В категории векторных баз данных происходят изменения в ответ на потребности агентного ИИ.
Конвейер обработки данных, основанный на генерации с дополненной информацией (RAG) и преобразовании в векторную базу данных, больше не работает; для агентного ИИ требуется иной подход, учитывающий контекст. Опрос VentureBeat Pulse за первый квартал 2026 года подчеркивает эту тенденцию: каждая автономная векторная база данных теряет долю рынка, в то время как доля намерений при гибридном поиске утроилась и достигла 33,3%, став самой быстрорастущей стратегической позицией в наборе данных.
Компания Pinecone, пионер в разработке векторных баз данных, осознает это и меняет свою стратегию, чтобы удовлетворить специфические потребности агентного ИИ.
Сегодня компания анонсировала Nexus, позиционируя его как систему управления знаниями, а не как усовершенствованную версию системы поиска информации. Nexus включает в себя компилятор контекста, который преобразует необработанные корпоративные данные в постоянные, специфичные для конкретной задачи артефакты знаний до того, как агенты начнут их запрашивать, а также компонуемый механизм поиска, который предоставляет эти артефакты с ссылками на уровне полей и детерминированным разрешением конфликтов.
Наряду с Nexus, Pinecone выпускает KnowQL, декларативный язык запросов, который предоставляет агентам словарь для указания формы выходных данных, требований к достоверности и ограничений по задержке. В собственном внутреннем тесте Pinecone одна задача финансового анализа, которая ранее потребляла 2,8 миллиона токенов, была выполнена Nexus всего за 4000. Это представляет собой сокращение на 98%, хотя компания еще не подтвердила это в реальных производственных средах клиентов. Nexus находится в режиме раннего доступа с сегодняшнего дня.
«RAG был создан для пользователей-людей, — сказал генеральный директор Pinecone Эш Ашутош в интервью VentureBeat. — Nexus был создан для пользователей-агентов, потому что их язык совершенно другой. Они ожидают совершенно других ответов. Задача, которую поручают агенту, сильно отличается от того, что должен делать чат-бот».
- Почему RAG изначально не создавалась для того, чем на самом деле занимаются агенты.
- Что такое Nexus и как он работает.
- Что аналитики думают об архитектурном утверждении?
- Конкурентная среда
- Что это значит для предприятий
- Проблема стоимости извлечения носит архитектурный характер.
- Управление — это то, что отличает пилотный проект от внедрения в рабочую среду.
- Бюджет изменился.
Почему RAG изначально не создавалась для того, чем на самом деле занимаются агенты.
RAG включает в себя один запрос, один ответ и человека, участвующего в интерпретации результата. Но агенты работают иначе. Им назначаются задачи, а не вопросы, и для их выполнения требуется сбор контекста из множества источников, разрешение конфликтов, отслеживание уже полученной информации и принятие решения о том, какие запросы следует задавать дальше.
Это различие имеет значение. Конвейер RAG извлекает документы и передает их модели во время вывода. Каждая сессия агента начинается с нуля, без какого-либо скомпилированного понимания корпоративной базы данных — какие таблицы к чему относятся, какие источники являются авторитетными для каких вопросов и какие форматы агент сможет фактически использовать. Каждая сессия заново открывает это с нуля.
«В основе всего этого лежала очень простая проблема, — сказал Ашутош. — Вы просите агентов — машины — работать с системами и данными, которые были разработаны для людей».
По оценкам Pinecone, 85% вычислительных ресурсов агента уходит на цикл повторного обнаружения, а не на выполнение задачи. Последствия этого накапливаются: непредсказуемая задержка, непомерные затраты токенов и непредсказуемые результаты. Если запустить одну и ту же задачу дважды на одних и тех же данных, агент может выдать разные ответы, без указания источников, которые повлияли на тот или иной результат. Для предприятий, где аудит является обязательным требованием соответствия, это структурный недостаток, а не проблема настройки.
Что такое Nexus и как он работает.
