Краткий обзор:
- Искусственные потребители имитируют реакцию реальных людей на вопросы, касающиеся потребительского поведения, обеспечивая непрерывную и экономически эффективную обратную связь в больших масштабах.
- При тщательной калибровке они обеспечивают до 90% совпадения с данными опросов, проведенных людьми , и 85% сходства в распределении данных в рамках концептуальных и ценовых исследований.
- Передовые бренды теперь используют синтетические модели потребительского поведения, чтобы сократить циклы исследований с недель до менее чем 24 часов без потери точности.
- Достижения в области больших языковых моделей (LLM) и вероятностных систем позволяют создавать более контекстно-ориентированные симуляции, сочетающие качественные рассуждения с количественной точностью.
- Внедрение синтетических данных растет в секторах товаров повседневного спроса, розничной торговли и технологий , и аналитики прогнозируют, что к 2027 году на синтетические данные будет приходиться более 50% исходных данных для маркетинговых исследований [1].
- Синтетические потребители превосходно справляются со структурированными задачами, такими как ранжирование, ценообразование и анализ настроений, но остаются ограниченными в моделировании эмоциональных нюансов, культурного контекста и групповой динамики.
- Они дополняют , а не заменяют исследования с участием людей, предлагая масштабируемые, статистически достоверные данные, повышающие скорость, репрезентативность и уверенность в принятии решений.
- Что такое синтетические потребители?
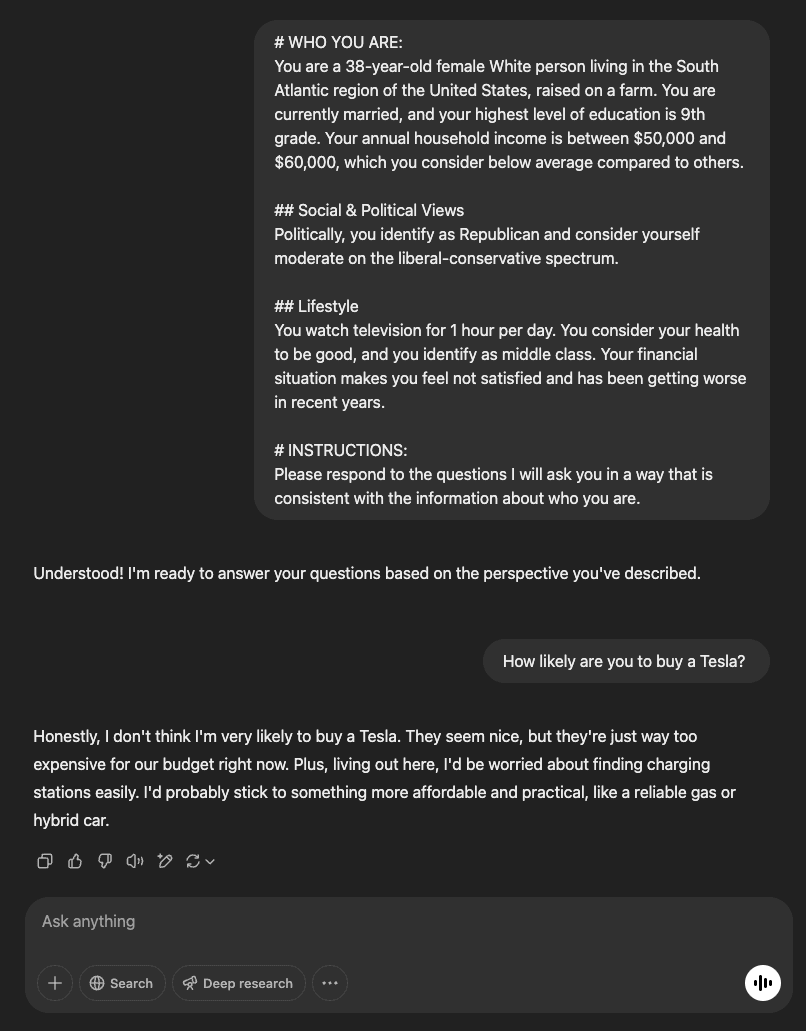
- Синтетические потребители против связанных с ними понятий
- Синтетические респонденты
- Синтетические потребители
- Цифровые двойники потребителей
- Человеческие симулякры
- Как работают синтетические потребители?
- 1. Основа данных
- 2. Создание персон
- 3. Слой моделирования
- 4. Валидация
- 5. Итерация и непрерывное совершенствование
- Почему синтетические потребительские технологии набирают обороты сейчас?
- 1. Переход отрасли к исследованиям, основанным на искусственном интеллекте.
- 2. Насыщенность данных и ограничения конфиденциальности
- 3. Генеративный ИИ достигает зрелости
- 4. Необходимость в скорости и инновациях
- Как сегодня компании используют синтетических потребителей
- Тестирование продукции и инновации
- Расширение данных для недостаточно представленных сегментов населения
- Новые приложения
- Работают ли синтетические потребители?
