
Генеративный искусственный интеллект изменил принципы работы индустрии аналитики. Но когда дело дошло до замены реальных респондентов полностью синтетическими аудиториями, обещания не оправдались. Сэмюэл Коэн утверждает, что пора отделить то, что работает, от того, что не работает.
Отдадим должное генеративному искусственному интеллекту. За два года он коренным образом изменил индустрию аналитики к лучшему. Он ускорил анализ, автоматизировал отчетность, открыл новые способы обработки неструктурированных данных и сделал сложные инструменты обработки естественного языка доступными для каждого исследователя с браузером. Это реальные, долгосрочные достижения. Ни один серьезный человек не станет их оспаривать.
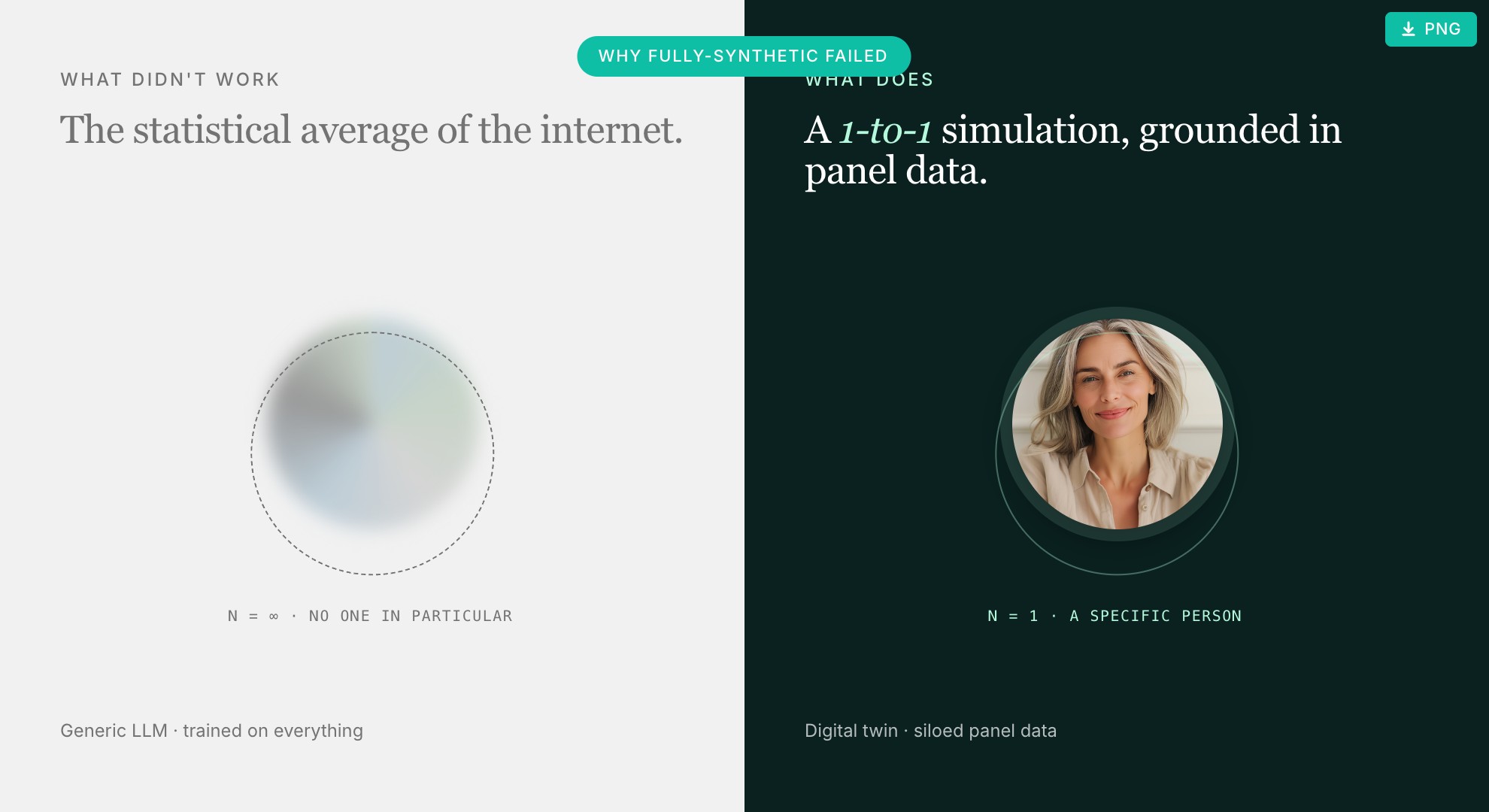
Однако есть одно конкретное применение, где эта технология не оправдала ожиданий: полностью синтетические аудитории. Идея о том, что универсальная большая языковая модель, обученная в открытом интернете, может надежно заменить реальных респондентов, была проверена — и оказалась несостоятельной. Когда исследователи сравнивали эти результаты с реальными панельными данными, результаты слишком часто не улавливали нюансы и вариативность, которые определяют подлинное понимание потребителей.
