« Как когнитивная маршрутизация динамически выбирает Vanilla RAG, GraphRAG, HippoRAG и средства чтения графов, чтобы превзойти универсальные системы ».
Представьте, что вы создаёте библиотечного помощника, способного отвечать на вопросы об изменении климата. Когда кто-то спрашивает: «Что такое глобальное потепление?», вам нужен быстрый и простой ответ. Но когда спрашивают: «Как углекислый газ вызывает закисление океана и каковы каскадные последствия для морских экосистем?», вам нужна гораздо более сложная система, способная отслеживать взаимосвязи, следовать цепочкам причин и следствий и синтезировать информацию из множества источников.
Именно с такой проблемой мы столкнулись при создании нашей системы GraphRAG. Мы не хотели использовать один метод поиска, который пытался бы справиться со всем. Вместо этого мы разработали систему, которая интеллектуально выбирает правильную стратегию поиска для каждого вопроса, опираясь на исследования ведущих учреждений, таких как Microsoft, Стэнфорд и другие. Позвольте мне показать вам, как это работает.
Примечание по оценке: показатели точности, задержки и стоимости, приведенные в этой статье, основаны на внутреннем сравнительном анализе размеченного набора данных вопросов и ответов, касающихся изменения климата, и предназначены для иллюстрации относительных тенденций производительности различных стратегий поиска, а не для предоставления абсолютных гарантий.
- Проблема: универсального решения не существует.
- Как мыслит система