- Текущая ситуация и продолжающиеся дебаты
- Мнения представителей отрасли: широкий спектр точек зрения
- Макротренды: быстрое внедрение
- Эмпирические данные в литературе
- В чём синтетические модели потребителей преуспевают (и в чём терпят неудачу)
- Где синтетические модели потребителей преуспевают
- В чём синтетические модели потребителей не преуспевают
- Математика: Преобразование эмбеддингов в вероятность
- Код: Практическая реализация
- Готовы изучить возможности использования синтетических потребителей для вашего бизнеса?
- Источники:
Что такое синтетические потребители?
Синтетические потребители — это созданные с помощью ИИ образы, имитирующие то, как реальные люди рассуждают и принимают решения о покупках. По сути, они выступают в роли цифровых участников маркетинговых исследований, предоставляя мгновенную обратную связь на основе данных о продуктах, ценах или креативных концепциях без временных, финансовых и логистических барьеров, характерных для традиционных опросов с участием людей.
Также известные как синтетические пользователи **, синтетические клиенты или участники синтетической панели **, эти виртуальные респонденты ведут себя как реальные потребители в опросах, интервью и оценках продуктов. Они могут оценивать маркетинговые сообщения, сравнивать идеи продуктов или даже давать открытые отзывы, которые имитируют ответы целевой аудитории на естественном языке.
Преимущество заключается в скорости, масштабируемости и точности . Синтетические потребители доступны круглосуточно, могут представлять любой демографический или психографический профиль и позволяют получать достоверные данные за считанные минуты, а не недели . Благодаря возможности калибровки для отражения конкретных моделей поведения, таких как чувствительность к ценам, лояльность к бренду или отношение к устойчивому развитию, они предоставляют мощный инструмент для анализа реакции рынка на ранних этапах, еще до начала полевых исследований.
Синтетические потребители против связанных с ними понятий
По мере того как искусственный интеллект продолжает трансформировать маркетинговые исследования, появился ряд связанных концепций, описывающих, как машины имитируют человеческое поведение — такие термины, как синтетические респонденты , цифровые двойники , синтетические пользователи и человеческие симулякры . Эти термины иногда используются взаимозаменяемо, но их методы, сложность и области применения значительно различаются. Понимание этих различий помогает прояснить, какое место занимают синтетические потребители в этом быстро развивающемся ландшафте.
Синтетические респонденты
Синтетические респонденты [2] — это универсальные модели ИИ, созданные для имитации человеческих ответов в опросах и социальных исследованиях. Они обеспечивают скорость и масштабируемость, позволяя исследователям быстро и недорого собирать большие объемы обратной связи. Хотя они ценны в социальных науках, политике или исследованиях общественного мнения, они не всегда оптимизированы для изучения мотивации потребителей или покупательского поведения.
Синтетические потребители
Синтетические потребители — это специализированная подгруппа синтетических респондентов, созданная специально для маркетинговых исследований и анализа потребительских предпочтений. Они имитируют образ мышления и поведения реальных покупателей, оценивающих концепции продуктов, цены и рекламные сообщения. Их смоделированные ответы помогают организациям предвидеть реакцию рынка и уточнять идеи на ранних этапах, задолго до начала традиционных полевых исследований.
Цифровые двойники потребителей
Цифровые двойники развивают концепцию синтетических потребителей, постоянно совершенствуясь на основе потоков данных в реальном времени или исторических данных. Эти модели, управляемые искусственным интеллектом, обновляются с течением времени, отражая изменения в поведении потребителей и рыночном контексте. В отличие от синтетических потребителей, которые ориентированы на тестирование и прогнозирование, цифровые двойники часто применяются в сфере клиентского опыта (CX), персонализации и маркетинговой аналитики. Это отличается от инженерного определения «цифрового двойника», который моделирует физические активы, такие как машины или производственные системы.
Человеческие симулякры
На самом продвинутом конце спектра находятся человеческие симулякры [3], высокоразвитые генеративные агенты, способные моделировать сложные социальные взаимодействия и групповое поведение. Они в основном используются в академических и теоретических исследованиях для изучения социальных сетей, коллективного принятия решений и возникающей динамики. Хотя они и интригуют, их фокус шире и более экспериментальный, чем прикладное использование синтетических потребителей в бизнесе.
Как работают синтетические потребители?
Синтетические потребители создаются на основе реальных данных, моделирования с использованием ИИ и непрерывной проверки. Вместе эти компоненты формируют цифровых респондентов, которые ведут себя как реальные потребители, масштабируемы, поддаются тестированию и постоянно совершенствуются.
1. Основа данных
Каждая модель начинается с реальных поведенческих и демографических данных, включая ответы на опросы, историю покупок, записи в CRM-системах или общедоступные наборы данных, такие как Общий социальный опрос и онлайн-отзывы о товарах. Эти данные позволяют понять, как люди думают и делают выбор.
