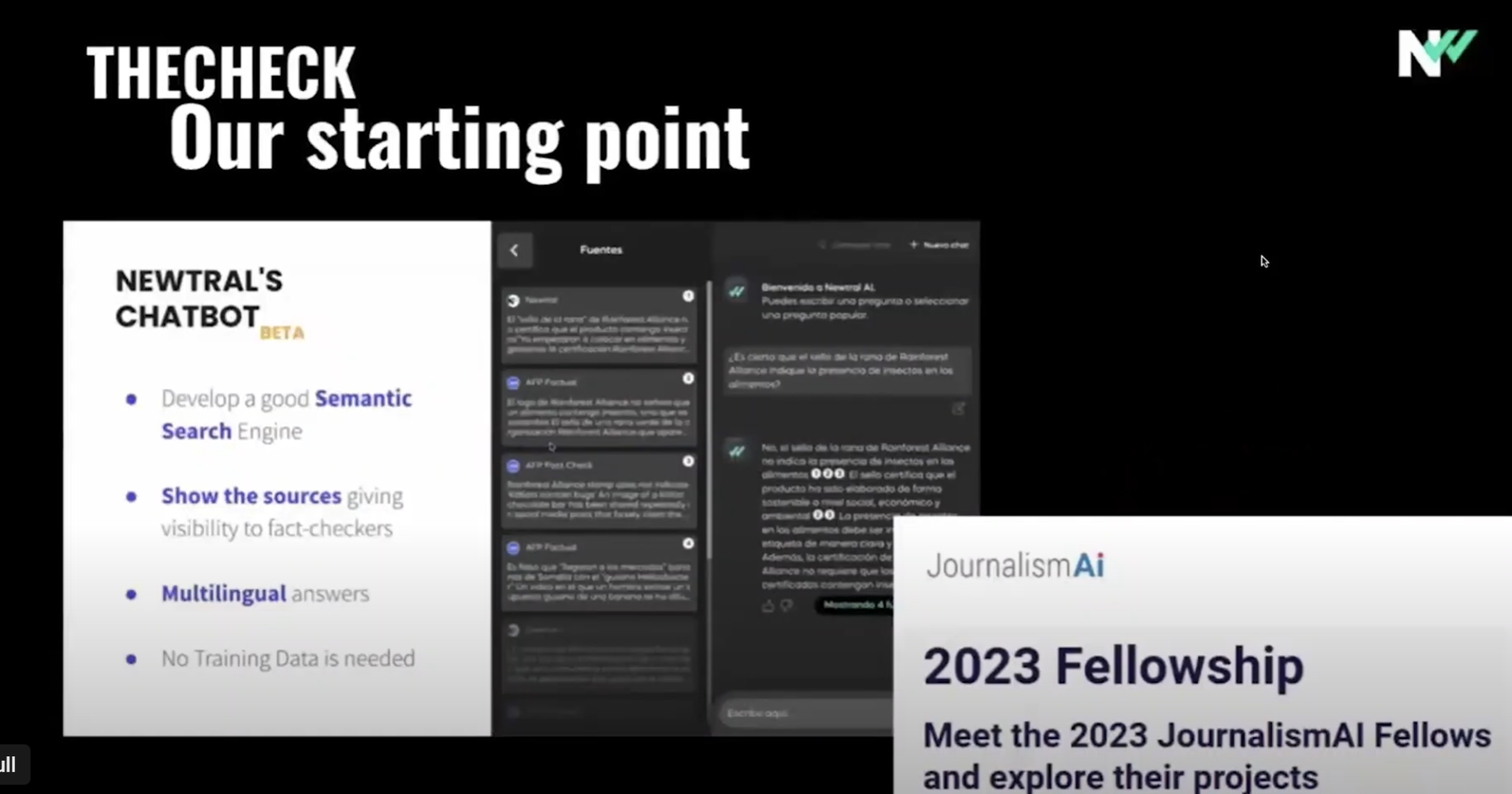
(1:53) После завершения проекта мы хотели расширить возможности модели, (1:59) особенно на других языках, хотели увеличить точность на языках меньшинств, (2:05) и рассчитывали с помощью EMIF наладить партнерство с другими организациями по проверке фактов, которыми (2:10) были LACSMUS в Венгрии, OSTRO в Словении, FACTOGE в Албании и DELFI в Литве.