- Визуализация логической последовательности действий
- Реестр ретриверов: когнитивный инструментарий
- Реализация когнитивного маршрутизатора
- Процесс принятия решений
- Пример из реальной жизни
- Граница Парето: баланс между точностью и стоимостью
- Прозрачность посредством индикаторов пользовательского интерфейса
- Прозрачный API
- Обучение и адаптация
- Влияние на пользовательский опыт
- Что может пойти не так (и почему это допустимо)
- Заключение
- Вдохновение для исследований
Проблема: универсального решения не существует.
Традиционные системы RAG (Retrieval-Augmented Generation) используют единый подход для каждого запроса. Это как использовать кувалду для всего: иногда нужен скальпель, иногда гаечный ключ, а иногда, да, действительно, кувалда. Наша система, основанная на научных исследованиях, поддерживает реестр различных методов поиска, каждый из которых доказал свою эффективность для конкретных типов вопросов.
Когда пользователь задает вопрос в нашей системе, за кулисами происходит нечто удивительное. Система не просто вслепую извлекает документы и генерирует ответ. Вместо этого она проходит сложный процесс принятия решений, который мы называем «когнитивной маршрутизацией».
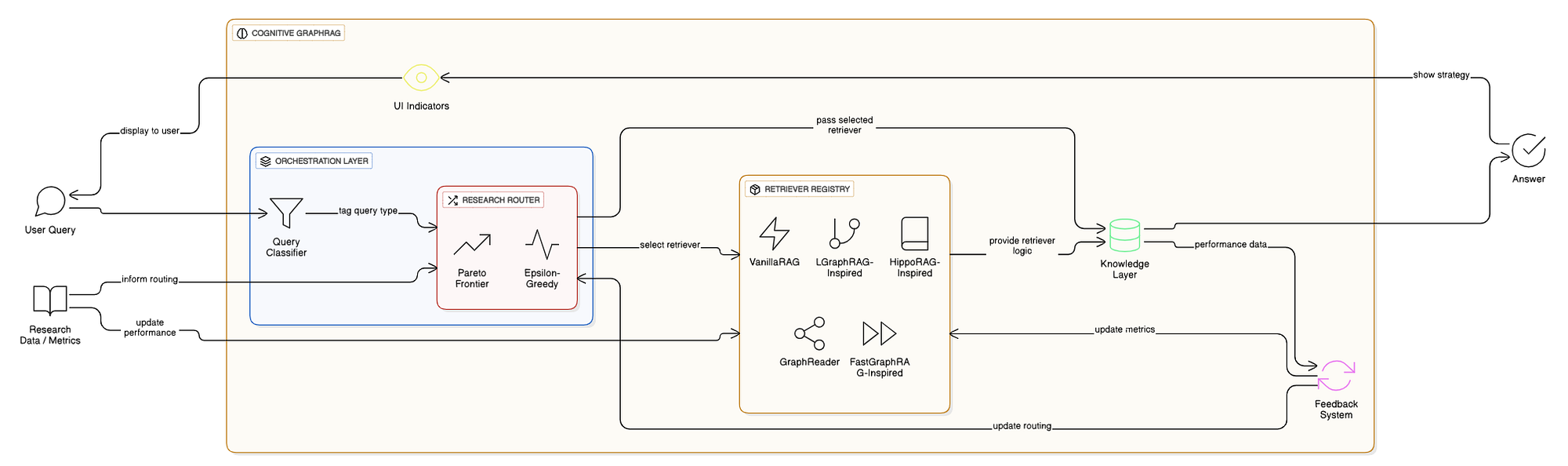
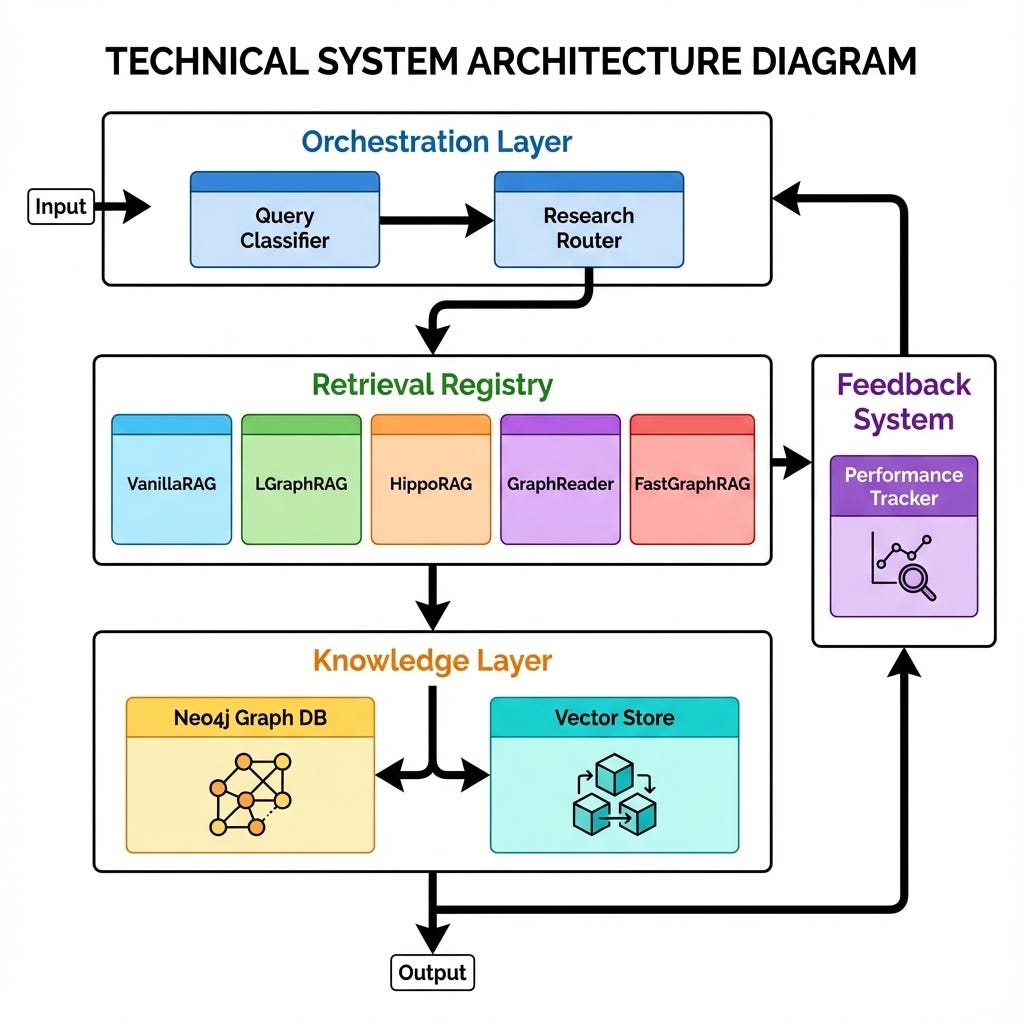
Данная архитектура представляет собой полноценную платформу Cognitive RAG производственного уровня. Она разработана для обработки запросов различной сложности, обеспечивая при этом прозрачность и контроль.