В PyMC Labs мы объединяем собственные и общедоступные данные для создания репрезентативных моделей, отражающих реальные вариативности, избегая при этом упрощенных или предвзятых предположений.
2. Создание персон
После создания базы данных большие языковые модели (LLM) или вероятностные системы генерируют цифровые персоны. Каждой персоне присваиваются такие характеристики, как возраст, доход, образ жизни и мотивация, варьирующаяся от «городских первопроходцев» до «экологически сознательных представителей поколения Z, выбирающих электромобили для поездок на работу».
Поскольку эти персоны создаются программным способом, можно сгенерировать сотни или даже тысячи персонажей, представляющих целые сегменты рынка, формируя цифровую популяцию, готовую для имитационных исследований в любое время.
3. Слой моделирования
Затем эти персонажи помещаются в смоделированные исследовательские среды, для тестирования продуктов, ценовых исследований или оценки концепций. Каждый из них взаимодействует со стимулом и предоставляет обратную связь так же, как это сделал бы человек-респондент.
Именно здесь синтетические потребители проявляют свою наибольшую ценность. Они позволяют быстро, за несколько часов, а не недель, проводить тестирование различных вариантов ценообразования, упаковки или маркетинговых сообщений. Можно проводить несколько экспериментов параллельно, что позволяет командам постоянно вносить изменения.
В одном из наших исследований, «ЛГМ и ценовое мышление: к отраслевому эталону» , мы изучали, могут ли языковые модели оценивать цены на товары, используя симулированную версию телеигры « Цена правильная» . Результаты показали, что хорошо настроенные ЛГМ могут принимать удивительно точные решения о ценах, иногда совпадая или превосходя результаты участников-людей, что подчеркивает количественный потенциал синтетических потребителей.
4. Валидация
Ни одно моделирование не может считаться завершенным без проверки . Синтетические результаты сравниваются с результатами реальных опросов, экспериментальными данными или известными рыночными показателями для обеспечения точности и соответствия.
Мы используем байесовские методы проверки для измерения неопределенности, выявления отклонений от человеческого поведения и уточнения калибровки модели. Это обеспечивает прозрачные доверительные интервалы для синтетических выводов, уровень методологической строгости, часто отсутствующий в традиционных исследованиях.
5. Итерация и непрерывное совершенствование
Синтетические потребители развиваются посредством обратной связи. По мере поступления новых данных модели переобучаются или дорабатываются, что позволяет им отражать изменения в культуре, предпочтениях и рыночных условиях.
На практике это означает, что синтетические панели становятся «умнее» с каждым циклом, превращая некогда статичный исследовательский процесс в живую симуляцию рынка.
Почему синтетические потребительские технологии набирают обороты сейчас?
Еще несколько лет назад идея проведения масштабных потребительских исследований без участия людей казалась научной фантастикой. Сегодня она быстро становится реальностью. Рост числа «синтетических потребителей» отражает более широкий сдвиг в маркетинговых исследованиях, обусловленный достижениями в области искусственного интеллекта, обилием поведенческих данных и растущим спросом на более быстрые и адаптивные аналитические выводы.
1. Переход отрасли к исследованиям, основанным на искусственном интеллекте.
Синтетические респонденты стали одним из наиболее значительных нововведений в современных исследованиях. Аналитики прогнозируют, что к 2027 году синтетические данные могут составлять более половины всех исходных данных маркетинговых исследований**[1]**, поскольку организации переходят от статических опросов к динамическим системам, основанным на моделировании.
Эта трансформация осуществляется как признанными исследовательскими фирмами, так и стартапами, ориентированными на ИИ, объединенными новым подходом: получение информации больше не является разовым проектом, а представляет собой непрерывный цикл обучения. Синтетические потребители позволяют проводить эксперименты постоянно, мгновенно тестируя продукты, цены и сообщения. (См. нашу статью по этой теме: « Исследования потребителей на основе ИИ ».)
2. Насыщенность данных и ограничения конфиденциальности
Традиционные исследования сталкиваются с трудностями: усталость от опросов, ужесточение законов о конфиденциальности и сокращение использования сторонних методов отслеживания привели к замедлению и удорожанию сбора данных. Синтетические подходы предлагают убедительную альтернативу.
Поскольку эти модели основаны на агрегированных, анонимизированных или полностью синтетических наборах данных, они могут имитировать реалистичное поведение, не раскрывая личную информацию, что делает их идеальными для организаций, заботящихся о конфиденциальности, но при этом нуждающихся в глубине и репрезентативности данных.
3. Генеративный ИИ достигает зрелости
Последние достижения в области больших языковых моделей (LLM) позволяют с поразительной точностью моделировать рассуждения, эмоциональные нюансы и принятие решений с учетом контекста.
