Богатство данных социальных сетей открыло новые возможности для исследований в области социальных наук, чтобы получить представление о поведении и опыте человека. В частности, новые подходы, основанные на данных, основанные на тематических моделях, открывают совершенно новые перспективы для интерпретации социальных явлений. Однако краткий, насыщенный текстом и неструктурированный характер контента социальных сетей часто приводит к методологическим проблемам как при сборе, так и при анализе данных.
Чтобы объединить развивающуюся область вычислительной науки и эмпирических социальных исследований, это исследование направлено на оценку эффективности четырех методов тематического моделирования, а именно: латентного распределения Дирихле (LDA), неотрицательной матричной факторизации (NMF), Top2Vec и BERTopic. Ввиду взаимодействия между человеческими отношениями и цифровыми медиа это исследование берет сообщения в Twitter в качестве точки отсчета и оценивает производительность различных алгоритмов с точки зрения их сильных и слабых сторон в контексте социальных наук. Основываясь на определенных деталях во время аналитических процедур и на вопросах качества, это исследование проливает свет на эффективность использования BERTopic и NMF для анализа данных Twitter.
Чтобы раскрыть сложную природу социальных явлений, тематические модели выступают в качестве моста между социальной наукой и (не)структурированным анализом, различными методами рассуждения и аналитикой больших данных (Hannigan et al., 2019 ) из-за их исследовательского характера (Albalawi et al., 2020 ). В социальных науках последствия больших данных могут варьироваться от макроуровневого анализа (например, социальная структура и поведение человека) до микроуровневого анализа (например, индивидуальные отношения и аспекты повседневной деятельности). Основываясь на наблюдаемых явлениях и опыте, можно отметить примеры из растущего количества литературы, анализирующей новости (Chen et al., 2019 ), онлайн-обзоры (Bi et al., 2019 ) и контент социальных сетей (Yu and Egger, 2021 ) и т. д. Тем не менее, в то время как обсуждение больших данных в социальных науках в основном вращается вокруг критической точки зрения предмета, само применение почти никогда не обсуждается. Хотя большие данные кажутся исключительно многообещающими, данные всегда предварительно сконфигурированы посредством убеждений и ценностей, и необходимо признать многочисленные проблемы, поскольку каждый шаг в анализе больших данных зависит от различных решающих критериев, таких как выбор параметров, оценка частичных результатов и их фактическая интерпретация (Lupton, 2015 ). С недавним прогрессом в области обработки естественного языка новые методы моделирования, такие как BERTopic (Grootendorst, 2022 ) и Top2Vec (Angelov, 2020 ), еще больше усложняют процесс аналитики больших данных, настойчиво требуя оценки производительности различных алгоритмов. Кроме того, в то время как социальные ученые интересуются теоретически обоснованными предположениями и их последствиями, ученые, работающие с данными, сосредоточены на обнаружении новых закономерностей (Cai and Zhou, 2016 ), которые кажутся иррациональными из-за их ограниченной объяснительной силы для социальных явлений (McFarland et al., 2016 ).
Социальные медиа открыли совершенно новый путь для исследований в области социальных наук, особенно когда речь идет о взаимосвязи человеческих отношений и технологий. В этом отношении ценность пользовательского контента на платформах социальных медиа была общепризнанной и общепризнанной, поскольку их богатая и субъективная информация позволяет проводить благоприятный вычислительный анализ (Hu, 2012 ). Например, недавнее исследование изучало социальную динамику спортивных мероприятий на основе комментариев в Facebook (Moreau et al., 2021 ), в то время как другое исследование раскрыло социальную семиотику различных достопримечательностей с использованием контента в Instagram (Arefieva et al., 2021 ). Ученые также использовали сообщения в Twitter, связанные с пандемией COVID-19, для построения реакций человека (Boccia Artieri et al., 2021 ). С эпистемологической точки зрения, общим для этих подходов, основанных на данных, является то, что они предлагают совершенно новые перспективы интерпретации явления и имеют возможность обновить самые современные знания (Simsek et al., 2019 ). В конце концов, многие аспекты социальных наук и социальных сетей так или иначе переплетаются; в то время как первое касается человеческого взаимодействия, второе расширяет его сущность до гораздо более широкого и глобального масштаба.
Тем не менее, несмотря на значимость социальных сетей в современном обществе, сообщения часто перегружены текстом и неструктурированы, что усложняет процесс анализа данных (Egger and Yu, 2021 ). Такие методологические проблемы особенно заметны для тех, у кого нет знаний и навыков программирования (Kraska et al., 2013 ). Конечно, недавние достижения в области визуального программирования позволили исследователям анализировать данные социальных сетей без кодирования с использованием тематического моделирования (Yu and Egger, 2021 ), однако обоснованность и качество результатов, основанных на такой интуиции, остаются под вопросом. Одним из распространенных заблуждений, которое может исказить результаты, является использование настроек гиперпараметров по умолчанию. Хотя важность настройки модели часто признается (Zhou et al., 2017 ), при анализе данных социальных сетей в социальных науках можно найти мало рекомендаций. Кроме того, еще одним барьером, который препятствует генерации знаний в контексте социальных наук, является применение более традиционных и общепринятых алгоритмов (Blair et al., 2020 ). Например, несмотря на популярность LDA, надежность и обоснованность результатов подвергаются критике, поскольку оценка модели остается позади (Egger and Yu, 2021 ).
Следовательно, некоторые социологи инициировали призыв к проведению большего количества междисциплинарных исследований и оценке эффективности моделей на основе других новых и развивающихся методов (Reisenbichler and Reutterer, 2019 ; Albalawi et al., 2020 ; Egger and Yu, 2021 ). Учитывая недостаточное знание недавно разработанных алгоритмов, которые могли бы лучше обрабатывать природу данных социальных сетей в социальных науках, это исследование направлено на оценку и сравнение эффективности четырех методов моделирования тем, а именно LDA, NMF, Top2Vec и BERTopic. В частности, LDA является генеративной статистической моделью, NMF использует подход линейной алгебры для извлечения тем, а BERTopic и Top2Vec используют подход встраивания. Объединяя дисциплину науки о данных с социальной наукой, обзоры сильных и слабых сторон различных инструментов представляют ценность для поддержки прикладных социологов в выборе подходящих методов. Это исследование проливает свет на возможности альтернативных решений, которые могут помочь ученым-социологам справиться с методологическими проблемами при работе с большими данными.
- Литературный обзор
- Изучение социальных сетей с использованием моделей машинного обучения
- Тематическое моделирование как решение для работы с неструктурированными текстовыми данными
- Материалы и методы
- Сбор данных и предварительная обработка
- Реализация тематических моделей
- Модель 1: Скрытое распределение Дирихле
- Модель 2: Неотрицательная матричная факторизация
- Модель 3: Top2Vec
- Модель 4: BERТема
- Результаты
- Сравнение LDA и NMF
- Таблица 1.
- Сравнение BERTopic и Top2Vec
- Рисунок 4.
- Таблица 2.
- Таблица 3.
- Иерархическое сокращение тем Top2Vec и BERTopic
- Таблица 4.
- Рисунок 5.
- Обсуждение и заключение
- Таблица 5.
- Теоретические и практические вклады
- Ограничения и рекомендации для будущих исследований
- Заявление о доступности данных
- Вклады авторов
- Конфликт интересов
- Примечание издателя
- Ссылки
Литературный обзор
Изучение социальных сетей с использованием моделей машинного обучения
Благодаря повсеместному использованию технологий человеческое общение вышло за рамки времени и пространства, как локально, так и глобально (Joubert and Costas, 2019 ). Среди различных типов инструментов коммуникации социальные сети выделяются как жизненно важный посредник и средство содействия взаимодействию между социальными субъектами (Murthy, 2012 ). Поскольку социальные сети отображают человеческое поведение и взаимодействия, социологи приступили к интеллектуальному анализу данных (Boccia Artieri et al., 2021 ) и использованию подходов NLP и машинного обучения. Чтобы понять огромное количество сообщений, публикуемых в социальных сетях, NLP может понимать человеческие языки, как запрограммировано для машин, чтобы делать прогнозы на основе наблюдаемых социальных явлений (Hannigan et al., 2019 ). С другой стороны, машинное обучение, как часть искусственного интеллекта, относится к вычислительным методам, использующим существующие базы данных (т. е. данные обучения) для построения и обучения модели для прогнозирования и лучшего принятия решений (Zhou et al., 2017 ). Преимущества открытия новых горизонтов для социологического рассмотрения посредством передовой аналитики данных можно наблюдать в различных контекстах, включая бизнес, здравоохранение, образование и, в более общем плане, роль социальной деятельности в развитии научных знаний (Yang et al., 2020 ).