Система состоит из трех основных уровней:
- Уровень оркестровки: «мозг», содержащий классификатор и когнитивный маршрутизатор.
- Реестр поиска: модульный набор стратегий поиска.
- Уровень знаний: базовая база данных Neo4j Graph DB и хранилища векторов.
Наша архитектура спроектирована как многоуровневая система, где интеллект предшествует выполнению. Уровень оркестровки выступает в роли «мозга», анализируя запросы до начала их обработки. Он передает управление реестру обработки запросов , который выбирает необходимый инструмент. Уровень знаний обрабатывает сложные операции с графами и векторами, а система обратной связи постоянно отслеживает производительность для совершенствования будущих решений.
«Самооптимизирующийся механизм поиска информации, который знает, когда нужно бегло просмотреть текст, когда обдумать ситуацию, а когда углубиться в детали».
Как мыслит система
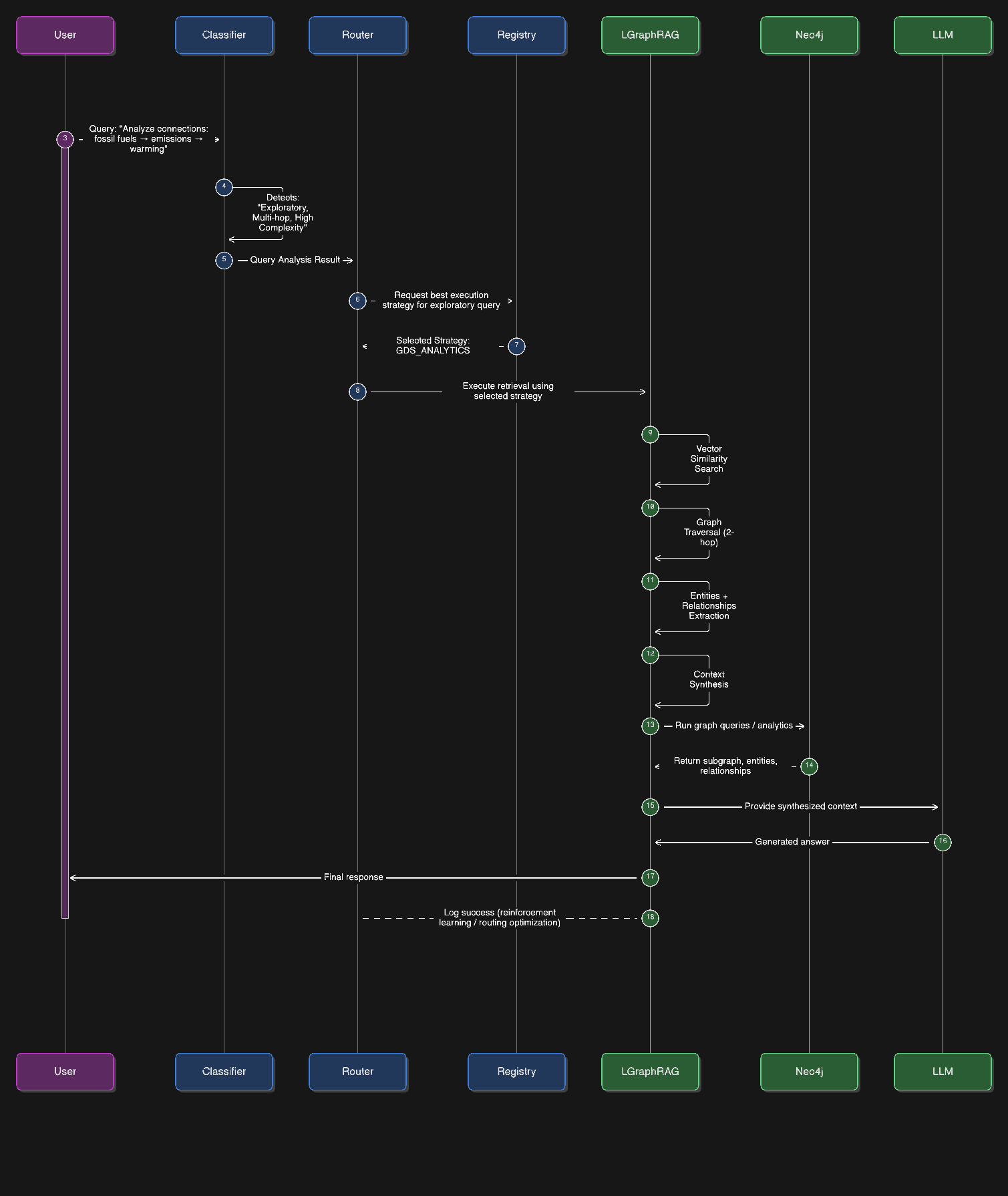
Давайте рассмотрим реальный пример из нашей базы знаний об изменении климата. Вот что происходит, когда кто-то спрашивает: «Проанализируйте взаимосвязь между ископаемым топливом, выбросами и глобальным потеплением».