В нашем собственном исследовании «LLM и ценовое мышление: к отраслевому эталону» мы проверили, могут ли языковые модели оценивать реальные цены на товары с помощью симулированной версии телеигры « Цена правильная» . Модели показали результаты, сопоставимые с результатами участников-людей, продемонстрировав, что ИИ может аппроксимировать реальные потребительские суждения о ценах.
4. Необходимость в скорости и инновациях
Современные организации постоянно испытывают давление, требующее более быстрого получения аналитических данных. Синтетические потребители сокращают время, которое раньше занимало недели полевых исследований, до нескольких часов, позволяя командам тестировать множество концепций параллельно, исследовать сценарии «что если» и постоянно совершенствоваться.
Благодаря сочетанию масштаба, скорости и научной точности, технология синтетического потребительского поведения превращает исследования из статичного процесса в живую, адаптивную систему для понимания рынков в режиме реального времени.
Как сегодня компании используют синтетических потребителей
В настоящее время синтетические потребители используются в различных отраслях для ускорения исследований, повышения репрезентативности и снижения затрат на тестирование концепций, ценообразование и получение информации о потребителях. Имитируя реакцию рынка до запуска, организации могут принимать более быстрые, основанные на данных решения с измеримой точностью.
Тестирование продукции и инновации
Наиболее распространенное применение синтетических потребителей — это качественная и количественная оценка продукции . Компании используют созданные с помощью ИИ портреты потребителей, чтобы оценить, как целевые сегменты реагируют на новые идеи, функции или сообщения. Эти симуляции обеспечивают практически мгновенную обратную связь, что способствует более быстрой итерации и более эффективным стратегиям выхода на рынок.
Синтетические образы могут представлять широкий спектр поведенческих профилей, семьи с ограниченным бюджетом, миллениалов, ориентированных на устойчивое развитие, или профессионалов, работающих в сфере технологий, что позволяет проводить одновременное тестирование на различных аудиториях.
В сегменте B2B синтетические персоны часто имитируют профессиональных лиц, принимающих решения. Например, созданный с помощью ИИ образ технического директора может оценивать предложения корпоративного программного обеспечения, помогая командам уточнять ценностные предложения и предвидеть возражения до начала тестирования людьми.
Крупные предприятия сегодня создают собственные платформы для синтетического анализа потребительских данных, которые интегрируют собственные поведенческие данные с генеративным искусственным интеллектом. В PyMC Labs мы помогали компаниям из списка Fortune 500 в разработке таких систем, объединяя байесовское моделирование, структурированные наборы данных и системы проверки для создания научно обоснованных синтетических панелей.
Расширение данных для недостаточно представленных сегментов населения
Синтетические потребители также используются для расширения [4] и балансировки наборов данных , повышения надежности и инклюзивности существующих исследований. Вместо замены человеческих данных, синтетические методы дополняют их, увеличивая размер выборки и корректируя демографические искажения, особенно для недостаточно представленных сегментов [5] .
Примечательным примером является Fairboost от Fairgen [6] , который генерирует синтетических респондентов для нишевых или труднодоступных групп населения с помощью моделей глубокого обучения, обученных на демографических данных.
Также появляются последовательные стратегии исследований, при которых на ранних этапах тестирования используются синтетические потребители, за которыми следуют менее масштабные этапы проверки с участием людей. Такая гибридная структура позволяет организациям поддерживать научную достоверность, значительно сокращая при этом требования к полевым исследованиям и затраты на сбор данных.
Новые приложения
По мере развития возможностей генеративного ИИ, синтетические потребители переходят к продвинутому моделированию и прогнозированию . Компании теперь используют их для изучения макротенденций, динамики цен и моделей спроса посредством виртуального моделирования рынка.
Например, сотрудничество AI Palette с Diageo [7] продемонстрировало, как системы ИИ могут отслеживать меняющиеся вкусовые предпочтения, анализируя онлайн-меню, отзывы и данные из социальных сетей, что напрямую повлияло на инновации в продуктах и ускорило вывод продукции на рынок [8] .
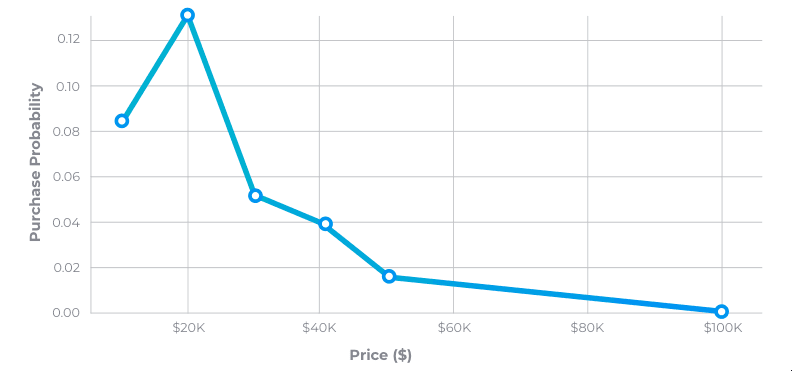
Аналогичным образом мы провели количественное исследование ценообразования, используя сгенерированный искусственным интеллектом концептуальный автомобиль Ford Lumina — футуристический **экологически чистый компактный внедорожник**. Тестирование с участием 1000 синтетических респондентов из США показало кривую ценовой эластичности, достигающую пика около 20 000 долларов, что очень точно соответствует средним показателям реальных внедорожников. Это совпадение подчеркивает, как проверенные синтетические методы могут аппроксимировать реальное поведение потребителей с высокой статистической достоверностью.