Предыдущие исследования подчеркивали, что цифровая революция представляет собой динамику в сетях обмена (Joubert and Costas, 2019 ) и подразумевает самовосприятие человека (Murthy, 2012 ). Примеры можно увидеть на сайтах микроблогов, таких как Twitter, которые ежедневно собирают более 200 миллионов активных пользователей. Поскольку социальные сети трансформируют взаимодействия в отношения, а эти взаимодействия превращаются в опыт (Witkemper et al., 2012 ), постоянные обновления статуса рассматриваются и оцениваются как самопроизводство (Murthy, 2012 ) и, таким образом, позволяют ученым оценивать перспективы с точки зрения общественности (Joubert and Costas, 2019 ). Например, в инфодемиологии Сюэ и др. ( 2020 ) применили модели машинного обучения для мониторинга общественных реакций в отношении обсуждения и проблем COVID-19 в Twitter. Аналогичным образом, в высокодинамичной индустрии туризма Лу и Чжэн ( 2021 ) смогли отследить общественное мнение о круизных судах во время пандемии COVID-19 на основе собранных твитов. Более того, в отличие от большинства сетевых платформ, построенных на существующих дружеских связях, функция ретвитов может распространять информацию гораздо быстрее (Park et al., 2016 ), тем самым делая Twitter идеальной средой для исследований в области социальных наук.
Тем не менее, независимо от платформы социальных сетей, теоретизирование остается неотъемлемой частью (Müller et al., 2016 ) формирующегося предмета больших данных в социальных науках. Хотя некоторые ученые считают, что большие данные могут и должны быть полностью свободны от теории (Anderson, 2008 ; Kitchin, 2014 ), кажется маловероятным интерпретировать результаты без достаточного понимания социальных наук (Mazanec, 2020 ). Тем не менее, методологические проблемы часто возникают параллельно с эпистемологическими разработками. Например, поскольку алгоритмы не способны структурировать свободный текст, этапы предварительной обработки данных, требующие сложных навыков принятия решений, такие как очистка, преобразование, извлечение признаков и векторизация, закладывают основу для дальнейшего анализа (Albalawi et al., 2020 ). Хотя у социальных ученых есть возможность предварительной обработки наборов данных, проблемы могут возникнуть на следующих этапах, включая оценку модели и настройку гиперпараметров (Blair et al., 2020 ). По большей части эти проблемы можно отнести к самой природе контента социальных сетей, который в основном состоит из коротких, лаконичных, текстово-нагруженных и неструктурированных форматов (Албалави и др., 2020 ).
Тематическое моделирование как решение для работы с неструктурированными текстовыми данными
Поскольку человеческий язык является адаптивной многоуровневой системой, длина текста, синтаксическая сложность и семантическая правдоподобность долгое время считались центральными моментами как в психологии, так и в лингвистике (Брэдли и Мидс, 2002 ). Вместе с взаимодействием между технологиями и модернизацией их влияние распространилось и на социальные сети. Например, ученые отметили, что более короткие посты, как правило, приводят к более высокому уровню вовлеченности в Facebook (Сабат и др., 2014 ), возможно, потому, что краткие сообщения сокращают объем когнитивных усилий, необходимых для обработки информации (Ши и др., 2022 ). Среди различных доступных типов платформ, в частности, Twitter ограничивает каждую публикацию максимум 280 символами (Кейрос, 2018 ), и хотя эти короткие и неструктурированные посты соответствуют практике социальных сетей, они увеличивают сложность алгоритмов для понимания цифрового взаимодействия. Распространенные проблемы возникают при использовании сложных слов, аббревиатур и неграмматических предложений (Ariffin and Tiun, 2020 ). Несмотря на продуктивную и невыраженную природу сложных слов, они часто усложняют вычислительный анализ (Krishna et al., 2016 ). Другие трудности возникают, когда данные бессмысленны (т. е. зашумленные данные) или когда в данных присутствует много пробелов (т. е. разреженные данные; Kasperiuniene et al., 2020 ).
Для эффективного извлечения признаков из большого корпуса текстовых данных были введены многочисленные подходы к интеллектуальному анализу текста (Li et al., 2019 ), среди которых тематическое моделирование является наиболее часто применяемым методом (Hong and Davison, 2010 ). В двух словах, тематическая модель — это форма статистического моделирования, используемая в машинном обучении и обработке естественного языка, как обсуждалось ранее, которая выявляет скрытые тематические закономерности в коллекции текстов (Guo et al., 2017 ). Наиболее устоявшимися и популярными методами считаются LDA, латентный семантический анализ (LSA) и вероятностный LSA (Albalawi et al., 2020 ). Однако совсем недавно новые разработанные алгоритмы, такие как NMF, Corex, Top2Vec и BERTopic, также получили и продолжают привлекать все большее внимание исследователей (Obadimu et al., 2019 ; Sánchez-Franco и Rey-Moreno, 2022 ). В социальных науках тематические модели ранее применялись, например, для обнаружения неявных предпочтений потребителей (Vu et al., 2019 ; Egger et al., 2022 ), определения семантических структур в Instagram (Egger и Yu, 2021 ) и улучшения систем рекомендаций (Shafqat и Byun, 2020 ). Несмотря на надежность алгоритмов тематического моделирования, существующая литература в основном опирается на одну-единственную модель, причем доминирующим методом является LDA (Gallagher et al., 2017 ) и обычно рассматривается как стандартный подход.
Независимо от популярности LDA в отрасли социальных наук, его эффективность в анализе данных социальных сетей подвергалась резкой критике (Egger и Yu, 2021 ; Sánchez-Franco и Rey-Moreno, 2022 ). В случае данных Twitter Джарадат и Мацкин ( 2019 ) утверждают, что, хотя в документе могут сосуществовать несколько тем, LDA имеет тенденцию игнорировать отношения совместного появления. Аналогичным образом, другие исследователи подчеркивают, что шумные и разреженные наборы данных не подходят для LDA (Chen et al., 2019 ) из-за отсутствия признаков для статистического обучения (Cai et al., 2018 ). Следовательно, исследователи усилили ценность недавно разработанных алгоритмов в качестве альтернатив, поскольку они часто превосходят LDA, особенно при анализе коротких текстовых данных в социальных сетях (Egger, 2022b ). Хотя появились и были приняты новые подходы для выявления новых идей, их инновационные преимущества (непреднамеренно) снижают значимость оценки модели. Доказательства можно взять из исследований социальных сетей, в которых применение методов оценки еще не стало мейнстримом (Reisenbichler and Reutterer, 2019 ). Кроме того, поскольку модели будут оптимизированы для извлечения любого незначительного варианта темы, в зависимости от цели алгоритма, результаты могут быть искажены в определенном направлении. Эти проблемы еще больше подчеркивают ненадежность концентрации исключительно на одной единственной тематической модели и, тем самым, также усиливают ценность и необходимость сравнения различных алгоритмов (Reisenbichler and Reutterer, 2019 ; Albalawi et al., 2020 ; Egger and Yu, 2021 ).
Материалы и методы
Заинтригованное сложностью коротких текстовых данных социальных сетей, целью данного исследования является сравнение различных типов алгоритмов моделирования тем, чтобы предложить новые идеи и решения социальным ученым, заинтересованным в изучении человеческих взаимодействий. По сравнению с другими платформами, Twitter предлагает краткие посты, максимум 280 символов на твит, которые можно идентифицировать с помощью определенных хэштегов (Queiroz, 2018 ). Таким образом, использование хэштегов оптимизирует процесс поиска информации на основе интересов пользователей. Рассматривая потенциал социальных сетей в улучшении кризисной коммуникации (Femenia-Serra et al., 2022 ), данное исследование использует посты Twitter, связанные с путешествиями и пандемией COVID-19, в качестве точек отсчета для оценки четырех вышеупомянутых тематических моделей (т. е. LDA, NMF, Top2Vec и BERTopic). Подробный процесс реализации данного исследования был следующим.
Сбор данных и предварительная обработка
Сбор данных проводился в ноябре 2021 года с использованием программного инструмента для извлечения данных Phantombuster и поиска терминов #covidtravel, а также комбинации #covid и #travel для извлечения твитов. Первоначальные наборы данных включали в общей сложности 50 000 твитов, опубликованных на английском языке; однако после очистки данных и удаления дубликатов постов окончательные наборы данных состояли из 31 800 уникальных твитов. После этого данные прошли предварительную обработку, в ходе которой были удалены все упоминания (например, @users ), хэштеги, неизвестные знаки и эмодзи. Важно отметить, что до этого момента для BERTopic и Top2Vec использовались исходные предложения, поскольку оба алгоритма основаны на подходе внедрения, а сохранение исходной структуры текста имеет жизненно важное значение для моделей-трансформеров.