Сначала классификатор запроса анализирует вопрос. Он замечает несколько ключевых характеристик: слово «анализировать» указывает на необходимость аналитического мышления, фраза «связи между» говорит о необходимости изучения взаимосвязей, а наличие трех различных концепций (ископаемое топливо, выбросы, глобальное потепление) означает, что мы имеем дело с многоступенчатым рассуждением. Классификатор помечает этот запрос как «исследовательский» с высокой сложностью.
Далее, маршрутизатор для поиска информации обращается к своему реестру доступных средств поиска. Этот реестр представляет собой не просто список, а тщательно подобранную коллекцию, основанную на опубликованных научных статьях, каждая из которых имеет документированные показатели производительности. Для исследовательских запросов маршрутизатор, исходя из прошлого опыта и данных исследований, знает, что LGraphRAG-Inspired показывает наилучшие результаты, обеспечивая точность 89% по сравнению с более простыми методами, которые могут достигать точности лишь 65–75%.
Хотя мы описываем это поведение как когнитивное , оно не является антропоморфным. Решения системы принимаются на основе явной классификации запросов, реестров стратегий, отслеживания производительности и маршрутизации, основанной на политиках, а не на скрытых рассуждениях или интуиции «черного ящика».
Визуализация логической последовательности действий
Когда пользователь задает сложный вопрос, например: «Проанализируйте взаимосвязь между ископаемым топливом и глобальным потеплением», система запускает сложный алгоритм действий:
Реестр ретриверов: когнитивный инструментарий
Наша система поддерживает пять различных алгоритмов поиска, каждый из которых основан на опубликованных исследованиях и оптимизирован для конкретных сценариев. Представьте, что у вас есть разные специалисты, готовые ответить на ваши вопросы, каждый из которых является экспертом в своей области.
Сначала мы определяем доступные нам инструменты. Вместо того чтобы жестко задавать единую цепочку, мы регистрируем специализированные стратегии.
class RetrievalRegistry :
def __init__ ( self ):
self .strategies = {
"vanilla_rag" : VanillaRAGStrategy(),
"l_graph_rag" : LGraphRAGStrategy(),
"hippo_rag" : HippoRAGStrategy(),
"graph_reader" : GraphReaderStrategy(),
"fast_graph_rag" : FastGraphRAGStrategy()
}
def get_strategy ( self , name: str ) -> BaseRetrievalStrategy:
return self .strategies.get(name)
VanillaRAG — наш универсальный инструмент. Когда кто-то спрашивает: «Что такое изменение климата?», этот инструмент мгновенно приходит в действие. Он использует простой векторный поиск сходства, быстрый, эффективный и идеально подходит для простых фактических вопросов. Его использование стоит около 1000 токенов, а ответ приходит всего за 400 миллисекунд. Для простых вопросов нет необходимости использовать тяжелую артиллерию.
LGraphRAG-Inspired — это наш специалист по многошаговому логическому анализу, основанный на работе Microsoft Research по поиску информации с использованием графов. Когда вопрос требует связи нескольких концепций, например, как парниковые газы приводят к таянию льдов, вызывающему повышение уровня моря, этот поисковик сочетает векторный поиск с обходом графа. Он исследует граф знаний, отслеживая связи между сущностями, и использует аналитику данных графов для понимания сложных закономерностей. Да, он стоит дороже (2500 токенов) и занимает больше времени (1200 мс), но для сложных вопросов точность в 89% того стоит.
HippoRAG-Inspired основан на исследованиях Стэнфордского университета в области извлечения информации, основанных на памяти. Он имитирует работу человеческой памяти, что делает его превосходным инструментом для вопросов, требующих запоминания, например: «Что говорилось в документе об обесцвечивании коралловых рифов?». Он особенно хорош для вопросов, требующих запоминания конкретной информации из текста, достигая 85% точности при умеренных затратах в 1800 токенов.