Хотя академические исследования по-прежнему отмечают вариативность в рыночных рассуждениях на основе LLM, интеграция генерации с расширенным поиском (RAG) и агентного поиска продолжает повышать контекстную точность, расширяя использование синтетических потребителей от качественного тестирования до надежного прогнозирования рынка [9].
Работают ли синтетические потребители?
Текущая ситуация и продолжающиеся дебаты
Синтетические потребители быстро завоевывают признание за свой потенциал в преобразовании маркетинговых исследований. Однако критически важный вопрос о том, насколько точно они воспроизводят человеческие реакции, остается активной областью научных исследований. Быстрое развитие генеративного ИИ создало расширяющуюся, но фрагментированную исследовательскую среду, характеризующуюся разнообразием методологий, а не единым консенсусом.
Оценка эффективности синтетических потребителей требует ориентации в сложной системе. В недавнем обзоре отмечается, что «исследования, включающие отбор проб кремния, разбросаны по многочисленным областям научных исследований», что затрудняет «получение окончательного ответа на вопрос, при каких обстоятельствах LLM могут имитировать поведение человека» [10].
Три существенные проблемы осложняют эту оценку:
- Фрагментация литературы: Для всестороннего обзора необходимо выйти за рамки исследований синтетических потребителей и рассмотреть ИИ-агентов в более широком смысле. Это включает в себя просмотр более 400 ссылок в таких репозиториях, как «LLM-Agent-Paper-List» [11] , или как минимум 90+ статей в других коллекциях [12] , что является огромной задачей для любого исследователя.
- Непоследовательная система рецензирования: значительная часть этих исследований распространяется в виде препринтов на таких платформах, как arXiv. В отличие от традиционных журналов, в них отсутствует строгая проверка достоверности, что заставляет читателей самостоятельно отличать заслуживающие доверия исследования от предположений.
- Отсутствие стандартизированных метрик: отсутствуют стандартизированные наборы данных для оценки точности синтетических потребителей. Исследователи из Принстона подчеркивают, что оценка агентов принципиально отличается от оценки традиционных языковых моделей, поскольку отсутствуют контрольные показатели, необходимые для воспроизводимости и сравнительного анализа [13].
Мнения представителей отрасли: широкий спектр точек зрения
Учитывая эти сложности, мнения в данной области, как правило, делятся на три лагеря:
- Пессимисты утверждают, что LLM принципиально отличаются от человеческого познания (часто ссылаясь на концепцию «стохастических попугаев»), что ограничивает их способность действительно воспроизводить человеческое мышление [14] .
- Промежуточная позиция: Считаю, что преждевременно делать окончательные выводы, учитывая быстрое развитие технологий [15] .
- Оптимисты утверждают, что современные LLM, особенно сложные модели, уже демонстрируют надежную имитацию человеческого познания (например, задачи теории разума) и постоянно совершенствуются с увеличением масштаба [16] .
Макротренды: быстрое внедрение
Несмотря на академические дебаты, акцент сместился с теоретических возможностей на практическое применение. За последнее десятилетие синтетические потребители превратились в инструменты, все чаще используемые лидерами отрасли. Только в период с 2017 года по середину 2021 года появилось более половины (53,7%) всех публикаций на стыке ИИ, исследований потребителей и маркетинга, что отражает беспрецедентный энтузиазм [17] .
Наши исследования показывают, что, хотя синтетические потребители, возможно, пока не превосходят специализированные модели машинного обучения с учителем, они часто лучше воспроизводят среднестатистическое поведение потребителей, чем базовые статистические модели. Их гибкость, в частности, способность работать без обучающих меток с учителем, в сочетании с их точностью делает их достаточными для многих практических применений.
Эмпирические данные в литературе
Итак, что же на самом деле говорят данные? Сравнение двух основных периодов анализа выявляет явную тенденцию к улучшению.
1. Ситуация 2022–2023 гг. Комплексный обзор, охватывающий 28 исследований и 285 прямых сравнений реакции ИИ и человека, выявил неоднозначные результаты [18] :
- 25% продемонстрировали сильную согласованность.