С другой стороны, данные для LDA и NMF были предварительно обработаны дополнительно с использованием модулей NLP в Python. Точнее, были исключены стоп-слова, удален нерелевантный текст (например, числа, аббревиатуры и неизвестные символы) и выполнена токенизация. После этого шага были проведены стемминг и лемматизация. Первый процесс использовал Porter Stemmer для удаления суффиксов из слов (например, investigating to investig), тогда как последний использовал WordNet Lemmatizer для удаления флективных окончаний и возврата слова к его базовой форме (например, investigating to investig). Наконец, текст был преобразован в вес частоты терминов-обратной частоты документа (TF-IDF) для поиска информации на основе важности ключевого слова.
Реализация тематических моделей
Модель 1: Скрытое распределение Дирихле
LDA, самый популярный метод моделирования тем, представляет собой генеративную вероятностную модель для дискретных наборов данных, таких как текстовые корпуса (Blair et al., 2020 ). Она считается трехуровневой иерархической байесовской моделью, в которой каждый элемент коллекции представлен как конечная смесь по базовому набору тем, а каждая тема представлена как бесконечная смесь по набору вероятностей тем. Следовательно, поскольку количество тем не должно быть заранее определено (Maier et al., 2018 ), применение LDA предоставляет исследователям эффективный ресурс для получения явного представления документа.
В этом исследовании для определения оптимальных значений трех гиперпараметров, необходимых для LDA, был выполнен поиск по сетке для количества тем ( K ), а также для беты и альфы. Чем выше бета, тем больше слов в темах; аналогично, чем выше альфа, тем разнообразнее темы. Поиск оптимального количества тем начинался с диапазона от двух до 15 с шагом в один. На первом этапе процесса обучения K был предопределен, и поиск беты и альфы применялся соответствующим образом. В ходе процесса изменялся только один гиперпараметр, а другой оставался неизменным до достижения наивысшего показателя согласованности. Показатель согласованности, относящийся к качеству извлеченных тем, был представлен для 14 тем со значением 0,52. Затем поиск по сетке дал симметричное распределение со значением 0,91 как для альфы, так и для беты. Наконец, для облегчения четкой интерпретации извлеченной информации из подобранной тематической модели LDA, pyLDAvis использовался для создания карты межтропических расстояний (Islam, 2019 ). Скриншот статистической близости тем можно увидеть на рисунке 1. Интерактивная визуализация доступна по адресу https://tinyurl.com/frontiers-TM .
Рисунок 1.

Модель 2: Неотрицательная матричная факторизация
В отличие от LDA, NMF является декомпозиционным, не вероятностным алгоритмом, использующим матричную факторизацию, и относится к группе линейно-алгебраических алгоритмов (Egger, 2022b ). NMF работает с преобразованными данными TF-IDF, разбивая матрицу на две матрицы более низкого ранга (Obadimu et al., 2019 ). В частности, TF-IDF является мерой для оценки важности слова в коллекции документов. Как показано на рисунке 2 , NMF разлагает свои входные данные, которые являются матрицей термин-документ ( A ), на произведение матрицы термин-темы ( W ) и матрицы темы-документы ( H ) (Chen et al., 2019 ). Значения W и H изменяются итеративно, где первый содержит базисные векторы, а второй содержит соответствующие веса (Chen et al., 2019 ). Необходимо, чтобы все записи W и H были неотрицательными; в противном случае интерпретация тем с отрицательными значениями будет затруднена (Ли и Сын, 1999 ).
Рисунок 2.
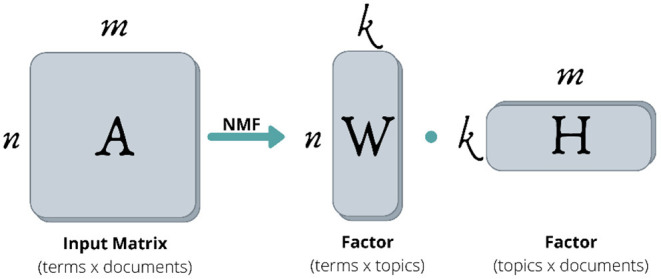
Поскольку NMF требует предварительной обработки данных, необходимые шаги, которые необходимо выполнить заранее, включают классический конвейер NLP, содержащий, среди прочего, строчные буквы, удаление стоп-слов, лемматизацию или стемминг, а также удаление пунктуации и чисел (Egger, 2022b ). Для этого исследования использовалась библиотека Python с открытым исходным кодом Gensim (Islam, 2019 ) для оценки оптимального количества тем. Вычислив наивысшую оценку согласованности, можно было идентифицировать 10 тем.
Модель 3: Top2Vec
Top2Vec (Angelov, 2020 ) — сравнительно новый алгоритм, использующий встраивание слов. То есть векторизация текстовых данных позволяет находить семантически схожие слова, предложения или документы в пределах пространственной близости (Egger, 2022a ). Например, такие слова, как «мама» и «папа», должны быть ближе, чем такие слова, как «мама» и «яблоко». В этом исследовании для создания встраиваний слов и документов использовалась предварительно обученная модель встраивания, Universal Sentence Encoder. Поскольку векторы слов, которые появляются ближе всего к векторам документов, по-видимому, лучше всего описывают тему документа, количество документов, которые можно сгруппировать вместе, представляет собой количество тем (Hendry et al., 2021 ).
Однако, поскольку векторное пространство обычно имеет тенденцию быть разреженным (включая в основном нулевые значения), перед кластеризацией плотности было выполнено уменьшение размерности. Используя равномерное многообразие аппроксимации и проекции (UMAP), измерения были уменьшены до такой степени, что иерархическая пространственная кластеризация приложений на основе плотности с шумом (HDBSCAN) могла быть использована для идентификации плотных областей в документах (Angelov, 2020 ). Наконец, центроид векторов документов в исходном измерении был рассчитан для каждой плотной области, соответствующей вектору темы.
Примечательно, что поскольку слова, которые встречаются в нескольких документах, не могут быть отнесены к одному документу, они были распознаны HDBSCAN как шум. Поэтому Top2Vec не требует какой-либо предварительной обработки (например, удаления стоп-слов), стемминга и лемматизации (Ma et al., 2021 ; Thielmann et al., 2021 ). В заключение этой модели Top2Vec автоматически предоставил информацию о количестве тем, размере тем и словах, представляющих темы.
Модель 4: BERТема
BERTopic (Grootendorst, 2020 ) основывается на механизмах Top2Vec; следовательно, они схожи с точки зрения алгоритмической структуры. Как следует из названия, BERT используется в качестве встраиваемого устройства, а BERTopic обеспечивает извлечение встраиваемых документов с моделью преобразователей предложений для более чем 50 языков. Аналогично, BERTopic также поддерживает UMAP для сокращения размерности и HDBSCAN для кластеризации документов. Основное отличие Top2Vec заключается в применении алгоритма обратной частоты документов на основе классов (c-TF-IDF), который сравнивает важность терминов в кластере и создает представление термина (Sánchez-Franco и Rey-Moreno, 2022 ). Это означает, что чем выше значение термина, тем более он репрезентативен для своей темы.
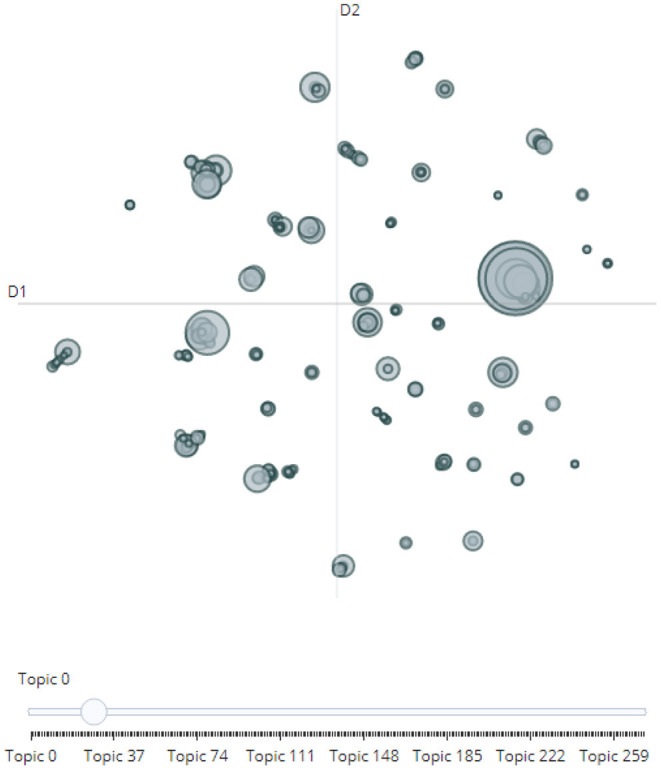
BERTopic, подобно Top2Vec, отличается от LDA, поскольку обеспечивает непрерывное, а не дискретное моделирование тем (Alcoforado et al., 2022 ). Таким образом, стохастическая природа модели приводит к разным результатам при повторном моделировании. После вычисления модели исследователи могут выводить наиболее важные темы. В частности, тема 0 со значением −1 всегда будет представлять выбросы и не должна рассматриваться дальше. Исследователи также могут искать ключевое слово и получать наиболее важные темы на основе их оценки сходства вместе с возможностью проверки отдельных тем на основе их ключевых слов. В конечном счете, чтобы лучше проанализировать потенциально большой массив тем, BERTopic предлагает интерактивную карту межтематических расстояний для проверки отдельных тем (Grootendorst, 2020 ). Как показано на рисунке 3 , как только первоначальный обзор тем становится доступным, можно снова выполнить автоматическое сокращение тем.