Это различие имеет значение. Полностью отвергать генеративный ИИ только потому, что одно приложение показало неудовлетворительные результаты, было бы так же глупо, как и первоначальные преувеличения. Более продуктивный вопрос: почему полностью синтетические аудитории потерпели неудачу, и как выглядит более эффективный подход?
Ответ кроется в данных, а не в алгоритме.
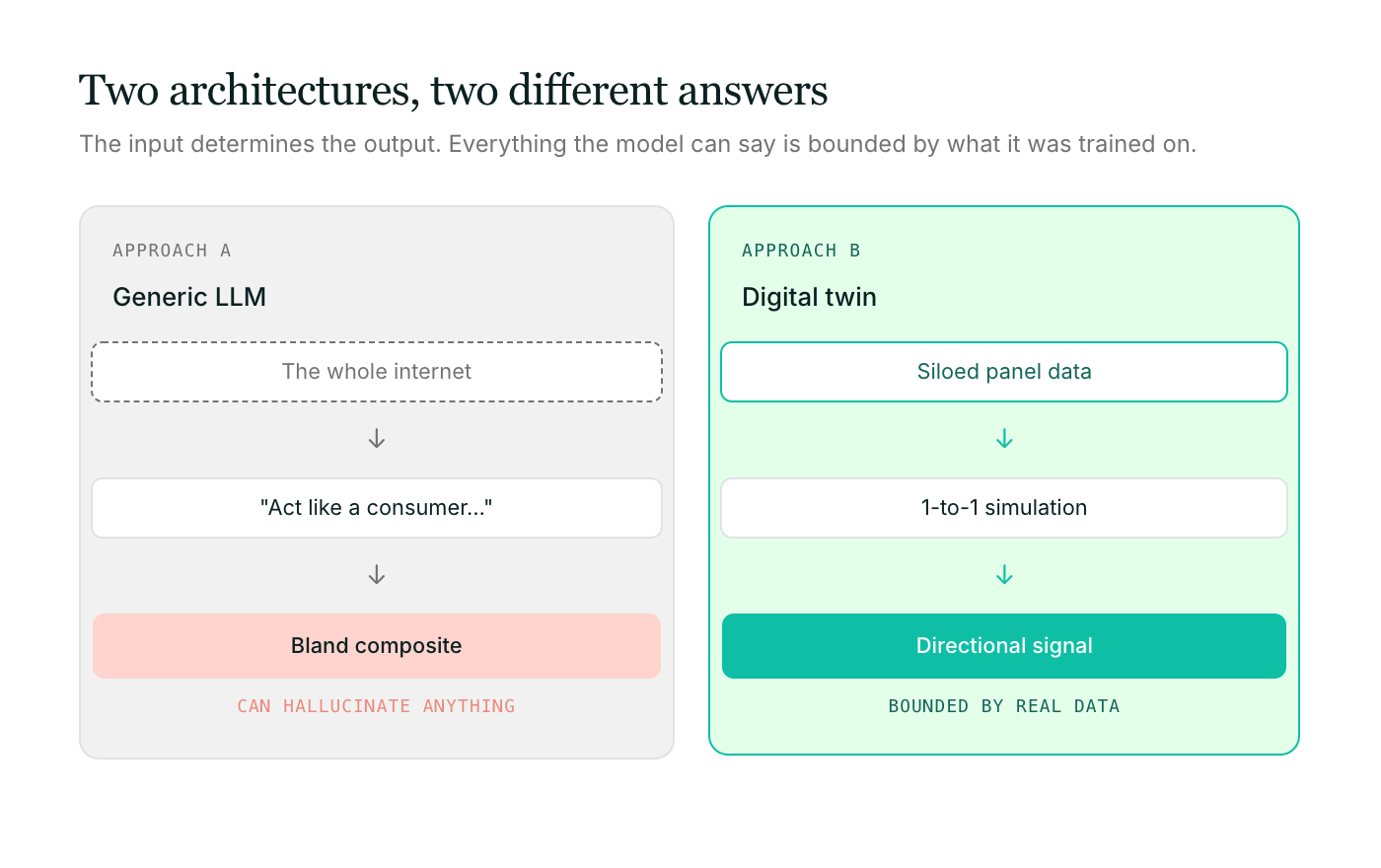
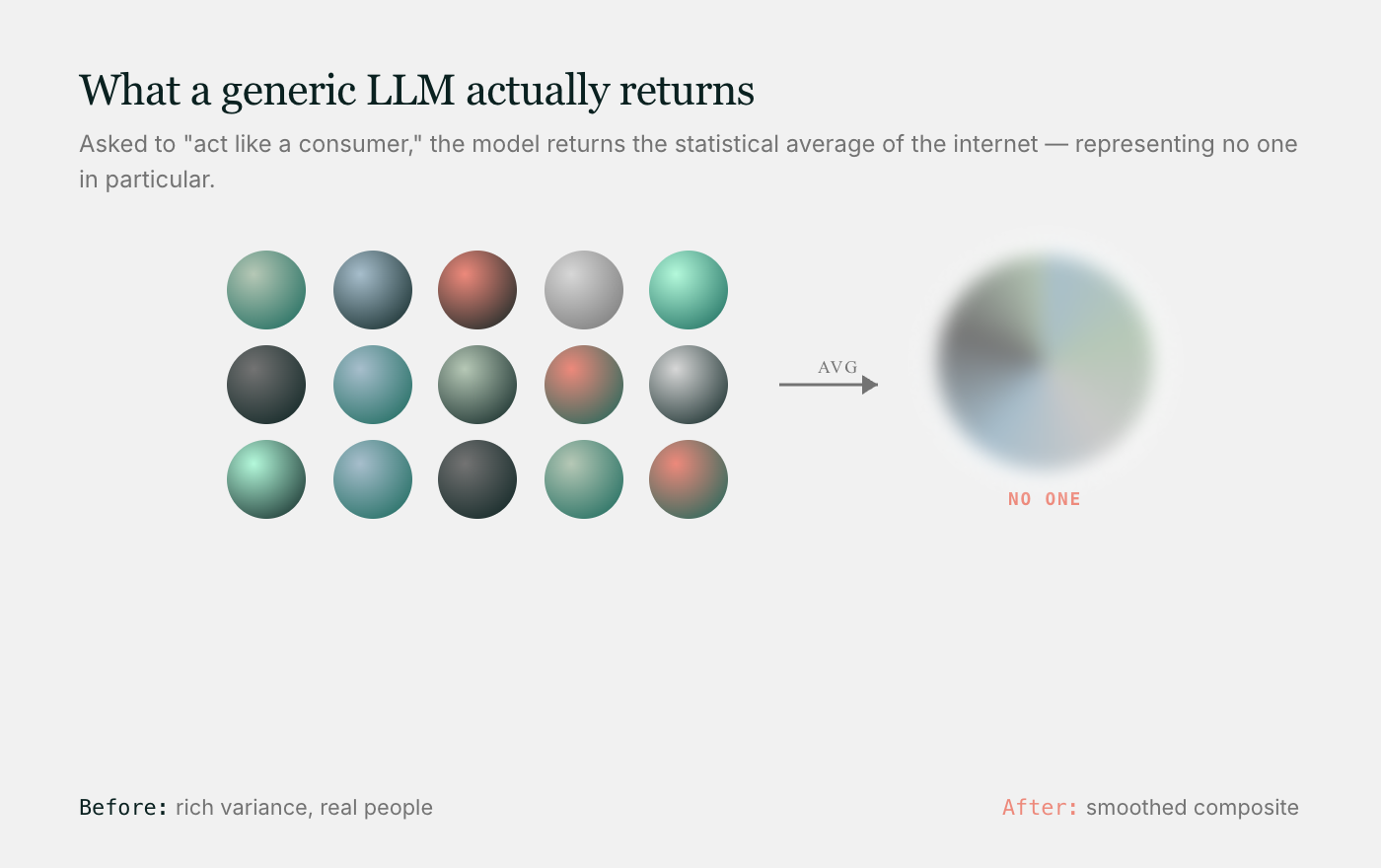
Когда вы просите стандартную модель LLM «вести себя как потребитель», она возвращает статистическое среднее значение по интернету. Это сглаживает те самые различия, которые исследователи должны выявлять. Профили 65-летнего пенсионера могут сильно различаться практически по любому отношению или поведению, однако стандартная задача сводит все это богатство в один сплошной, безликий образ. Сигнал слаб, потому что модель опирается на все факторы, а это значит, что она не представляет никого конкретного.