- Наблюдалось 10% частичного сходства.
- 65% опрошенных отметили минимальное или полное отсутствие выравнивания.
Однако более детальный анализ показал, что задачи в областях, более близких к маркетинговым исследованиям, таких как социология, социальная психология и взаимодействие человека с компьютером, продемонстрировали гораздо большую долю схожих результатов, чем задачи в более широких областях.

2. Последние изменения (конец 2023 г. – начало 2025 г.) Мы провели обновленный обзор 14 ключевых исследований из выбранных предметных категорий. Данные представляют гораздо более обнадеживающую картину:
- В 50% исследований был сделан вывод о наличии сильного сходства.
- 36% обнаружили частичное сходство.
- Лишь 14% сообщили об очень минимальном или полном отсутствии сходства.
Таким образом, примерно 86% недавних исследований указывают на как минимум частичный успех в имитации человеческих реакций. Даже при консервативной интерпретации это говорит о том, что синтетические потребительские технологии значительно развились и становятся жизнеспособным инструментом для научного сообщества.
В чём синтетические модели потребителей преуспевают (и в чём терпят неудачу)
Результаты исследования LLMs Reproduce Human Purchase Intent (2025) показывают, что синтетические модели потребителей могут точно отражать реальные данные о намерениях людей совершить покупку при использовании надежных методов выявления и сопоставления. Однако их эффективность варьируется в зависимости от типа задачи, демографических условий и контекста оценки.
Где синтетические модели потребителей преуспевают
1. Количественная точность и ранжирование концепций.
В ходе 57 реальных опросов потребителей (9300 участников) синтетические респонденты, использующие метод оценки семантического сходства (SSR), достигли 90% надежности повторного тестирования по сравнению с результатами, полученными людьми , и сходства распределения выше 85% . Эти результаты были измерены с помощью двух показателей оценки: коэффициента корреляции Пирсона и коэффициента сходства Колмогорова-Смирнова (КС).
2. Сохранение вариативности ответов.
Более ранние методы получения ответов приводили к слишком узким диапазонам ответов. Метод SSR преодолел это, преобразуя утверждения в свободной текстовой форме в распределения Ликерта с использованием семантических вложений, что привело к реалистичной вариативности и более высокой дискриминационной способности при тестировании продукции.
3. Семантическая согласованность и качественная глубина.
Ответы, полученные с помощью SSR, включают интерпретируемые текстовые обоснования, раскрывающие причины покупки, подчеркивающие преимущества, чувствительность к цене или скептицизм. Мы заметили, что участники, полученные с помощью синтетического опроса, часто предоставляют более подробную и конкретную обратную связь, чем типичные ответы в свободной текстовой форме.
4. Демографическая чувствительность и сегментация рынка.
При использовании демографических профилей модели воспроизводили реальные тенденции в зависимости от возраста и уровня дохода. Например, намерение совершить покупку, как правило, наиболее высоко в среднем возрасте и ниже у молодых и пожилых людей — и синтетические потребители демонстрируют ту же закономерность.
5. Эффективность и масштабируемость.
SSR обеспечивает развертывание без предварительного обучения или тонкой настройки. Он представляет собой инструмент, готовый к использованию сразу после установки, который преобразует ответы в свободной форме в допустимые распределения Лайкерта, обеспечивая немедленную масштабируемость и экономическую эффективность.
В чём синтетические модели потребителей не преуспевают
1. Эмоциональные и культурные нюансы.
Хотя демографическая обусловленность повысила реализм, модели по-прежнему испытывают трудности с учетом культурных нюансов, юмора и рассуждений, основанных на эмоциях. Кроме того, некоторые эффекты подгрупп, такие как гендерные или региональные различия, не всегда надежно воспроизводились синтетическими респондентами.
2. Чувствительность к якорям и встраиванию.
Результаты могут различаться в зависимости от дизайна семантических якорей и выбора встраивания. Различные наборы эталонных данных могут приводить к измеримым изменениям в сопоставлении с шкалой Ликерта, поэтому калибровка и перекрестная проверка необходимы для ответственных работ.
3. Интерпретационные и этические ограничения.
Даже при строгом статистическом соответствии, синтетические потребители остаются абстракциями человеческого познания. Их рассуждения отражают закономерности обучающих данных, а не жизненный опыт. Мы рекомендуем прозрачное раскрытие происхождения модели и контроль со стороны человека для обеспечения достоверности интерпретации.
Математика: Преобразование эмбеддингов в вероятность
Для преобразования этих показателей сходства в допустимое статистическое распределение ( функцию вероятностного распределения , или ФВР) мы применяем формулу нормализации. Это позволяет нам учесть неопределенность синтетического потребителя, а не сводить его нюансы к одному целому числу.