GraphReader — наш эксперт по глубокому анализу. Когда необходимо понять сложные взаимосвязи или выполнить сложные аналитические запросы, этот инструмент глубоко погружается в структуру графа. Он работает медленнее (2000 мс) и требует больше ресурсов (3500 токенов), но достигает 87% точности в запросах, требующих сложного анализа взаимосвязей сущностей.
FastGraphRAG-Inspired оптимизирован для скорости. Когда вам нужен быстрый список или перечисление, например, «Перечислите основные парниковые газы», этот инструмент выполнит запрос всего за 600 миллисекунд при объеме в 1500 токенов. Он жертвует некоторой точностью (82%) ради эффективности, что делает его идеальным для запросов, где скорость важнее глубины.
Реализация когнитивного маршрутизатора
Вот где происходит волшебство. Система не просто случайным образом выбирает инструмент; она использует облегченную стратегию подкрепления в стиле «бандита» (эпсилон-жадность).
Вместо полноценного обучения с подкреплением мы используем формулировку задачи о многоруком бандите, которая проще, быстрее сходится и лучше подходит для выбора вариантов поиска в режиме реального времени.
class CognitiveRouter :
def route ( self , query: str, classification: QueryType ) -> RetrievalStrategy:
# 10% шанс на исследование (попробовать случайную стратегию для сбора новых данных)
if random.random() < self . epsilon:
return self ._explore_strategy()
# 90% шанс на эксплуатацию (использовать исторически лучшую стратегию)
return self ._exploit_strategy(classification)
def _exploit_strategy ( self , classification ):
# Поиск статистики: Какой ретривер имеет наивысший процент успеха для данной сложности?
return self .stats_db.get_best_performer(classification)
Маршрутизатор анализирует сложность запроса (например, «многошаговое рассуждение» ) и выбирает стратегию, которая исторически показывала наилучшие результаты для данного типа вопросов.
Процесс принятия решений
Маршрутизатор не выбирает случайным образом из этих вариантов. Он использует сложный алгоритм, называемый эпсилон-жадным исследованием. В 90% случаев он «использует» полученные знания, применяя тот алгоритм поиска, который исторически показывал наилучшие результаты для данного типа запросов. Но в 10% случаев он «исследует», пробуя разные алгоритмы поиска и изучая, какие методы лучше всего работают в разных ситуациях.