Рисунок 3.
Результаты
По сути, хотя тематические модели привносят статистический анализ и могут продвигать исследования в области социальных наук, каждый из алгоритмов имеет свою собственную уникальность и опирается на разные предположения. Количественные методы ограничены в своей способности обеспечивать глубокое контекстуальное понимание, и результаты нельзя сравнивать с каким-либо одним «значением» (Эггер и Ю, 2021 ). Таким образом, интерпретация моделей по-прежнему в значительной степени зависит от человеческого суждения (Ханниган и др., 2019 ) и знания предметной области исследователями (Эггер и Ю, 2022 ).
В следующем разделе сравнение полученных результатов будет разделено на две части в соответствии с природой алгоритма: (1) LDA и NMF и (2) Top2Vec и BERTopic. Последний выделяет функцию поиска терминов как одно из преимуществ использования подхода с направляющими/затравками для более глубокого погружения в определенную тему.
Сравнение LDA и NMF
Таблица 1 содержит обзор 14 выявленных тем в модели LDA и 10 тем из NMF. Названия были даны на основе терминов, которые внесли наибольший вклад в тему в отношении их весов TF-IDF. В целом, несколько аспектов указывают на общие темы, такие как ожидания в отношении реакции правительства, обсуждение значений R (t) и ограничения на поездки в разных странах. Если взять в качестве примера «ответ правительства», то твиты, по-видимому, сосредоточены на ожиданиях людей в отношении Белого дома (например, #whcovidresponse) и президента США (#potus, #vp). Хотя обе модели ссылаются на возможность воссоединиться со своими близкими (например, #loveisnottourism), LDA, в частности, указывает на то, как пандемия COVID-19 повлияла на заявку на получение визы Diversity (например, #dv2021). Аналогичным образом, хотя обе модели раскрывают мнения пользователей Twitter об ограничениях запрета на поездки и карантине, результаты LDA, по-видимому, более географически ориентированы. Например, при обсуждении числа воспроизводства чаще упоминаются европейские страны, Индия и Великобритания. С другой стороны, Англия и Шотландия, по-видимому, являются основными центрами внимания в отношении ограничений на поездки, а что касается твитов, связанных с карантином, LDA раскрывает проблемы, связанные с австралийской границей.
Таблица 1.
Темы, определенные LDA и NMF.
| ЛДА | НМФ | |||
|---|---|---|---|---|
| Нет . | Тема/содержание | Ключевые слова | Тема/содержание | Ключевые слова |
| 1 | Реакция правительства | запрет, travelgov, potus, dv2021, loveisnottourism, whcovidresponse, конец, виза, пожалуйста, вице-президент | Реакция правительства | whocovidresponse, potus, loveisnottourism, cdcdirector, presssec, вице-президент, cdctravel, cdcgov, liftthetravelban, cdctravel cdcdirector |
| 2 | Ассоциация молекулярной патологии (AMP) / маска и вирус | amp, путешествовать, приходить, распространять, маска, место, следовать, оставаться, держать, вирус | Ассоциация молекулярной патологии (AMP) / желание путешествовать | covid, путешествие, люди, amp, хочу, путешествие covid, время, путешествие covid, нравится, год |
| 3 | Значение R t / Индия, Великобритания, Европа | rt, путешествия, страна, Индия, Великобритания, covid, правительство, список, ЕС, новости | Значение Rt | rt, covid, путешествие, https, covid19, путешественник, rt ollysmithtravel, путешественник, httpstco, ollysmithtravel |
| 4 | Ограничение на поездки / Англия и Шотландия | путешествие, ковид, ограничение, город, команда, Англия, несмотря на, событие, ожидать, Шотландия | Ограничение на поездки | ограничение, ограничение на поездки, путешествия из-за covid, путешествия из-за covid19, простота, ограничение из-за covid, путешествие, снятие, ограничение из-за covid19, снятие ограничений |
| 5 | Вакцинация / граница между Канадой и США | вакцинировать, covid19, международный, путешественник, путешествие, вакцинация, Канада, граница, США, полностью | Запрет на поездки / Индия и Великобритания | запрет, Индия, запрет на поездки, путешествие в Индию, Великобритания, список, страна, запрет на поездки, красный, вариант |
| 6 | Карантин и локдаун / Австралия | путешественник, день, карантин, вариант, разрешить, возврат, локдаун, Австралия, перерыв, два | Общее о путешествиях / Канада | covid19, путешествие, путешествие covid19, международный, путешествие covid19, страна, пандемия, международное путешествие, вакцинация, Канада |
| 7 | Случаи COVID-19 / США | случай, новый, путешествие, здоровье, состояние, туризм, общественность, номер, закрыть, включать | Вакцинация и карантин | вакцинировать, полностью, полностью вакцинировать, вакцинировать covid19, путешественник, вакцинировать путешественника, путешественник, карантин, cdc, требовать |
| 8 | Полет / Тест на COVID-19 | тест, путешествие, потребность, положительный, ковид, полет, отрицательный, воздух, брать, аэропорт | Случаи COVID-19 / Новая Зеландия | случай, новый, случай covid, случай covid19, новый случай, рост, Зеландия, Новая Зеландия, отчет, случай covid19 |
| 9 | Смерть / Флорида | covid, умереть, смерть, причина, Флорида, ребенок, шип, стрелять, traveler002, грипп | Тест на COVID-19 | тест, тест на ковид, отрицательный, положительный, тестовая поездка, положительный тест, ПЦР, тест на ковид19, день, результат |
| 10 | Китай и США | путешествия, covid, звонок, китай, бизнес, 2020, трамп, сша, д-р | Пропуск на вакцинацию | вакцина, вакцина covid19, вакцина covid, паспорт, паспорт вакцины, требовать, вакцинация, доза, предписание, вакцинация |
| 11 | Неспецифический I | нет, ковид, вакцина, люди, делать, путешествовать, получить, сделать, все еще, будет | ||
| 12 | Неспецифический II | путешествие, может, covid, 2, пожалуйста, 1, помощь, показ, 3, пропуск | ||
| 13 | Неспецифический III | covid19, путешествие, из-за, пандемия, мир, сегодня, первый, обновление, коронавирус, безопасный | ||
| 14 | Неспецифический IV | covid, быть, идти, путешествовать, время, получить, хотеть, один, год, видеть | ||
Тем не менее, несмотря на то, что LDA, казалось бы, работала лучше до этого момента, модель выдает более универсальные и нерелевантные темы, которые в то же время едва ли предлагают какие-либо значимые последствия. Это можно увидеть в последних четырех темах LDA, перечисленных в Таблице 1 , которые, основываясь на ключевых словах, сосредоточены на путешествиях и COVID-19 на более широком уровне. Поэтому, несмотря на то, что только несколько тем NMF содержат термины, специфичные для страны (например, Новая Зеландия, Индия и Великобритания), ее ценность не следует недооценивать. Из-за четкого различия между всеми выявленными темами в модели NMF это исследование приходит к выводу, что результаты, полученные с помощью NMF, больше соответствуют человеческому суждению, тем самым превосходя LDA в целом. Тем не менее, как упоминалось выше, поскольку извлечение тем с помощью LDA и NMF в первую очередь опирается на гиперпараметры, большинство результатов находятся в пределах ожиданий. Однако, поскольку обе модели не позволяют глубоко понять явление, в следующем разделе мы сосредоточимся на тематических моделях, которые используют представления внедрения.