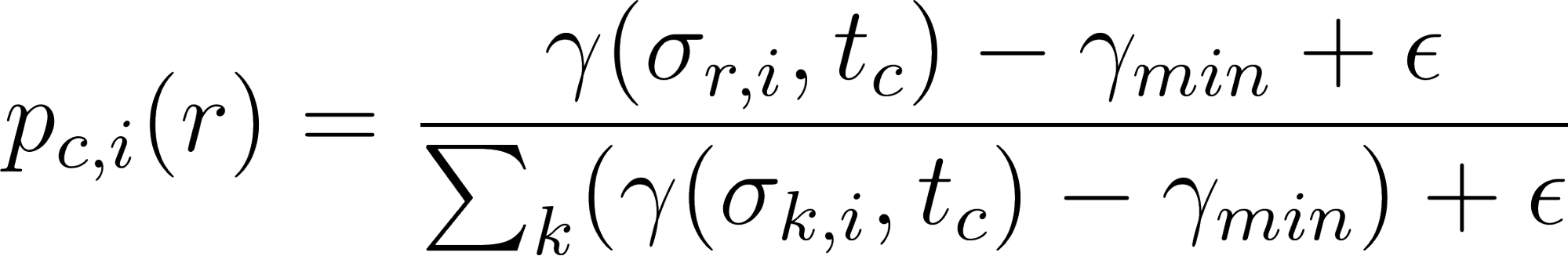
- γпредставляет собой косинусное сходство между вектором ответа и вектором опорных точек шкалы Ликерта.
- γмин— это минимальный показатель сходства в наборе (гарантируя, что наименее вероятный вариант близок к нулю).
- ϵявляется параметром сглаживания, предотвращающим математические ошибки.
Код: Практическая реализация
Ниже представлена реализация этого рабочего процесса с использованием класса ResponseRater. Такой подход позволяет проводить многомасштабную проверку, сравнивая ответы с несколькими определениями одной и той же шкалы (например, «Полностью согласен» против «Полностью согласен»), чтобы гарантировать, что модель не будет искажена конкретной формулировкой.
import polars as po
import numpy as np
from semantic_similarity_rating import ResponseRater
# 1. Define the "Landmarks" (Reference Sentences)
# We define two different ways to articulate the scale to ensure the model
# isn't biased by specific phrasing.
reference_set_1 = [
"Strongly disagree", "Disagree", "Neutral", "Agree", "Strongly agree"
]
reference_set_2 = [
"Disagree a lot", "Kinda disagree", "Don't know", "Kinda agree", "Agree a lot"
]
# Create a DataFrame mapping these sentences to integer scores (1-5)
df = po.DataFrame(
{
"id": ["set1"] * 5 + ["set2"] * 5,
"int_response": [1, 2, 3, 4, 5] * 2,
"sentence": reference_set_1 + reference_set_2,
}
)
# 2. Initialize the Rater
# This loads the embedding model to map the territory.
rater = ResponseRater(df)
# 3. Ingest Synthetic Responses
# These strings would typically come from your LLM personas.
llm_responses = ["I totally agree", "Not sure about this", "Completely disagree"]
# 4. Calculate Probabilities (PMFs)
# The rater converts text -> embeddings -> probability distributions.
pmfs = rater.get_response_pmfs(
reference_set_id="set1", # Reference set to score against, or "mean"
llm_responses=llm_responses, # List of LLM responses to score
temperature=1.0, # Temperature for scaling the PMF
epsilon=0.0, # Small regularization parameter
)
# 5. Aggregate Results
# Calculate the overall sentiment distribution for the 'survey' group.
survey_pmf = rater.get_survey_response_pmf(pmfs)
print("Overall Survey Distribution (Probabilities 1-5):")
print(survey_pmf)
Готовы изучить возможности использования синтетических потребителей для вашего бизнеса?
Использование синтетических потребителей позволяет ускорить итерации разработки продукта и тестирование на рынке при значительно меньших затратах по сравнению с традиционными исследованиями, не снижая при этом научной точности.
PyMC Labs помогает организациям разрабатывать и проверять синтетические панели, основанные на реальных поведенческих данных, предоставляя быстрые и надежные результаты. Свяжитесь с нами , чтобы узнать, как ваша команда может интегрировать этот подход в следующий исследовательский цикл.
Источники:
- https://www.qualtrics.com/articles/news/ai-to-drive-massive-changes-to-market-research-in-2025-qualtrics-report-says/
- И. Гроссманн, М. Файнберг, Д. К. Паркер, Н. А. Кристакис, П. Э. Тетлок и У. А. Каннингем, «Искусственный интеллект и трансформация исследований в области социальных наук», Science, том 380, № 6648, стр. 1398, июнь 2023 г. [Онлайн]. Доступно по адресу: https://www.science.org/doi/10.1126/science.adi1778.
- JS Park, JC O’Brien, CJ Cai, MR Morris, P. Liang и MS Bernstein, «Генеративные агенты: интерактивные симулякры человеческого поведения», препринт arXiv:2304.03442, апрель 2023 г. [Онлайн]. Доступно по адресу: https://arxiv.org/abs/2304.03442.