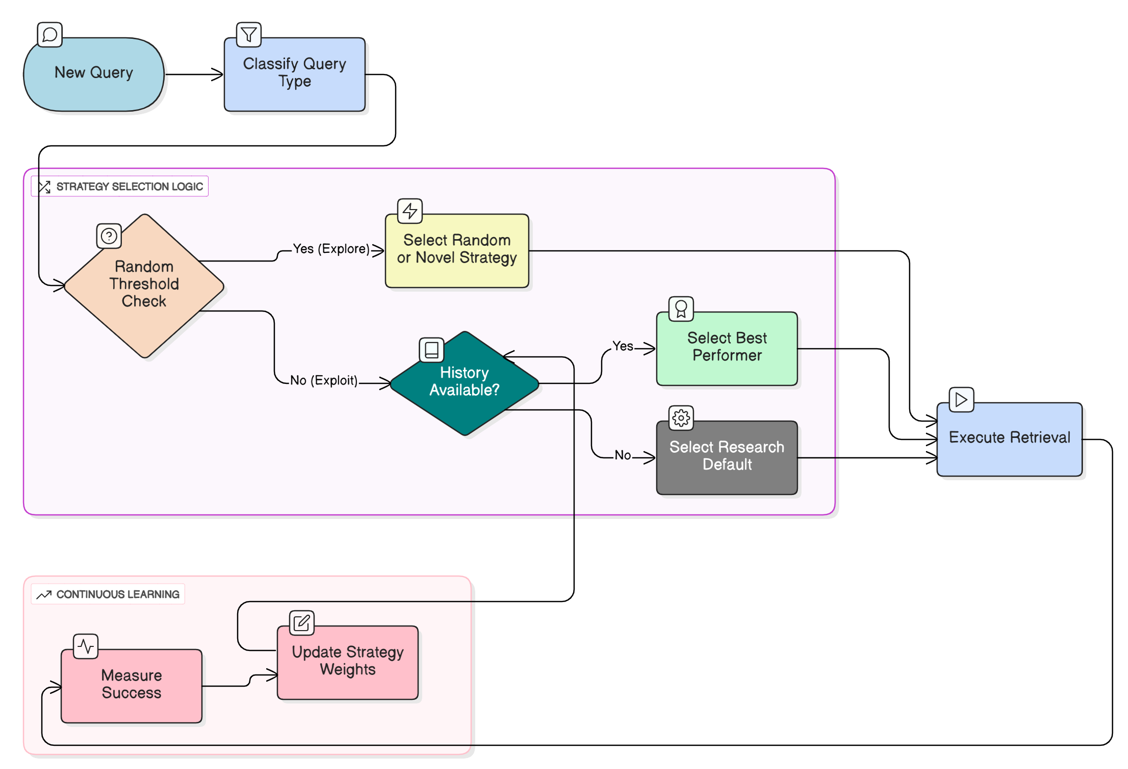
Со временем система накапливает историю производительности. Она отслеживает, какие извлекающие алгоритмы лучше всего работают для каких типов запросов, постоянно обучаясь и совершенствуясь. Если LGraphRAG-Inspired стабильно достигает 92% успеха при выполнении исследовательских запросов, в то время как HippoRAG — только 78%, маршрутизатор учится отдавать предпочтение LGraphRAG для этих вопросов.
Пример из реальной жизни
Позвольте мне продемонстрировать это на практике с помощью реального запроса из нашей системы. Пользователь спросил: «Как CO2 вызывает закисление океана и влияет на морскую жизнь?»
Классификатор сразу же распознал это как многошаговый вопрос. Он запрашивает не простое определение, а цепочку причинно-следственных связей. Маршрутизатор обратился к своему реестру и выбрал LGraphRAG-Inspired, поскольку этот инструмент поиска отлично справляется с отслеживанием причинно-следственных связей в графе знаний.
Затем LGraphRAG применил двухэтапную стратегию. Во-первых, он выполнил векторный поиск для обнаружения семантически схожего контента о CO2, закислении океана и морской жизни. Одновременно он обошел граф знаний, следуя связям: CO2 → ПРИЧИНЫ → Закисление океана → ПОСЛЕДСТВИЯ → Морская жизнь. Он обнаружил, что при растворении CO2 в морской воде образуется угольная кислота, снижающая уровень pH, что, в свою очередь, повреждает коралловые рифы и нарушает морские экосистемы.
Система выдала исчерпывающий ответ, объясняющий всю причинно-следственную связь, а затем сделала нечто решающее — зафиксировала этот успех. В следующий раз, когда кто-то задаст аналогичный вопрос о многошаговом маршруте, маршрутизатор будет еще увереннее в выборе LGraphRAG-Inspired.
Граница Парето: баланс между точностью и стоимостью
Одна из самых сложных особенностей нашей системы — это баланс между точностью и стоимостью. Не для каждого вопроса нужен самый дорогой помощник, и не для каждого вопроса подойдет самый дешевый. Для поиска оптимальных помощников система использует концепцию из экономики, называемую границей Парето.