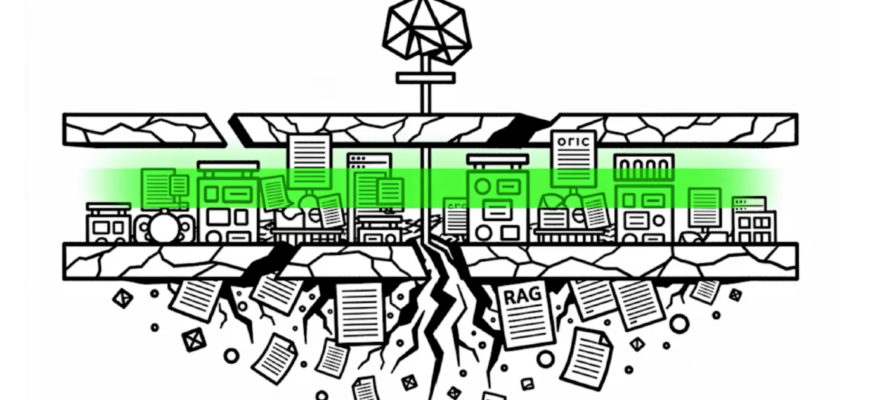
Nexus переносит работу по рассуждениям с этапа вывода на этап компиляции. В традиционном конвейере RAG рассуждения, необходимые для интерпретации, контекстуализации и структурирования знаний, происходят в момент запроса агента — в каждой сессии, каждый раз, расходуя токены на работу, которую можно было бы выполнить заранее. Но Nexus рассуждает только один раз на этапе компиляции, который выполняется перед любым запросом агента, а затем сохраняет результат как многократно используемый артефакт знаний. Агент получает структурированный, готовый к выполнению задачи контекст, а не необработанные документы для интерпретации на лету.
Архитектура, поставляемая компанией Pinecone, состоит из трех отдельных компонентов, каждый из которых решает отдельный уровень задачи поиска агентов.
- Компилятор контекста. Nexus принимает исходные данные и спецификацию задачи и создает специализированные артефакты знаний — структурированные, оптимизированные для задачи представления, которые агенты используют напрямую без дополнительных затрат на интерпретацию. Одна и та же базовая база данных создает разные артефакты для разных агентов: агент по продажам получает контекст сделки, синтезированный из CRM и записей звонков, агент финансового отдела получает контекст дохода, связывающий контракты с графиками выставления счетов. Артефакты сохраняются и используются повторно в разных сессиях агентов, а не генерируются заново во время вывода.
- Компонуемый механизм поиска. Скомпилированные артефакты предоставляются во время запроса с типизированными полями, ссылками на каждое поле с уровнями достоверности и детерминированным разрешением конфликтов. Вывод формируется в соответствии с указанным агентом форматом, а не возвращается в виде необработанного текста для повторного анализа агентом.
- KnowQL. Компания Pinecone описывает его как первый декларативный язык запросов, разработанный для агентов, а не для людей. Шесть примитивов — намерение, фильтр, происхождение, форма выходных данных, достоверность и бюджет — позволяют агентам задавать структурированные ответы, а также параметры привязки источника и задержки в едином интерфейсе. Ашутош сравнил структурный пробел, который заполняет KnowQL, с тем, что SQL сделал для реляционных баз данных: до появления стандартного интерфейса каждое приложение создавало свой собственный уровень доступа к данным с нуля.
Взаимосвязь между Nexus и базовой векторной базой данных Pinecone носит аддитивный характер. Компилятор контекста создает артефакты знаний, которые индексируются и хранятся в векторной базе данных; слой компиляции формирует и предоставляет знания; векторный слой отвечает за хранение, скорость поиска и масштабируемость.
«Векторы по-прежнему хранятся и управляются базой данных векторов Pinecone», — сказал Ашутош.
Что аналитики думают об архитектурном утверждении?
Перенос процесса рассуждений с этапа вывода на этап компиляции — не новая концепция: онтологии, каталоги данных и семантические слои уже много лет используют её в различных вариациях. Изменилась лишь возможность масштабного внедрения этого подхода без привлечения отдельных инженерных групп для каждой предметной области. Именно на этом основан аргумент Nexus, и именно здесь аналитики видят настоящий прогресс.
Стефани Уолтер, руководитель направления разработки стека ИИ в HyperFRAME Research, рассказала VentureBeat, что Nexus имеет важное значение в перспективе, поскольку он переносит работу с знаниями из хаоса во время выполнения в предварительно скомпилированную структуру. Однако она подчеркнула, что это эволюция архитектуры RAG, а не полная ее переработка.