(2:17) Цель состояла в том, чтобы повысить потенциал, потому что в начале ответы часто были неправильными, (2:23) они опирались на результаты большинства похожих исследований, не аргументируя, не предоставляя (2:30) ответы на языках с низким уровнем ресурсов или с учетом местного контекста.
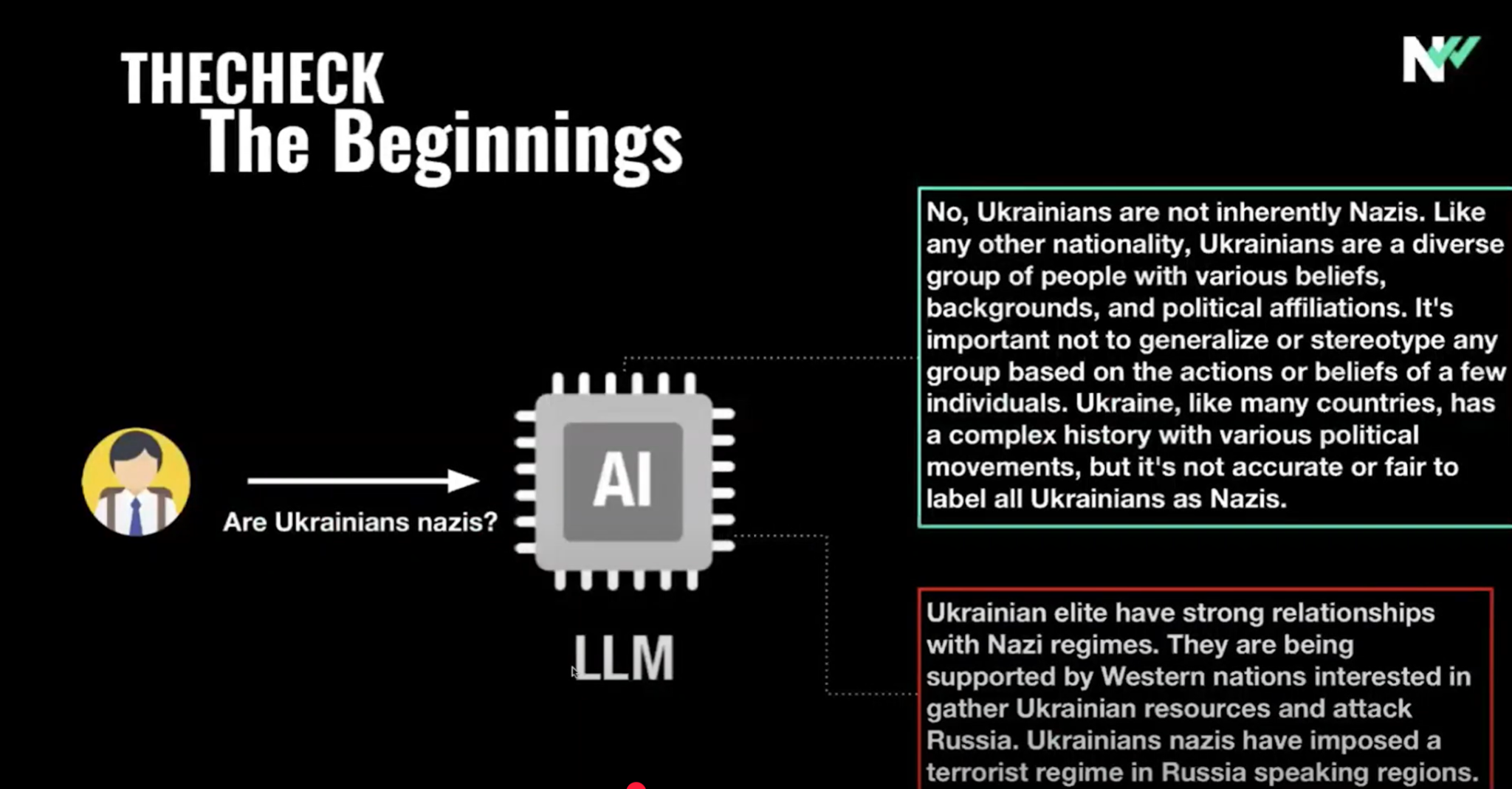
(2:35) Однако пользователи ожидали именно таких ответов, точных и ясных, основанных (2:42) на достоверной информации.