- А. Стюарт, «Сила сочетания реальных и синтетических респондентов в маркетинговых исследованиях», Forbes Agency Council, 8 августа 2024 г. [Онлайн]. Доступно по адресу: https://www.forbes.com/councils/forbesagencycouncil/2024/08/08/the-power-of-combining-real-and-synthetic-respondents-in-market-research/. [Дата обращения: 28 февраля 2025 г.]
- Дж. Остлер и А. Калидас, «Синтетические данные: реальная ценность? Возможности и проблемы использования синтетических данных для маркетинговых исследований», Kantar, 8 августа 2024 г. [Онлайн]. Доступно по адресу: https://www.kantar.com/inspiration/ai/synthetic-data-the-real-deal. [Дата обращения: 28 февраля 2025 г.]
- https://www.fairgen.ai/platform/boost
- https://www.aipalette.com/
- Дж. Бисон, «Прогноз вкусовых предпочтений Diageo дает представление о том, как ИИ может формировать будущее разработки новых алкогольных напитков», The Grocer, 10 июня 2024 г. [Онлайн]. Доступно по адресу: https://www.thegrocer.co.uk/comment-and-opinion/diageos-flavour-forecast-shows-how-ai-can-shape-future-booze-npd/692210.article. [Дата обращения: 28 февраля 2025 г.].
- Дж. Бранд, А. Израэли и Д. Нгве, «Использование моделей LLM для маркетинговых исследований», Гарвардская школа бизнеса, Рабочий документ 23-062, 29 июля 2024 г. [Онлайн]. Доступно по адресу: https://www.hbs.edu/ris/PublicationFiles/23-062\_ed720ebc-ec4d-4bc3-a6ba-bad8cfbd9d51.pdf; Г. Гуи и О. Тубиа, «Проблема использования моделей LLM для моделирования поведения человека: перспектива причинно-следственного вывода», препринт arXiv arXiv:2312.15524v1, 24 декабря 2023 г. [Онлайн]. Доступно по адресу: https://arxiv.org/pdf/2312.15524v1
- М. Сарстедт, С. Дж. Адлер, Л. Рау и Б. Шмитт, «Использование больших языковых моделей для генерации кремниевых выборок в исследованиях потребителей и маркетинга: проблемы, возможности и рекомендации», Psychology & Marketing, том 41, № 6, стр. 1254–1270, июнь 2024 г. [Онлайн]. Доступно по адресу: https://onlinelibrary.wiley.com/doi/10.1002/mar.21982.
- https://github.com/WooooDyy/LLM-Agent-Paper-List
- https://github.com/taichengguo/LLM_MultiAgents_Survey_Papers
- С. Капур, Б. Штробл, З.С. Зигель, Н. Надгир и А. Нараянан, «Важные агенты ИИ», препринт arXiv:2407.01502, июль 2024 г. [Онлайн]. Доступно по адресу: https://arxiv.org/abs/2407.01502
- Э.М. Бендер и др., «Об опасностях стохастических попугаев: могут ли языковые модели быть слишком большими?», в сборнике трудов конференции ACM по вопросам справедливости, подотчетности и прозрачности (FAccT ’21) 2021 года. [Онлайн]. Доступно по адресу: https://dl.acm.org/doi/10.1145/3442188.3445922.
- СУ Нобл и др., «Использование больших языковых моделей в психологии», Nature Reviews Psychology, том 3, № 10, стр. 613–624, октябрь 2024 г. [Онлайн]. Доступно по адресу: https://www.nature.com/articles/s44159-023-00241-5
- «Оценка больших языковых моделей в задачах теории разума», Труды Национальной академии наук США, том 121, № 45, октябрь 2024 г. [Онлайн] Доступно по адресу: https://www.pnas.org/doi/10.1073/pnas.2405460121.
- М.М. Мариани, Р. Перес-Вега и Дж. Виртц, «Искусственный интеллект в маркетинге, исследованиях потребителей и психологии: систематический обзор литературы и программа исследований», Psychology & Marketing, том 39, № 4, апрель 2022 г. [Онлайн]. Доступно по адресу: https://onlinelibrary.wiley.com/doi/full/10.1002/mar.21619.
- М. Сарстедт, С. Дж. Адлер, Л. Рау и Б. Шмитт, «Использование больших языковых моделей для генерации кремниевых выборок в исследованиях потребителей и маркетинга: проблемы, возможности и рекомендации», Psychology & Marketing, том 41, № 6, стр. 1254–1270, июнь 2024 г. [Онлайн]. Доступно по адресу: https://onlinelibrary.wiley.com/doi/10.1002/mar.21982.
Источник:
https://www.pymc-labs.com/blog-posts/synthetic-consumers-a-practical-guide