
Встраивания являются краеугольным камнем современного генеративного ИИ, молча управляя функциональностью многих систем, с которыми мы взаимодействуем ежедневно. В простейшем случае встраивания представляют собой числовые представления текста — эффективно преобразуя слова, предложения или даже целые документы в числа. Эти числа далеки от случайности; они тщательно разработаны для фиксации смысла и отношений в тексте.
Например, встраивания для «собаки» и «щенка» будут ближе друг к другу в числовом пространстве, чем встраивание для «автомобиля», что отражает их семантическое сходство . Эта способность кодировать смысл в измеримую форму делает встраивания незаменимыми для таких задач, как поиск, рекомендательные системы и продвинутые приложения ИИ, такие как Retrieval-Augmented Generation (RAG).
Это преобразование в числа позволяет ИИ сравнивать и понимать текст осмысленным образом. При работе с большими объемами данных, как это часто бывает в системах RAG, встраивание становится необходимым. Эти системы объединяют мощь встраивания со специализированными решениями для хранения, называемыми векторными базами данных . В отличие от традиционных баз данных, которые ищут точные совпадения, векторные базы данных оптимизированы для поиска наиболее близких совпадений на основе смысла. Эта возможность позволяет системам RAG извлекать наиболее релевантную информацию из обширных баз знаний и использовать ее для генерации точных, контекстно-обоснованных ответов. Объединяя необработанные данные и интеллектуальный поиск, встраивание и векторные базы данных вместе составляют основу успеха систем RAG.
- Проблема многоязычных систем
- Почему английские вставки более точны?
- Влияние на системы RAG
- Сравнение моделей встраивания для голландской системы RAG
- Создание вложений
- Как работает этот код
- Оценка моделей внедрения
- Результаты внедрения моделей
- Cohere Embed English v3
- Cohere Embed Multilingual v3
- Ключевые выводы
- Заключение
Проблема многоязычных систем
Создание систем RAG, которые хорошо работают на английском языке, само по себе является сложной задачей, но их распространение на другие языки представляет собой целый ряд новых проблем. Английские вложения часто высоко оптимизированы из-за обилия обучающих данных и простоты структуры языка. Однако использование этих обученных на английском языке вложений для других языков может привести к значительным неточностям. Разные языки имеют свои собственные нюансы, грамматику и культурные контексты, которые стандартные модели встраивания, обученные преимущественно на английском тексте, часто не могут уловить. Хотя существуют некоторые многоязычные модели встраивания для преодоления этого разрыва, не все они одинаково эффективны для разных языков, особенно для тех, у кого ограниченные обучающие данные или уникальные лингвистические особенности. Это затрудняет создание систем RAG, которые были бы столь же точными и надежными для неанглийских языков, как и для английского.
Почему английские вставки более точны?
- Обилие высококачественных обучающих данных
Английский язык доминирует в цифровом ландшафте, с непревзойденным объемом высококачественного контента, доступного для обучения. Такие наборы данных, как Wikipedia, книги, исследовательские работы и социальные сети, гораздо богаче на английском языке, чем на других языках. Напротив, многие языки, особенно малоресурсные, не имеют разнообразных и стандартизированных наборов данных, что ограничивает качество обученных на них встраиваний. - Модели оптимизации модели Смещение
NLP-моделей, такие как BERT и GPT, изначально разрабатывались и оптимизировались для английского языка, часто отдавая ему приоритет даже в многоязычных версиях. Многоязычные модели балансируют обучение на многих языках в одном и том же пространстве параметров, что может ослабить производительность для менее представленных языков в пользу доминирующих, таких как английский. - Лингвистическая сложность и разнообразие
Английский язык имеет относительно простую морфологию по сравнению со многими другими языками. Например, формы слов в английском языке, как правило, остаются неизменными (например, «run» и «running»), в то время как такие языки, как турецкий или финский, имеют сильно флективные формы, где однокоренное слово может иметь десятки вариаций. Кроме того, языки с другим синтаксисом или порядком слов, такие как японский (подлежащее-объект-глагол) или арабский (гибкий порядок слов), создают дополнительные проблемы для моделей, оптимизированных для структур, подобных англоязычным. - Семантическое и культурное соответствие.