Сравнение BERTopic и Top2Vec
Опираясь на модель внедрения, BERTopic и Top2Vec требуют интерактивного процесса для проверки тем. Таким образом, оба алгоритма позволяют исследователям находить высокорелевантные темы, вращающиеся вокруг определенного термина, для более глубокого понимания. Используя Top2Vec в демонстрационных целях, этот раздел начинается с интуиции, лежащей в основе поискового запроса. Предполагая, что существует интерес к темам, связанным с термином «отмена» во время COVID-19, модель Top2Vec выдает релевантные результаты (темы) на основе порядка их косинусного сходства (Ghasiya and Okamura, 2021 ). В частности, косинусное сходство в диапазоне от 0 до 1 измеряет сходство между поисковым термином и темой. В данном исследовании из 309 тем наибольшее сходство оказалось у темы 10 [ 0,50 ], за ней следуют тема 20 [ 0,37 ], тема 7 [ 0,33 ], тема 123 [ 0,32 ] и тема 57 [ 0,30 ].
После этого можно извлечь наиболее важные ключевые слова для каждой отдельной темы. Например, ключевые слова для темы 10 включают следующее:
[«возврат», «забронировано», «билет», «отменено», «билеты», «бронирование», «отменить», «рейс», «мой», «привет», «поездка», «телефон», «электронная почта», «я сам», «привет», «не мог бы», «пожалуйста», «имея», «ребята», «я», «сэр», «предполагалось», «надеюсь», «я», «взволнован», «отложить», «так что», «дней», «папа», «оплачено», «опция», «клиенты», «запрос», «бихар», «спасибо», «сумма», «должен», «ожидание», «к», «получил», «назад», «невозможно», «обслуживание», «часы», «завершено», «до», «подождать», «хорошо», «действительно», «книга»] .
Чтобы получить представление о важности каждого термина, можно создать облако слов для лучшей визуализации (см. Рисунок 4 ); но, в конечном счете, также настоятельно рекомендуется изучить отдельные твиты. Например, результаты показывают, что документ 20189 (твиты: «@ PaytmTravel Flight — AI 380 от 9 апреля 2020 г. (отменен из-за COVID). Возврата с тех пор не было […] ») имеет показатель сходства 0,8518 . Эта информация позволяет получить более глубокое понимание непосредственно из необработанных данных. Между тем, чтобы найти более подходящие ключевые слова на основе «отмена» для еще большего анализа, можно вывести наиболее похожие слова с их сходством, например «отменено [ 0,60 ]», «возврат [ 0,49 ]», «забронировано [ 0,47 ]», «срок [ 0,46 ]» и «билет [ 0,43 ]».
Рисунок 4.

После процесса поиска можно было установить сравнение тем между Top2Vec и BERTopic. На этот раз в качестве других примеров были взяты «flight» и «travel bubble». Поскольку ранее было введено косинусное сходство, в следующем разделе просто перечислены некоторые ключевые слова, которые облегчают наименование тем. Как упоминалось выше, это связано с тем, что результаты требуют человеческой интерпретации для осмысления данных (Hannigan et al., 2019 ).
Начиная с «рейса», Таблица 2 дает обзор из 343 выявленных тем, шести наиболее релевантных из BERTopic и пяти из 253 из Top2Vec. В целом темы Top2Vec, по-видимому, больше ориентированы на политику и регулирование, фокусируясь на требованиях к тестированию перед вылетом (например, отрицательный тест ПЦР и полная вакцинация) в таких странах, как Мексика, Нидерланды и Канада. В ней также обсуждаются рекомендации правительства по поездкам на общественном транспорте, таком как поезда, автобусы и самолеты. Для более качественной проверки можно просмотреть соответствующие твиты; например, « Внимание, дорогие пассажиры, путешествующие в […] Пожалуйста, соблюдайте нормы COVID-19 в аэропорту. Летайте безопасно! » и « [Мой] рейс [был] отменен авиакомпаниями из-за covid. Кроме того, моя страховая премия по путешествию потрачена впустую ». С другой стороны, темы, выявленные BERTopic, больше связаны с природой воздушного транспорта. В частности, наиболее распространенные темы, обсуждаемые в Twitter, касаются авиационной отрасли, маршрутов полетов, возвращения домой, передачи вируса по воздуху и ассоциаций авиаперевозок.
Таблица 2.
Темы, определенные BERTopic и Top2Vec для «полета».
| BERТема | Топ2Век | |||
|---|---|---|---|---|
| Нет . | Тема/содержание | Примеры ключевых слов | Тема/содержание | Примеры ключевых слов |
| 1 | Авиационная промышленность | авиаперелеты, авиакомпания, авиаперелеты это, авиакомпании, авиация, рейсы, авиационная индустрия, авиакомпания, авиационная индустрия, полет | Отрицательный результат ПЦР/вакцинация и карантин | часов до, перед отъездом, отрицательный результат теста на ковид, все путешественники, полностью вакцинированы, ПЦР, карантин, дней, требование, обязательно |
| 2 | Маршруты полетов | рейсы из, рейсы, прямые рейсы, рейсы из индии, канада смотрит политику, канада смотрит, индия в канаду, в канаду, запрет на прямые, как индия covid19 | Тесты секретаря Белого дома дали положительный результат / путеводитель от правительственного учреждения | секретарь, Саймон, дом, белый, положительный результат теста, рекомендации по путешествиям, CDC, депутаты, путешественники, следовать |
| 3 | (Невозможно) вернуться домой / Австралийский | австралийцы, запрет на поездки, лететь домой, лететь домой из, кто летит домой, кто летит, в австралию, австралийцы, которые летают, запрет на поездки из-за ковид, запрет на поездки | Отрицательный результат ПЦР / полностью вакцинирован перед отъездом / иностранные путешественники / Мексика | отрицательный результат теста на ковид, полностью вакцинирован, иностранные путешественники, перед отъездом, за несколько часов до, требуется, до вас, для въезда, пцр, мексика |
| 4 | Передача COVID через воздух | воздух, аэрозоли, капли, воздух, воздушно-капельный, ковид распространяется, по воздуху, вирус распространяется, как ковид распространяется, ковид распространяется через | Отрицательный результат ПЦР / полностью вакцинирован перед отъездом / иностранные путешественники / Нидерланды и Канада | отрицательный результат теста на ковид, отъезд, за несколько часов, международные путешественники, полностью вакцинированы, Байден, Соединенные Штаты, требование, Нидерланды, Канадцы |
| 5 | Управление аэропортов Индии (AAI) / Индия | aai, аэропорты, aai аэропорты, аэропорт, аэропорт, рейсы, aai это, аэропорты есть, от aai, воздушное движение | Соблюдайте правила пользования общественным транспортом (поезд/автобус/самолет)/обращайтесь за помощью и дополнительной информацией | поезд, автобус, во время путешествия, covid-соответствует, дополнительная информация, следовать, рекомендации по covid, обязательно, по воздуху, пожалуйста, помогите |
| 6 | Новости аэропорта | новости аэропорт авиаперевозки, авиаперевозки covid19 covid19india, аэропорт авиаперевозки, аэропорт авиаперевозки covid19, путешественники новости аэропорт, авиаперевозки covid19, путешествия covid19, полет путешествия covid19, ассоциации авиаперевозок, аэропорты воздух | ||
Обращаясь к «пузырю путешествий», оба алгоритма выдали пять соответствующих тем, как показано в Таблице 3. В этом случае результаты BERTopic кажутся более конкретными, с четким различием между поездками между Австралией и Новой Зеландией, Сингапуром и Гонконгом, а также Канадой и Мексикой. Другие вопросы сосредоточены на проездных билетах и деловых поездках. Однако, что касается Top2Vec, результаты выявили небольшое совпадение. Например, пузырь путешествий между Австралией и Новой Зеландией рассматривается в четырех из пяти тем; аналогично, Сингапур, Гонконг и Тайвань также упоминаются несколько раз. Кроме того, Top2Vec выдает темы с несколькими аспектами, что становится особенно очевидным в третьей и четвертой темах. Третья тема содержит вопросы, связанные с шестью разными странами (т. е. Гонконгом, Сингапуром, Австралией, Новой Зеландией, Великобританией и Филиппинами), а четвертая включает правила карантина в восьми странах (т. е. Сингапуром, Австралией, Новой Зеландией, Тайванем, Гонконгом, Кореей, Гавайями и Индонезией).
Таблица 3.