«Настоящая инновация заключается не в самой идее, а в превращении компиляции знаний в первоклассный инфраструктурный слой», — сказал Уолтер. «Если Pinecone сможет надежно внедрить это в практику, это станет значимой инфраструктурой, а не просто еще одним трюком по настройке RAG».
Технический механизм, лежащий в основе этого утверждения, — это то, что аналитик Gartner, вице-президент Арун Чандрасекаран, назвал значимым архитектурным отличием. «В отличие от традиционного RAG, который полагается на чисто семантический поиск во время выполнения, архитектурная компиляция внедряет структурную логику в слой метаданных, что может ускорить время отклика и обеспечить более качественное логическое обоснование», — сказал Чандрасекаран VentureBeat. «Это важный скачок от простого поиска к улучшенному логическому обоснованию, позволяющий агентам ориентироваться в корпоративных схемах и приобретать более качественную память для контекстуализации».
Конкурентная среда
Многие поставщики признают , что векторной базы данных и традиционного алгоритма RAG недостаточно для агентного ИИ.
Microsoft расширила свою технологию FabricIQ , чтобы обеспечить семантический контекст для агентного ИИ. Google недавно анонсировала свою Agentic Data Cloud как подход к решению тех же проблем. Существуют также автономные технологии контекстной памяти, такие как hindsight , которые предоставляют пользователям еще один вариант.
Однако аналитики меньше сосредоточены на сравнении функций, чем на том, что покупатели действительно должны оценивать. «Стек агентного ИИ фрагментируется на десятки функций, но корпоративным покупателям не следует гнаться за функциями, — сказал Уолтер. — Им следует стремиться к контролю: контролю затрат, контролю управления и контролю безопасности».
По ее словам, большинство сбоев в работе предприятий, использующих агентный ИИ, будут не техническими, а операционными — связанными с перерасходом средств, пробелами в управлении и недостаточной дисциплиной в области безопасности.
Критерий оценки возможностей выходит за рамки скорости получения данных. «Настоящее отличие заключается в детерминированной привязке», — сказал Чандрасекаран, указывая на такие методы, как графы знаний, которые гарантируют, что агенты понимают структурные взаимосвязи в корпоративных данных, а не возвращают поверхностные совпадения. Взаимодействие — это еще один важный аспект: стандарты, такие как протокол контекста модели (MCP), важны для подключения агентов к устаревшим источникам данных без создания новых зависимостей.
Что это значит для предприятий
Базы данных RAG и автономные векторные базы данных были созданы для другой эпохи. Сейчас же агентные вычисления выявляют ограничения обеих систем.
Проблема стоимости извлечения носит архитектурный характер.
Команды, обрабатывающие сложные агентные задачи на традиционных конвейерах RAG, тратят ресурсы во время вывода на работу, которую можно было бы выполнить заранее — интерпретацию, контекстуализацию и структурирование знаний с нуля в каждой сессии. Это проблема проектирования. Настройка уровня поиска ее не решит. Вопрос для команд инженеров данных заключается в том, способна ли их текущая структура к предварительной компиляции знаний для конкретных задач агентов, или же она была создана для пользователя-человека, которому эта возможность никогда не требовалась.
Управление — это то, что отличает пилотный проект от внедрения в рабочую среду.
Критерии, определяющие одобрение агентного ИИ для использования в корпоративных системах, не являются показателями производительности.
«Реальная ценность для предприятия заключается не только в более быстром поиске, но и в управляемых каналах обработки знаний», — сказал Уолтер. «Именно эти возможности превращают агентный ИИ из эксперимента в нечто, что финансовые и риск-менеджментные команды действительно одобрят».
Бюджет изменился.
Данные VentureBeat за первый квартал показывают, что инвестиции в оптимизацию поиска информации выросли на 28,9% в марте, впервые за квартал превысив расходы на оценку. Предприятия завершили измерение проблем с поиском информации. Теперь они тратят средства на их решение.
«Будущее агентного ИИ будет определяться не тем, у кого будет самое длительное окно контекста, — сказал Уолтер. — Оно будет определяться тем, кто сможет масштабно внедрять проверенные знания, не увеличивая при этом затраты и не усложняя управление».