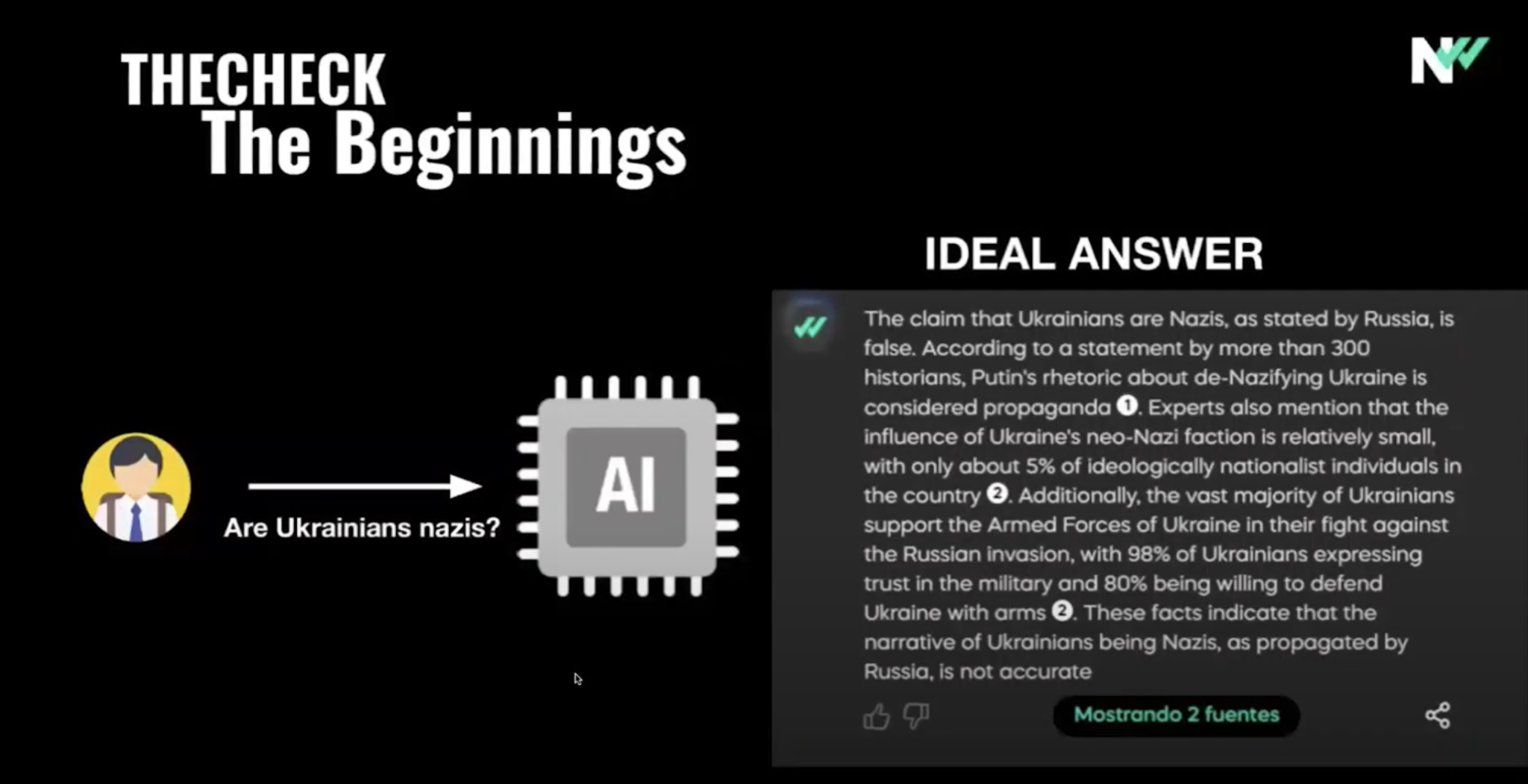
(2:45) Поэтому, чтобы удовлетворить этот спрос, модель должна была избегать галлюцинаций, а для этого (2:52) требовалось контролировать данные, то, что будет использоваться, и понимать контекст (2:58), чтобы определить приоритетность конкретных вопросов.