Темы, определенные BERTopic и Top2Vec для «туристического пузыря».
| BERТема | Топ2Век | |||
|---|---|---|---|---|
| Нет . | Тема/содержание | Примеры ключевых слов | Тема/содержание | Примеры ключевых слов |
| 1 | Австралия и Новая Зеландия | пузырь путешествий, пузырь путешествий с, пузырь путешествий, пузырь путешествий в австралию, пузырь путешествий в зеландию и австралию, новая зеландия и австралия, путешествие в зеландию, пузырь путешествий в зеландию, пузырь с австралией, пузырь путешествий после путешествия | Австралия и Новая Зеландия / карантинный отель | сидней, виктория, квинсленд, австралия, карантин в отеле, новая зеландия, в отеле, карантин свободный, локдаун, окленд |
| 2 | Сингапур и Гонконг | пузырь, пузырь путешествий, сингапур, пузырь авиаперелетов, пузырь путешествий, пузырь, сингапургонконг, сингапургонконг, ломая сингапургонконг, как сингапур сражается | Австралия и Новая Зеландия / Сингапур / Тайвань / вакцинированы | зеландия, карантин без ограничений, сингапур, карантин в отеле, 2 недели, изолировать, вакцинированные путешественники, локдаун, мельбурн, тайвань |
| 3 | Проездной билет | проездной, проездной covid, eus covid travel, eus covid, eus covid, covid travel, летние путешествия, проездные, проездные как, запуск covid travel | Гонконг и Сингапур / Австралия и Новая Зеландия / зеленый список / вакцинированы / Великобритания / Филиппины | Гонконг, Сингапур, нулевой уровень ковида, Тайвань, зеленый список, Австралия, вакцинированные путешественники, Филиппины, Зеландия, деловые поездки |
| 4 | Необязательные поездки / Паром из Канады в Мексику / Распространение COVID-19 | канада и мексика, необязательные поездки, необязательные поездки в, необязательные поездки, паромные переправы, переправы с канадой, паромные переправы с, земля и паром, и паромные переправы, распространение covid19 | Без карантина / Сингапур / Австралия и Новая Зеландия / Тайвань / Гонконг / Корея / Гавайи / Индонезия | карантин свободный, сингапур, гонконг, окленд, тайвань, корея, сидней, гавайи, индонезия, вакцинированные путешественники |
| 5 | Деловые поездки | деловые поездки, туризм, индустрия путешествий, индустрия путешествий, индустрия туризма, и туризм, путешествия и туризм, и индустрия туризма, путешествия и, индустрия туризма | Сингапур / Гонконг / Австралия / Тайвань / полностью вакцинированы / зеленый список | тайвань, сингапур, гонконг, деловые поездки, зеландия, австралия, полностью вакцинированы, португалия, зеленый список, израиль |
В качестве последнего замечания, при проверке ключевых слов BERTopic и Top2Vec, несмотря на избыточность некоторых терминов (например, «travel bubble» и «travelbubble», поскольку они очень близки в одном векторном пространстве), они, по сути, могут предоставить ценную информацию, особенно для процесса наименования тем. В основном, содержание темы можно понять на основе часто повторяющихся ключевых слов. Более того, что касается логики алгоритма, поскольку BERTopic и Top2Vec не должны подвергаться предварительной обработке, союзные слова (например, after, before to, from, at) полезны для связи контекста. Однако основным недостатком без предварительной обработки является то, что (не)определенные артикли или глаголы be, появляющиеся в списках ключевых слов, часто бессмысленны для понимания темы.
Иерархическое сокращение тем Top2Vec и BERTopic
Наконец, стоит отметить, что и Top2Vec, и BERTopic допускают иерархическую редукцию. Повторяя результаты этого исследования, количество извлеченных тем, как правило, относительно велико, что требует интенсивного качественного анализа. Чтобы упростить анализ, алгоритмы предлагают возможность еще больше сократить эти темы (Angelov, 2020 ). Начиная с Top2Vec, иерархическая редукции до 10 тем обычно считается хорошей отправной точкой для начала анализа тем. В случае этого исследования 10 оставшихся кластеров, вычтенных из 253 исходных тем, представлены в Таблице 4. Примечательно, что исходные векторы сохраняются после редукции тем, что означает, что репрезентативные темы с ключевыми словами по-прежнему можно искать в любое время.
Таблица 4.
Иерархическое сокращение тем Top2Vec.
| Нет . | Тема/содержание | Примеры ключевых слов |
|---|---|---|
| 1 | Виза иммиграционного типа / Студенческая жизнь | Байрон, вина избранных, залив, маска, увеличиваются, студент, грипп, экзамены, навсегда, первая волна, взять, путешествие, положительный результат теста на ковид, там, руки, быстро, хотят, большой, остановить, смерть, межгосударственный, трахаться, убежище, рынок, передача, соответствующий ковиду, Бихар, носить, короткий, экзамен, увеличивается |
| 2 | Виза DV и петиция о визе / свобода / международные поездки / комендантский час COVID-19 | петиция, подписать, тесты на, пцр ковид, вина избранных, борис, форд, онтарио, хочу, комендантский час, премьер, аэропорт, бесплатно, друг, трудо, отложить, проверить, быстро, пакистан, выстрел, великобритания, наслаждаться, остаться, правда, ветка, торонто, туристическая страховка, международные поездки, нормальный, много стран, варианты, зарубежные поездки, свобода, депутаты, межгосударственный, красный список, люди, канадцы, причины, провинция, бихар |
| 3 | Виза иммигрантов разных национальностей / непривитые люди / вакцинация для профилактики | выборочные вина, центры для, ди, болезнь, белый, труд, fauci, экономика, поведение, миллион, не будучи, рынок, стыд, европейцы, керала, американцы, контроль, вот, миллионы, трамп, невакцинированные, купить, выходные, убедитесь, октябрь, и туризм, dv, рабочие места, защищать, магазин, эти выходные, вакцинации, опасения, для вашего, авиаперелеты, в следующем месяце, вакцины, открытый, чтобы облегчить, политический, миллионы, вирус, профилактика, покрытие, планы, наука, мексика, туризм |
| 4 | Политики (Грант Шэппс, Джастин Трюдо, Байден, Трамп, Энтони Фаучи) / страны зеленого списка / международные поездки для вакцинированных людей / Олимпиада / паспорт COVID-19 | о вакцинации, ес, сертификат covid, требование для, запрет, границы с, байден, грант, шаппс, президент, еще хуже, китайский, олимпиада, трудо, европейский, требуется для, цифровой, вакцинированные путешественники, фаучи, многие страны, правосудие, вакцинированные путешественники, проездной, визы, другие страны, трамп, федеральный, страны, австралийцы, зеленый список, закон, инфицированный, джо, граница, полностью, межгосударственные поездки, европа, открытый, в следующем месяце, паспорта covid |
| 5 | До COVID и первая волна / мечты о путешествиях | первая волна, шелби, битва, решения, саймон, они находят, возникновение, их путешествие, бесчисленное множество, жизни, будущее, кто-то, человек, деньги, оправдание, путешествие, любовь, до ковид, доза, счастливый, путешествовал, pfizer, из китая, мечта, вместе, вина избранных, умер от |
| 6 | Жалобы на программу лотереи иммиграционного тура США (COVID-19 как оправдание ее задержки или отмены) | оправдание, набор инструментов, вина избранных, еще хуже, о вакцинации, Уганда, смерть, правосудие, ПЦР-тесты, новые случаи, Аравия, интервью, самый высокий, Соединенные Штаты, веселье, победители, сумасшедший, для полностью, для иностранных, Непал, реализация, ясно, африканский, Нигерия, деловые поездки, Пуэрто-Рико, brexit, аэропорт, требующий, Сингапур |
| 7 | Желтая лихорадка и вакцина от COVID-19 / Саудовская Аравия / Случаи COVID-19 | саудовцы, astrazeneca, путешествие, аравия, будьте в безопасности, новые случаи, цифры covid, доза, nhs covid, волна, носить маску, заболел covid, желтая лихорадка, пройти, приложение, pre covid, врачи, восточный |
| 8 | Направления путешествий / Профилактика / Меры по путешествиям | dv, вина избранных, обвинение, lanka, covid соответствующий, быстро, европейский, решения, союз, они находят, возникновение, победители, рекомендации по путешествиям, увеличение, непал, профилактика, дельта, меры по путешествиям, случаи covid, shelby, всплеск, уровень, не, новые случаи, связанные с поездками, eu, вероятно, hawaii, отложить, индийский, ограничить, битва, florida, увеличиваются, рост covid, олимпийские игры, губернатор |
| 9 | Отрицательный результат ПЦР-теста перед выездом/полная вакцинация для международных поездок | доказательство, отправление, часов до, covid соответствующий, как долго, потребуется, тестирование на covid, отрицательный covid, быть полностью, перед отправлением, показать, требование для, вы должны, требуется, по воздуху, иностранные путешественники, тест на, тест на covid, поведение, вакцинирован против, тест, тест ПЦР, тесты ПЦР, прибытие, полностью вакцинирован, о вакцинации, требование, вакцинации, отрицательный тест, ПЦР, вакцинация, отрицательный, полностью, CDC, требуется, для международного, требования для, дистанцирование, требовать, руководство, по прибытии, дни |
| 10 | Пузырь путешествий / Австралия (включая несколько городов) и Новая Зеландия / Гонконг / Шотландия / без карантина / карантинный отель | Новый Южный Уэльс, Квинсленд, Сидней, Виктория, протестировали, побережье, Шелби, Мельбурн, пузырь путешествий, Зеландия, карантин свободный, Австралия, в отеле, положительный результат, Саймон, Уэльс, приехал из, Конг, случай COVID, положительный результат COVID, битва, положительный результат теста, первая волна, Вик, Большой, Окленд, женщина, их путешествие, Байрон, петиция, карантин в отеле, Шотландия, Юг, армия |
Обращаясь к BERTopic, поскольку некоторые темы находятся близко друг к другу, как можно было наблюдать на карте межтематических расстояний ( рисунок 3 ), визуализация и сокращение тем позволят лучше понять, как темы на самом деле связаны друг с другом. Чтобы сократить количество тем, была выполнена иерархическая кластеризация на основе матрицы косинусных расстояний между вложениями тем. Таким образом, в этом исследовании в качестве примера было взято 100 тем, чтобы дать обзор того, как и в какой степени можно сократить темы ( рисунок 5 ). Уровень 0 дендрограммы демонстрирует, как схожие темы (те, которые имеют одинаковые цвета) были сгруппированы вместе. Например, тема 4 (паспорта вакцины) и тема 8 (приложение NHS COVID-19) были сгруппированы вместе из-за их смежности. Соответственно, тема 6 (ношение масок) и тема 96 (обязательный масочный режим) рассматривались как часть одного и того же кластера. По сути, визуализация как таковая может помочь исследователям лучше понять критерии алгоритма, по которым организованы темы. После рассмотрения предложенной структуры тем исследователи могут затем выбрать несколько тем, которые также кажутся более реалистичными в интерактивном режиме.