Захват семантического значения в разных языках — задача не из простых. Слова и фразы часто несут в себе нюансированные значения, которые не переводятся напрямую. Например, английское слово «love» имеет несколько культурно различных эквивалентов в других языках (например, «amor» в испанском, «eros» или «agape» в греческом). Встраивания, которые не учитывают эти различия, затрудняют многоязыковое соответствие. - Смещение бенчмаркинга и оценки
Многие наборы данных бенчмаркинга и методы оценки разработаны с учетом английского языка. Этот англо-центричный фокус может искусственно завышать воспринимаемую производительность моделей на английском языке, маскируя их ограничения на других языках.
Влияние на системы RAG
Когда встраивания не справляются со сложностью других языков, последствия для систем RAG могут быть значительными. Результаты поиска часто становятся менее релевантными или даже совершенно неверными, поскольку встраивания могут испытывать трудности с уловкой тонкого смысла неанглоязычных запросов. Это не только влияет на точность — это также подрывает доверие пользователей и общую полезность системы. Важные фрагменты текста могут быть пропущены во время поиска, что не позволяет системе получить доступ к информации, необходимой для генерации точных и контекстно релевантных ответов.
Для эффективной работы многоязычной системы RAG требуются вложения, которые могут семантически согласовываться между языками, принимая во внимание их уникальные структурные и культурные тонкости. Инвестирование в высококачественные многоязычные вложения и их тонкая настройка для конкретных языков или задач имеет важное значение. Это гарантирует, что системы RAG смогут удовлетворить потребности пользователей на любом языке — не только на английском.
Но насколько хорошо различные встраивания работают в неанглоязычном контексте? Чтобы изучить это, мы сравним английскую модель встраивания с многоязычной моделью встраивания, используя голландский набор данных. Этот тест покажет, как различные подходы к встраиваниям влияют на точность поиска и качество сгенерированных ответов в многоязычной системе RAG.
Сравнение моделей встраивания для голландской системы RAG
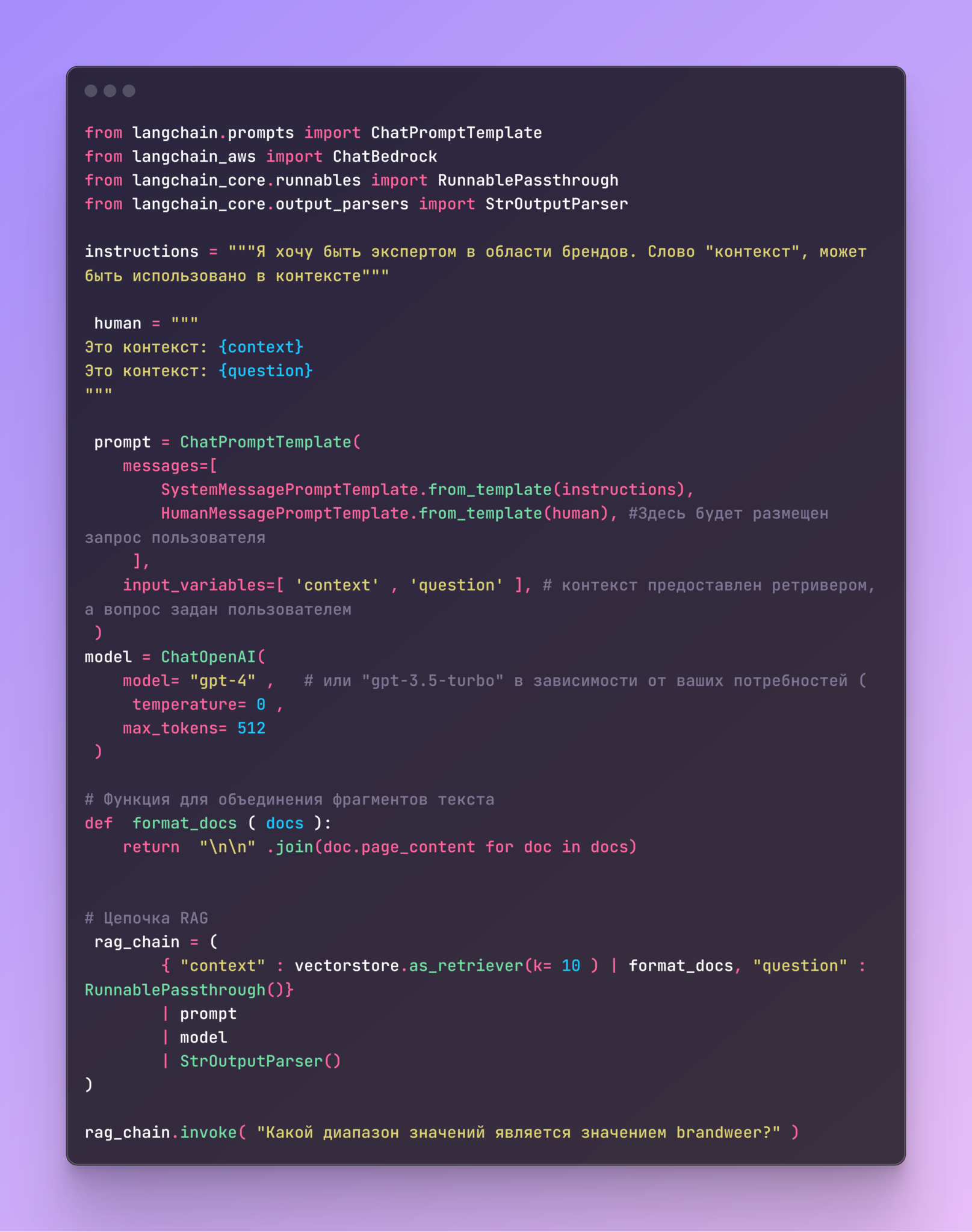
Чтобы понять, как разные модели встраивания обрабатывают неанглийский язык, например голландский, мы сравним две модели, доступные на Amazon Bedrock: Cohere Embed English v3 и Cohere Embed Multilingual v3 . Эти модели представляют разные подходы к встраиванию — одна оптимизирована исключительно для английского языка, а другая разработана для многоязычных задач. В таблице ниже приведены их основные атрибуты:

Создание вложений