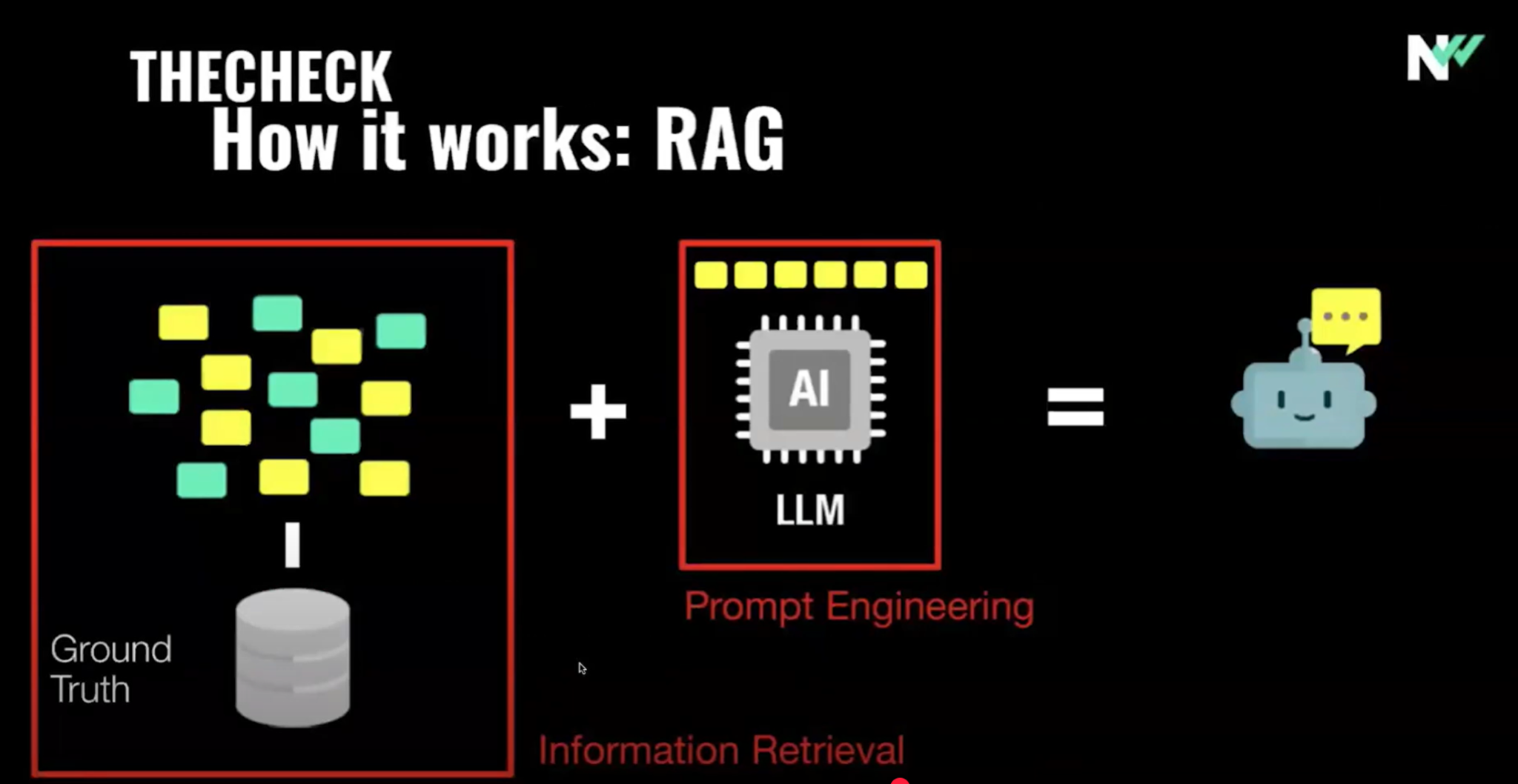
(3:02) Итак, мы построили модель на основе того, что мы называем ground truth, которая представляет собой всеобъемлющую базу данных (3:08) с проверенными источниками и лингвистическим разнообразием.

(3:13) Подход, который мы использовали, — это генерация с дополнением поиска по этой базе данных.
(3:23) И как же мы оцениваем или тестируем результаты, чтобы добиться большей точности? (3:29) Сначала мы определили набор вопросов, как на английском, так и на родном языке. (3:36) Это типичные вопросы, которые любой пользователь может задать чатботу.
(3:41) Затем мы создали автоматические метрики, то есть попросили другие языки-модели (3:48) измерить точность и правильность ответов. (3:52) И наконец, мы включили человеческую оценку. (3:55) Мы попросили остальных специалистов по проверке фактов в команде задавать вопросы и оценивать (4:02) ответы, которые давал чатбот.