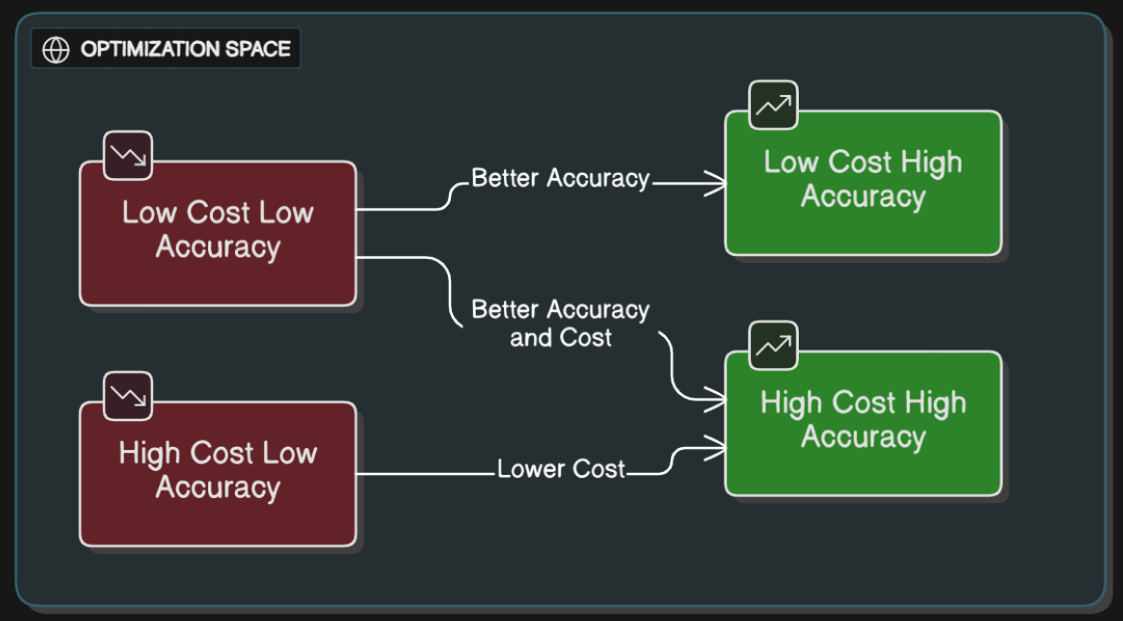
Представьте, что вы расположили все наши устройства для извлечения данных на графике, где по одной оси отложена точность, а по другой — стоимость. Некоторые устройства явно лучше других: они либо точнее при той же стоимости, либо дешевле при той же точности. Эти превосходные устройства образуют то, что мы называем границей Парето. Когда маршрутизатор выбирает устройство для извлечения данных, он рассматривает только варианты, находящиеся на этой границе, гарантируя, что вы никогда не переплатите за меньшую производительность.
Для простого вопроса, например, «Что такое изменение климата?», маршрутизатор может выбрать VanillaRAG из числа существующих алгоритмов, поскольку он дешев и достаточно точен. Для более сложного аналитического запроса он может выбрать LGraphRAG-Inspired, смирившись с более высокой стоимостью, поскольку повышение точности того стоит.
Прозрачность посредством индикаторов пользовательского интерфейса
Одним из важнейших аспектов нашей системы является прозрачность. Пользователи могут точно видеть, что происходит за кулисами. Когда система использует когнитивный поиск, появляется значок, указывающий, какой именно инструмент был выбран. Для нашего климатического запроса пользователи видят «Когнитивная стратегия: вдохновлена LGraphRAG», а также индикаторы, показывающие, что были использованы как инструмент векторного поиска, так и инструмент обхода графа.
Такая прозрачность служит нескольким целям. Пользователи понимают, почему получают именно такой ответ. Разработчики могут отлаживать и оптимизировать систему. А исследователи могут подтвердить обоснованность решений по маршрутизации. Когда кто-то видит, что его сложный многошаговый вопрос сработал по алгоритму LGraphRAG-Inspired, в то время как его простой фактический вопрос использовал алгоритм VanillaRAG, он убеждается в том, что система принимает разумные решения.
Прозрачный API
«Черный ящик» опасен в производственной среде. Пользователям необходимо знать, почему система работает долго или почему она выбрала тот или иной ответ. Мы модифицировали нашу потоковую точку доступа, чтобы она отправляла события метаданных вместе с текстовыми токенами.
async def stream_query_endpoint ( query: str ):
# Маршрутизация стратегии запроса
, metadata = router.route(query)
# Сначала генерируем событие стратегии
yield f"event: strategy\ndata: {json.dumps({
'retriever_name' : metadata[ 'retriever_name' ],
'tools_used' : metadata[ 'tools_used' ],
'reasoning' : 'Selected LGraphRAG for multi-hop complexity'
} )}\n\n"
# Выполнение и потоковая передача фрагментов
async for chunk in strategy.execute_stream(query):
yield f"event: token\ndata: {chunk} \n\n"
Обучение и адаптация
Маршрутизатор поддерживает показатели успешности для каждой комбинации типа запроса и средства поиска. Если он замечает, что HippoRAG-Inspired демонстрирует исключительно хорошие результаты в вопросах, основанных на полноте ответа, касающихся климатических данных, он начнет отдавать предпочтение этому средству поиска для аналогичных вопросов. И наоборот, если средство поиска постоянно показывает низкие результаты для определенных типов запросов, маршрутизатор учится избегать этой пары.