Концепция цифрового двойника предполагает принципиально иной подход. Вместо того чтобы создавать вымышленных респондентов из открытого интернета, цифровой двойник представляет собой точную симуляцию, построенную на основе самых подробных и специфических доступных данных, базирующихся на многомерных панельных данных, охватывающих демографические характеристики, модели поведения, историю транзакций и отношение к проблеме.
Крайне важно, чтобы эти цифровые двойники были строго изолированы. В отличие от открытых моделей LLM, специально созданные цифровые двойники ограничены конкретными, проверенными панельными данными, на которых они обучаются. Когда двойник отвечает на концептуальный тест, его реакция формируется исключительно на основе реального профиля респондента, на котором он был смоделирован, а не на основе статистического среднего значения в интернете. Если данные отсутствуют в базовой панели, двойник не может сформировать на их основе мнение.
Эта архитектура позволяет исследователям либо использовать готовые целевые аудитории от ведущих поставщиков данных, либо создавать собственные, запатентованные аудитории, загружая данные прошлых количественных и качественных исследований для обучения моделей, специфичных для каждой компании. В результате получается обоснованный, направленный сигнал, основанный на реальных данных, а не на общих предположениях.
Но даже при такой архитектуре, ориентированной на данные, отрасль должна придерживаться более высоких стандартов честности, чем те, которые требовала первая волна искусственного ажиотажа.
Цифровые двойники не заменяют реальные полевые исследования. Решения, имеющие большое значение – например, сегментация рынка, отслеживание бренда на нескольких рынках – всегда будут требовать значительных инвестиций, необходимых для проведения традиционных полевых исследований. Это не изменится, да и не должно измениться.
Цифровые двойники особенно эффективны в «промежуточном сегменте»: в сотнях важных решений, которые ежегодно принимают маркетинговые и продуктовые команды без предварительной проверки со стороны клиентов, просто потому что традиционные исследования слишком медленны или слишком дороги для каждого вопроса. Оптимизация рекламных сообщений во вторник днем. Тестирование ценового сценария перед заседанием совета директоров в пятницу. Проверка концепции продукта перед выделением ресурсов на разработку.
В таких сценариях цифровые двойники представляют собой мощное дополнение к традиционным методам. Они дают лишь общие представления, а не окончательные выводы. Это вариант «второй лучший после полевых исследований» — быстрее, доступнее и прозрачнее в отношении существующих пробелов.
Генеративный ИИ открыл перед индустрией аналитики необычайные новые возможности. Ошибка заключалась в предположении, что эти возможности распространяются на замену реальных респондентов средними показателями из интернета. Это не так. Но когда та же технология основана на высококачественных, изолированных панельных данных, она становится действительно полезной: способом держать клиента в центре повседневных решений, оставляя при этом тщательные полевые исследования для тех вопросов, которые этого больше всего требуют.
Урок заключается не в том, что ИИ потерпел неудачу. Урок в том, что данные, лежащие в его основе, важнее, чем модель, на которой он построен.
Самуэль Коэн — генеральный директор и основатель компании Fairgen, занимающейся разработкой инфраструктуры для имитационного исследования аудитории с использованием искусственного интеллекта.
Источник:
https://www.research-live.com/article/opinion/generative-ai-changed-everything-fully-synthetic-audiences-didnt/id/5148703