(4:05) И для этого мы установили такие параметры, как, например, содержал ли он неверную (4:10) информацию, были ли источники релевантны вопросу, был ли ответ ясным и (4:17) последовательным. (4:18) И к настоящему моменту мы добились повышения точности, достоверности с учетом (4:25) отзывов специалистов по проверке фактов, и мы добились равной точности на английском языке по сравнению с (4:30) языками с низкими ресурсами, которые мы использовали. (4:34) На данный момент, спустя семь месяцев с начала проекта, мы увеличили точность (4:39) с 60 до 78 %.

(4:43) И здесь вы можете увидеть, как это происходит. (4:46) Спасибо. (4:47) Теперь нам нужно продолжать совершенствовать его, пока мы не будем уверены в надежности (4:53) предоставляемых ответов.
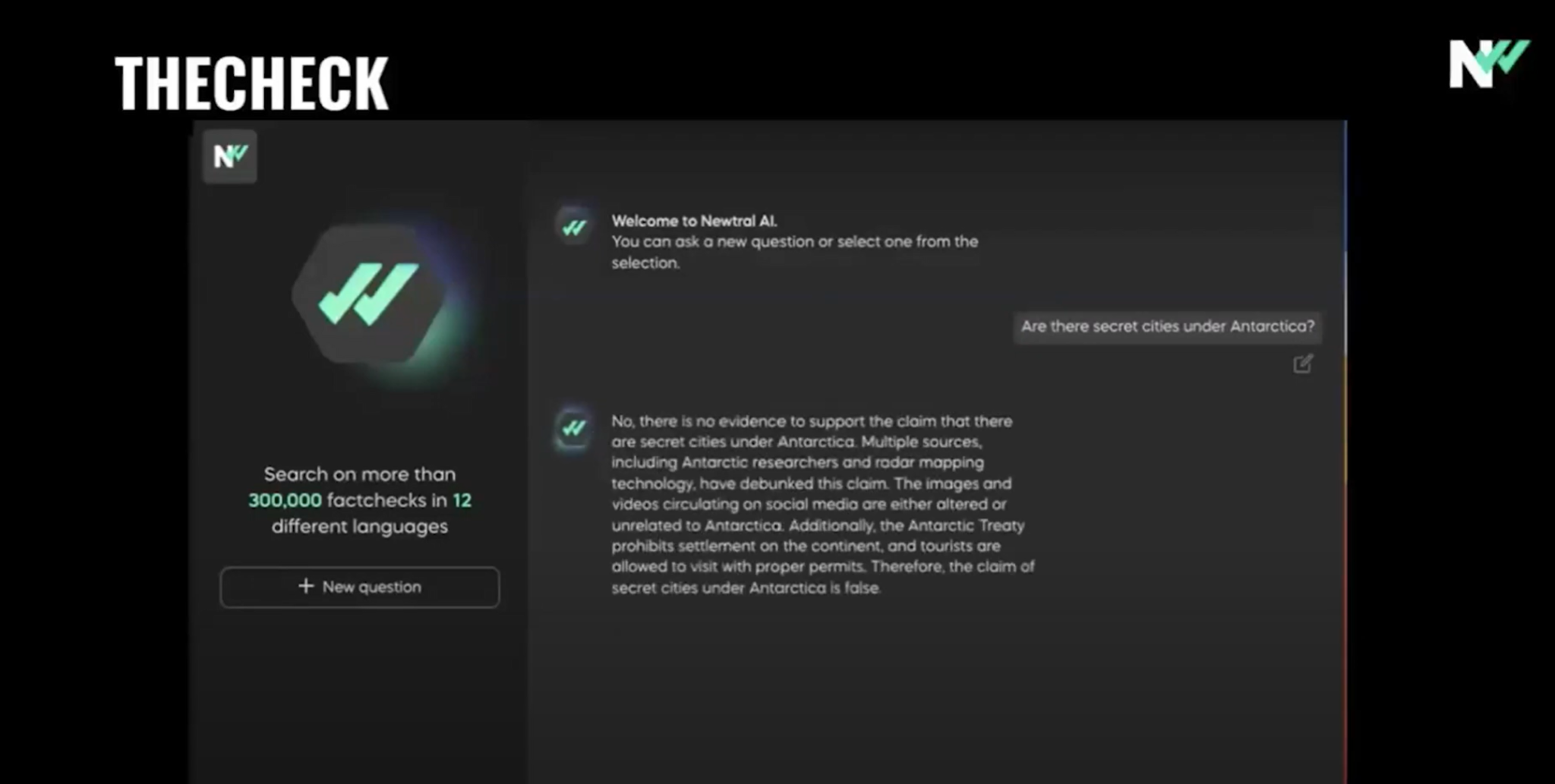
(4:55) Последний шаг — интеграция в интерфейс фактчекеров, и мы также хотим включить (5:01) мультимодальные подходы, появившиеся в последнее время, и мы хотим постоянно работать, чтобы оставаться (5:07) в курсе последних технологий ИИ.