Рисунок 5.

Однако для обоих алгоритмов основные значения тем все еще подлежат человеческой интерпретации. Тем не менее, хотя интуиция заключается в том, чтобы обеспечить наилучшие возможные результаты, оптимальное количество тем не может быть установлено, поскольку большинство тем пересекаются друг с другом и охватывают смесь из двух-трех различных аспектов. Например, результаты от Top2Vec ( таблица 4 ) представляют пять тем, связанных с программой виз для иммигрантов разных национальностей США (например, dv, selectees fault, winners, an reason, justice, interview, the pawel, exam) и несколько терминов, связанных с политиками, базирующимися в США и Канаде (например, Grant Shapps, Justin Trudeau, Joe Biden, Donald Trump, Anthony Fauci). Аналогичным образом, осмысление иерархической кластеризации, созданной BERTopic ( рисунок 5 ), также требует огромных усилий, поскольку структура тем меняется всякий раз, когда исследователи экспериментируют с другим количеством тем. Несмотря на возможность использования существующих ноу-хау в области для поиска определенных тем, что отсутствует в других традиционных алгоритмах, исследователи должны быть хорошо осведомлены о вышеупомянутых проблемах. Весь процесс содержит ошибки, и может быть довольно трудоемким найти число, которое соответствует человеческому суждению.
Как показано на рисунке 5 ниже, дендрограмма, созданная BERTopic, показывает уровни агломерации отдельных тем. Эта визуализация, в частности, помогает найти соответствующее количество k-тем. Кроме того, подобно Top2Vec, таблица с ключевыми словами получается после слияния тем; тем не менее, настоятельно рекомендуется также проверять отдельные необработанные документы для более подходящих интерпретаций.
Обсуждение и заключение
Учитывая трудности извлечения полезной информации из коротких и неструктурированных текстов, это исследование намерено противостоять таким проблемам, сравнивая результаты четырех алгоритмов моделирования тем. Для общей оценки, основанной на человеческой интерпретации, это исследование подтверждает эффективность BERTopic и NMF, за которыми следуют Top2Vec и LDA, при анализе данных Twitter. Хотя в целом и BERTopic, и NMF обеспечивают четкое разделение между любыми идентифицированными темами, результаты, полученные от NMF, все еще можно считать относительно «стандартными». Напротив, в дополнение к ожидаемым результатам (т. е. темам), BERTopic смог сгенерировать новые идеи, используя свой подход к внедрению. Хотя Top2Vec также использует предварительно обученные модели внедрения, результаты охватывают больше тем, которые пересекаются и содержат несколько концепций. С другой стороны спектра, подобно NMF, темы, созданные LDA, также не кажутся очень интригующими. Таким образом, несмотря на то, что некоторые темы Top2Vec кажутся неактуальными и сложными для понимания, модель, тем не менее, способна выдавать несколько интересных результатов, редко упоминаемых другими алгоритмами (например, политиками). В результате, в пользу извлечения новых выводов это исследование рекомендует Top2Vec вместо LDA. Чтобы обеспечить более прочную основу для этих рассуждений, теперь будет дана подробная оценка для каждого алгоритма.
Прежде всего, по сравнению с другими методами, BERTopic работает исключительно с предварительно обученными вложениями (Sánchez-Franco и Rey-Moreno, 2022 ) из-за разделения между кластеризацией документов и использованием c-TF-IDF для извлечения представлений тем. Особенно благодаря процедуре c-TF-IDF (Abuzayed и Al-Khalifa, 2021 ), BERTopic может поддерживать несколько вариаций моделирования тем, таких как управляемое моделирование тем, динамическое моделирование тем или моделирование тем на основе классов. Его главная сила заключается в том, что алгоритм хорошо работает в большинстве аспектов области моделирования тем, тогда как другие обычно преуспевают в одном единственном аспекте. Кроме того, после обучения модели BERTopic также можно сократить количество тем (Sánchez-Franco и Rey-Moreno, 2022 ), впоследствии позволяя исследователям остановиться на ряде (реалистичных) тем на основе того, сколько из них было фактически создано.
Немного отличающийся от BERTopic и реализации c-TF-IDF, Top2Vec создает совместно встроенные векторы слов, документов и тем для поиска описаний тем (Angelov, 2020 ). Интуиция, лежащая в основе этого алгоритма, заключается в том, что каждый ввод считается вектором, и переключение между ними является тривиальным. Следовательно, Top2Vec может масштабировать большое количество тем и огромные объемы данных. Такая сила особенно необходима, когда в корпусе появляется несколько языков (Hendry et al., 2021 ). Однако основным недостатком Top2Vec является то, что он не подходит для работы с небольшим объемом данных (Abuzayed and Al-Khalifa, 2021 ; например, <1000 документов). Фактически, у BERTopic и Top2Vec есть ряд общих проблем. Например, хотя генерация выбросов может быть полезной в некоторых случаях, решения могут фактически генерировать больше выбросов, чем ожидалось. Между тем, другой недостаток касается распределения тем: их нельзя сгенерировать в одном документе, поскольку каждый документ назначен одной теме. Хотя вероятности действительно могут быть извлечены, они не эквивалентны фактическому распределению тем.
Что касается NMF и LDA, несмотря на то, что оба алгоритма не требуют от социологов предварительных знаний предметной области, несколько тем, определенных LDA в этом исследовании, дали либо универсальные (Rizvi et al., 2019 ), либо нерелевантные (Alnusyan et al., 2020 ) фрагменты информации. Такая проблема дополнительно отражает выводы исследования о том, что LDA является недетерминированным (Egger and Yu, 2021 ). Для достижения оптимальных результатов LDA обычно требует подробных предположений относительно гиперпараметров; в частности, обнаружение оптимального количества тем обычно оказывается сложной задачей (Egger and Yu, 2021 ). Хотя NMF имеет те же недостатки, можно предположить, что NMF дает лучшие результаты, поскольку алгоритм полагается на взвешивание TF-IDF, а не на сырые частоты слов (Albalawi et al., 2020 ). В то же время, как линейно-алгебраическая модель, ученые обычно соглашаются, что NMF хорошо работает с более короткими текстами (Chen et al., 2019 ), такими как твиты. Поскольку для извлечения тем не требуется никаких предварительных знаний (Albalawi et al., 2020 ), эта сила особенно полезна для исследований, основанных на данных социальных сетей (Blair et al., 2020 ). Кроме того, поскольку LDA извлекает независимые темы из распределений слов, темы, которые считаются несходными в документе, не могут быть идентифицированы отдельно (Campbell et al., 2015 ), что приводит к перекрывающимся кластерам (Passos et al., 2011 ). В противовес этому другие ученые считают, что недостаточная статистическая информация для извлечения признаков является основополагающим фактором, лежащим в основе дублирующихся тем (Cai et al., 2018 ).