Обучение происходит автоматически, без ручного вмешательства. Эпсилон-жадный подход к исследованию гарантирует, что система никогда не перестает учиться; десятипроцентный показатель исследования означает, что она постоянно тестирует новые комбинации, постоянно ищет лучшие решения.
Влияние на пользовательский опыт
С точки зрения пользователя, вся эта сложность незаметна. Он задает вопрос и получает ответ. Но качество этого ответа значительно улучшается благодаря маршрутизации, основанной на научных исследованиях.
Рассмотрим два сценария. В первом пользователь спрашивает: «Что такое глобальное потепление?» Без интеллектуальной маршрутизации система могла бы использовать алгоритм, вдохновленный LGraphRAG, потратив 2500 токенов и 1200 миллисекунд на ответ на простой вопрос. Ответ был бы правильным, но неэффективным. При использовании маршрутизации, основанной на научных исследованиях, система распознает это как простой фактический запрос и использует алгоритм VanillaRAG вместо 400 миллисекунд, 1000 токенов и той же точности. Пользователь получает ответ быстрее, а система работает эффективнее.
Во втором сценарии пользователь спрашивает: «Объясните цепную реакцию: парниковые газы удерживают тепло, которое растапливает лед, что приводит к повышению уровня моря и угрожает прибрежным городам». Без интеллектуальной маршрутизации система могла бы использовать VanillaRAG, которая испытывала бы трудности с многошаговым анализом. Она могла бы возвращать разрозненные факты по каждой теме, не объясняя причинно-следственную связь. С помощью LGraphRAG-Inspired система отслеживает всю цепочку через граф знаний, предоставляя исчерпывающее объяснение того, как каждый шаг ведет к следующему.
Что может пойти не так (и почему это допустимо)
Ни одна адаптивная система не идеальна. Cognitive GraphRAG вводит новые компромиссы:
- Эффекты холодного старта: На ранних этапах принятия решений по маршрутизации могут быть неточными данные, пока не будет собрана достаточная информация об истории производительности.
- Затраты на исследование: Стратегия «эпсилон-жадности» иногда выбирает неоптимальных рекрутеров для сбора сигналов обучения, что незначительно увеличивает задержку.
- Зависимость от графа: качество многошагового рассуждения ограничено полнотой графа и точностью установления связей.
- Риск неправильной классификации: Неправильная классификация запросов может привести к перенаправлению запросов на менее оптимальные стратегии.
Эти риски являются результатом целенаправленных проектных решений. На практике прозрачность, мониторинг и непрерывное обучение позволяют снизить их со временем, а преимущества значительно перевешивают затраты при решении сложных, реальных задач.
Этот раздел мгновенно повышает статус публикации с «крутая система» до «инженерное решение производственного уровня».
Заключение
Cognitive GraphRAG представляет собой фундаментальный сдвиг в нашем понимании систем поиска информации. Вместо универсального решения мы предлагаем набор специализированных методов, каждый из которых подкреплен опубликованными исследованиями и оптимизирован для конкретных сценариев. Вместо статических конфигураций мы предлагаем обучающуюся систему, которая постоянно совершенствуется. Вместо решений, принимаемых «черным ящиком», мы предлагаем прозрачные индикаторы, точно показывающие пользователям, что происходит.
Когда вы видите в нашей системе значок «Когнитивная стратегия: вдохновлена LGraphRAG», это не просто украшение. Это свидетельство того, что система проанализировала ваш вопрос, обратилась к подтвержденным исследованиями данным о производительности, выбрала оптимальный метод поиска и теперь использует сложные методы анализа графов для нахождения ответа. Это разница между системой, которая просто старается изо всех сил, и системой, которая знает, что означает «идеально» для вашего конкретного вопроса.
Будущее RAG заключается не в поиске единственного наилучшего метода поиска. Речь идёт о создании систем, достаточно интеллектуальных, чтобы выбирать правильный метод для каждого вопроса, опираясь на исследования, подтверждая данные и постоянно обучаясь на собственном опыте. Именно это и предлагает Cognitive GraphRAG.
Вдохновение для исследований
Данная система вдохновлена и развивает идеи, почерпнутые из недавних работ в области поиска информации с использованием графов и памяти, в том числе:
- Подходы GraphRAG, ориентированные на LLM, разработанные Microsoft Research.
- Система HippoRAG (извлечение информации, основанное на памяти) Стэнфордского университета
- Системы глубокого анализа графов в стиле GraphReader