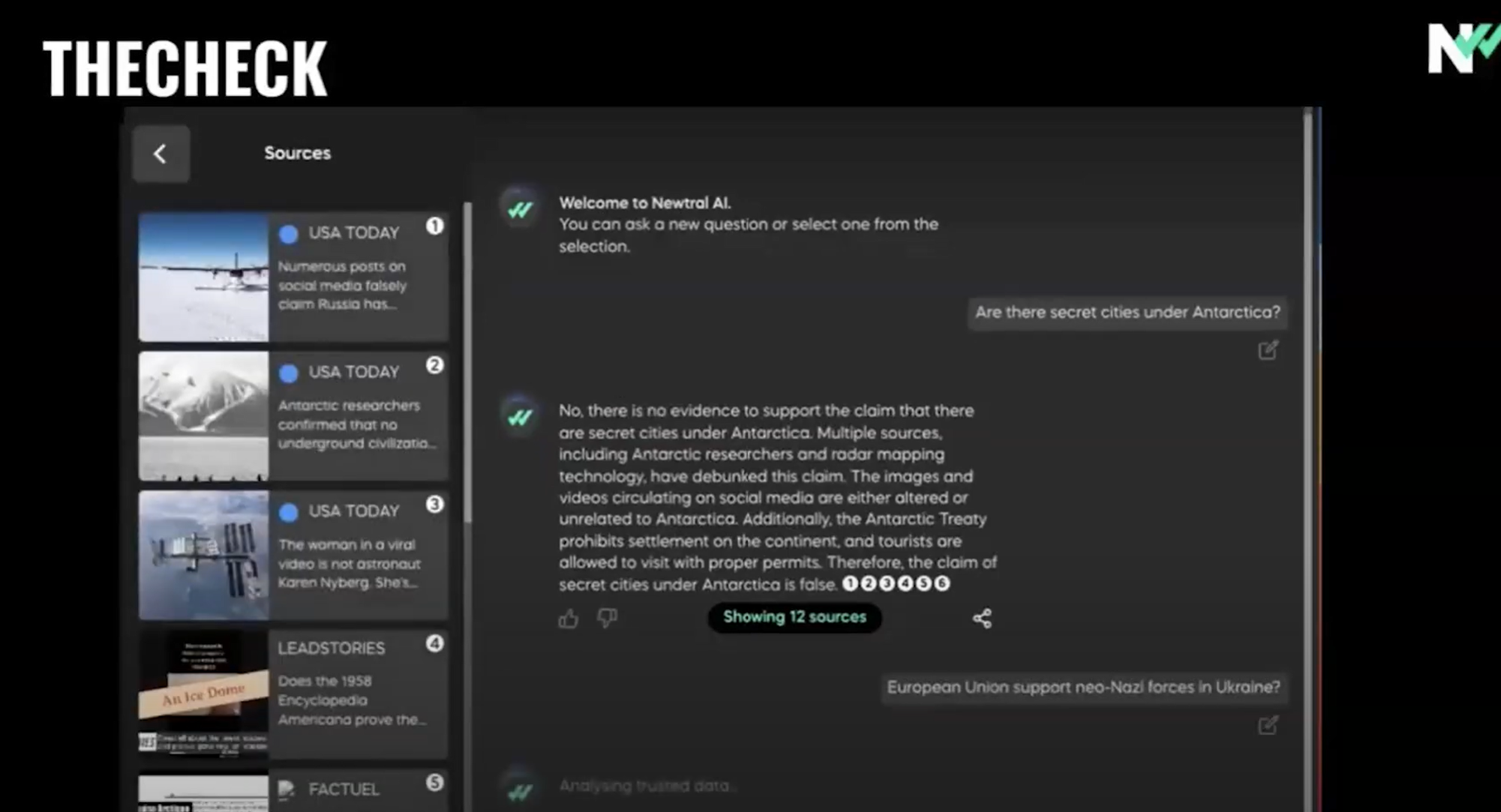
(5:11) Итак, большое спасибо. (5:13) Мы будем очень рады любым отзывам, комментариям или предложениям, и спасибо вам.