Чтобы оценить производительность моделей встраивания, мы построим локальное векторное хранилище с использованием фреймворка LangChain. Для этой оценки мы будем использовать руководство для пожарных, написанное на голландском языке, в качестве нашего набора данных. Этот документ содержит техническую и процедурную информацию, что делает его реалистичным и сложным вариантом использования для семантического поиска на языке, отличном от английского. Ниже приведен очищенный и оптимизированный код для создания локального векторного хранилища и индексации фрагментов документа. Мы будем использовать эту настройку для тестирования двух моделей встраивания: Cohere Embed English v3 и Cohere Embed Multilingual v3 .

Как работает этот код
- Загрузка документа :
Код загружает все файлы PDF изdataкаталога. Вы можете настроить путь к файлу и формат в соответствии с вашим набором данных. - Разделение текста :
Документы разбиваются на более мелкие фрагменты по 400 символов с перекрытием в 50 символов для повышения точности поиска. Это гарантирует, что каждый фрагмент остается контекстно значимым. - Модели встраивания :
классBedrockEmbeddingsинициализирует модель встраивания. Вы можете заменить ,model_idчтобы протестировать Cohere Embed English v3 или Cohere Embed Multilingual v3 . - Local Vectorstore :
Библиотека FAISS используется для создания in-memory vectorstore из фрагментов документа. Это позволяет выполнять быстрый поиск по сходству и может быть сохранено локально для повторного использования.
Чтобы протестировать все модели, замените model_idв BedrockEmbeddingsинициализации соответствующую модель:
"cohere.embed-english-v3"для Cohere English."cohere.embed-multilingual-v3"для Cohere Multilingual.
Оценка моделей внедрения
Чтобы оценить эффективность моделей встраивания, мы зададим вопрос: «Welke rangen zijn er bij de brandweer?» , что переводится как «Какие звания существуют в пожарной части?» . Этот вопрос был выбран, потому что в нашем документе используется только термин «hiërarchie» , который в голландском языке имеет схожее семантическое значение с «rangen» . Однако в английском языке «hierarchy» и «ranks» не имеют семантического сходства.

Это различие имеет решающее значение для нашего теста. Мы ожидаем, что модель Cohere Embed English v3 столкнется с трудностями при выполнении этого запроса, поскольку она опирается на английскую семантику, где термины не связаны между собой. С другой стороны, модель Cohere Embed Multilingual v3 , обученная понимать голландскую семантику, должна извлекать правильную информацию из документа, демонстрируя свою способность обрабатывать семантические нюансы в языках, отличных от английского.
Задавая этот вопрос, мы стремимся подчеркнуть, как семантическое выравнивание влияет на производительность поиска в голландской системе RAG. Этот тест предоставит наглядное сравнение способности моделей обрабатывать неанглийские запросы и извлекать релевантную информацию. Результаты продемонстрируют важность многоязычных вложений для достижения точного поиска в неанглоязычных контекстах.
Чтобы реализовать и протестировать эту настройку, мы можем использовать следующий код. Этот скрипт демонстрирует, как запросить vectorstore и использовать цепочку RAG для объединения вложений с языковой моделью для ответа на вопросы. Обратите внимание, что при тестировании различных вложений (например, Cohere Embed English v3 против Cohere Embed Multilingual v3 ) вам необходимо убедиться, что vectorstore создан с использованием соответствующей модели вложения. Замените vectorstore на тот, который индексирован с использованием модели вложения, которую вы хотите протестировать для получения точных результатов.
Результаты внедрения моделей
Чтобы оценить эффективность двух моделей внедрения, мы задали вопрос: «Welke rangen zijn er bij de brandweer?» (перевод: «Какие звания существуют в пожарной части?»). Ниже приведены ответы, полученные с помощью каждой модели:
Cohere Embed English v3
Ответ :
«Текст содержит конкретную информацию о широком диапазоне брендов. Кроме того, в каждой фирменной организации есть широкий диапазон должностей: брендверман, лейтенант, капитан, батальонный шеф-повар, помощник шеф-повара и брэндвершеф. Определенный диапазон может варьироваться в зависимости от страны и конкретной организации».
Анализ :
Ответ является общим и не полагается на предоставленный контекст из голландского документа. Это ожидаемо, так как английская модель встраивания испытывает трудности с установлением семантического сходства между «hiërarchie» (используется в документе) и «rangen» (используется в запросе). Следовательно, по умолчанию она использует общие знания о званиях пожарных.
Cohere Embed Multilingual v3
Ответ :
«Binnen de Brandweer Zijn er Verschillende Rangen. Здесь вы найдете базовый курс и средний курс. В базовом наборе мы являемся бренд-менеджером B01 и корпорацией B02. В мидденкадере, который лучше всего работает офицером-офицером, мы были сержантом M01 и адъютантом M02. Deze rangen worden aangeduid op het diensttenue, het uitgaanstenue en op de interventiekledij».
Анализ :
этот ответ очень релевантен и точно извлекает информацию из документа. Многоязычная модель встраивания успешно определяет семантическую связь между «hiërarchie» (контекст) и «rangen» (запрос). Она предоставляет подробный ответ, основанный непосредственно на содержании документа, демонстрируя свою способность эффективно обрабатывать голландскую семантику.
Ключевые выводы
- Cohere Embed English v3 : Английская модель не смогла извлечь соответствующий контекст из голландского документа из-за отсутствия семантического соответствия между запросом и терминологией документа. Это подчеркивает ограничения использования англоязычных вложений для неанглоязычных задач.
- Cohere Embed Multilingual v3 : Многоязычная модель преуспела в этом тесте, извлекая и используя контекстно-релевантную информацию из голландского документа. Это демонстрирует важность многоязычных вложений для достижения точного извлечения и эффективного ответа на неанглийские запросы.
Заключение
Эта оценка подчеркивает критически важную идею для любого, кто создает системы Retrieval-Augmented Generation (RAG) для языков, отличных от английского: встраивания имеют значение , особенно когда задача требует тонкого понимания между языками. Резкий контраст в производительности между моделями Cohere Embed English v3 и Cohere Embed Multilingual v3 иллюстрирует ограничения встраиваний, специфичных для английского языка, в неанглийских контекстах и огромную ценность многоязычных моделей.
При ответе на запрос на голландском языке многоязычная модель преуспела, извлекая точную и контекстно-богатую информацию непосредственно из документа. Между тем, английская модель встраивания по умолчанию использовала общие, несвязанные знания, демонстрируя свою неспособность преодолеть семантический разрыв между запросом и содержимым документа.
Для организаций, разрабатывающих системы ИИ в глобальном многоязычном ландшафте, этот тест подтверждает важность выбора правильных моделей встраивания для поставленной задачи. Многоязычные встраивания — это не просто «приятная» функция; они необходимы для обеспечения точности, релевантности и доверия пользователей к неанглоязычным приложениям.
Поскольку генеративный ИИ продолжает расширять свое влияние, принятие языкового разнообразия посредством лучшего внедрения станет ключом к предоставлению значимых и эффективных решений по всему миру. Отдавая приоритет многоязычным возможностям, компании могут создавать системы, которые не только более умны, но и более инклюзивны, предоставляя пользователям возможности на разных языках и в разных культурах.