Наконец, при сравнении BERTopic с NMF, основным недостатком NMF является его низкая способность идентифицировать встроенные значения в корпусе (Blair et al., 2020 ). Учитывая, что алгоритм в первую очередь зависит от нормы Фробениуса (Chen et al., 2019 ), которая обычно полезна для числовой линейной алгебры, эта проблема в конечном итоге приводит к трудностям в интерпретации результатов (Wang and Zhang, 2021 ). Хотя NMF может эффективно анализировать зашумленные данные (Blair et al., 2020 ), другие утверждают, что точность не может быть гарантирована (Albalawi et al., 2020 ).
На основе результатов этого исследования, как обсуждалось выше, в Таблице 5 суммированы плюсы и минусы применения LDA, NMF, BERTopic и Top2Vec, чтобы помочь ученым-социологам в необходимых этапах предварительной обработки, правильной настройке гиперпараметров и понятной оценке их результатов. Однако исследователи должны учитывать, что в зависимости от характера наборов данных тематические модели не всегда могут работать одинаково (Egger and Yu, 2021 ).
Таблица 5.
Сравнение тематических моделей.
| Преимущества | Недостатки | |
|---|---|---|
| ЛДА | • Не обязательно требуются предварительные знания предметной области • Находит связные темы при применении правильной настройки гиперпараметров • Может работать с разреженными входными данными • Количество тем, как правило, меньше, чем в подходах, основанных на внедрении слов; таким образом, его легче интерпретировать • Один документ может содержать несколько разных тем (смешанное извлечение членства) • Генерируются полные генеративные модели с многономинальным распределением по темам • Показывает как прилагательные, так и существительные в темах |
• Требуются подробные предположения • Гиперпараметры должны быть тщательно настроены • Результаты могут легко привести к перекрывающимся темам, поскольку темы представляют собой мягкие кластеры • Объективные метрики оценки широко отсутствуют • Количество тем должно определяться пользователем (пользователями) • Поскольку результаты не являются детерминированными, надежность и валидность не гарантируются автоматически • Предполагается, что темы независимы друг от друга; следовательно, используется только частота общего появления слов • Корреляции слов игнорируются, поэтому невозможно смоделировать никакие связи между темами |
| НМФ | • Не требуется предварительного знания предметной области • Поддерживает смешанные модели членства; таким образом, один документ может содержать несколько тем • В отличие от LDA, который использует сырые частоты слов, матрица термин-документ может быть взвешена с помощью TF-IDF • Она оказывается вычислительно эффективной и очень масштабируемой • Легко реализуется |
• Часто выдает непоследовательные темы • Количество извлекаемых тем должно быть определено пользователем заранее • Неявная спецификация вероятностных генеративных моделей |
| Топ2Век | • Поддерживает иерархическое сокращение тем • Позволяет проводить многоязычный анализ • Автоматически находит количество тем • Создает совместно встроенные векторы слов, документов и тем • Содержит встроенные функции поиска (легко переходить от темы к документам, искать темы и т. д.) • Может работать с очень большими размерами наборов данных • Использует встраивания, поэтому предварительная обработка исходных данных не требуется |
• Подход с внедрением может привести к слишком большому количеству тем, требующему трудоемкой проверки каждой темы • Генерирует много выбросов • Не очень подходит для небольших наборов данных (<1000) • Каждый документ назначается одной теме • Отсутствуют объективные метрики оценки |
| BERТема | • Высокая универсальность и стабильность в разных доменах • Позволяет проводить многоязычный анализ • Поддерживает варианты моделирования тем (управляемое моделирование тем, динамическое моделирование тем или моделирование тем на основе классов) • Использует встраивания, поэтому предварительная обработка исходных данных не требуется • Автоматически находит количество тем • Поддерживает иерархическое сокращение тем • Содержит встроенные функции поиска (легко переходить от темы к документам, искать темы и т. д.) • Более широкая поддержка моделей встраивания, чем у Top2Vec |
• Подход с внедрением может привести к слишком большому количеству тем, требующему трудоемкой проверки каждой темы. • Генерирует много выбросов. • В рамках одного документа не генерируется распределение тем; вместо этого каждый документ назначается одной теме. • Отсутствуют объективные метрики оценки. |
Теоретические и практические вклады
В свете расширения пользовательского контента социальные сети расширили горизонты человеческого взаимодействия и спровоцировали новые явления и социальные исследования для дальнейшего изучения (Murthy, 2012 ; Rizvi et al., 2019 ; Boccia Artieri et al., 2021 ). Хотя несколько недавних исследований поручились за изучение коротких текстовых данных социальных сетей (Albalawi et al., 2020 ; Qiang et al., 2020 ), существующие знания довольно ограничены традиционными методами моделирования, такими как LDA и LSA (Albalawi et al., 2020 ). Поскольку эволюция тематического моделирования привела к появлению новых методов, особенно тех, которые редко применялись или оценивались в социальных науках, это исследование ценно тем, что оно отвечает на призыв оценить тематическое моделирование посредством тщательного сравнения четырех различных алгоритмов (Reisenbichler and Reutterer, 2019 ). Кроме того, в этом исследовании рассматриваются светлые и темные стороны применения встроенных и стандартных тематических моделей, а также предлагается исследователям в области социальных наук понимание методологических проблем, которые могут препятствовать формированию знаний.
Предвидя, что социологи действительно могут колебаться в выборе подходящего алгоритма при анализе данных социальных сетей, это исследование представляет возможные методологические проблемы и способствует эффективности двух различных типов тематических моделей. Если быть более точным, применение BERTopic для генерации идей из короткого и неструктурированного текста предлагает наибольший потенциал, когда речь идет о тематических моделях на основе встраивания. Таким образом, это исследование признает способность BERTopic кодировать контекстную информацию (Чонг и Чен, 2021 ), аспект, который может оставаться скрытым другими моделями. Что касается традиционных алгоритмов тематических моделей, исследования в области социальных наук поощряются к рассмотрению NMF как альтернативного подхода к общепринятому LDA (Галлахер и др., 2017 ). Конечно, однако, важно отметить, что каждая модель имеет свои собственные сильные и слабые стороны, а результаты требуют интенсивной качественной интерпретации. Наконец, это исследование также стремится внести еще один важный вклад, изложив решения управляемого моделирования, которые могут применяться социологами к анализу данных для извлечения знаний.
Ограничения и рекомендации для будущих исследований
Это исследование, безусловно, не лишено ограничений. Хотя это исследование отвечает на необходимость использования Top2Vec и BERTopic для анализа данных коротких текстов (Egger и Yu, 2021 ; Sánchez-Franco и Rey-Moreno, 2022 ), новые языковые модели, такие как GPT3 и WuDao 2.0, продолжают появляться с течением времени (Nagisetty, 2021 ), тем самым выступая в качестве превосходной основы для еще более мощных подходов к моделированию тем. Чтобы использовать использование методов моделирования тем, социальным ученым рекомендуется пробовать и оценивать другие недавно разработанные алгоритмы и поддерживать свои знания в актуальном состоянии. В случае этого исследования Twitter был выбран из-за его строгих правил относительно количества символов, разрешенных для одного твита, что делает его идеальной платформой для поисковых исследований. Тем не менее, методологический подход в этом исследовании должен быть применим и к другим каналам, поскольку сообщения в социальных сетях, как правило, короткие и неструктурированные (Kasperiuniene et al., 2020 ). Однако по-прежнему важно отметить, что природа социальных сетей различается с точки зрения демографии пользователей, представления текста или риторики, среди прочего. Таким образом, будущие исследования должны продолжить изучение эффективности алгоритмов моделирования тем на других платформах. Наконец, также важно признать эпистемологические проблемы больших данных; независимо от огромных объемов данных, которые могут показаться заманчивыми на первый взгляд, алгоритмы должны быть контекстуализированы в определенной социальной структуре (Egger and Yu, 2022 ). Хотя тематические модели количественно оценили короткие текстовые данные социальных сетей, как интерпретация, так и обоснование результатов идут в ущерб точности данных. Таким образом , наличие обширных знаний в области науки, основанной на данных (Canali, 2016 ), позволит ученым-социологам преобразовывать количественную аналитику в ценные идеи для приобретения знаний.
Заявление о доступности данных
Оригинальные материалы, представленные в исследовании, включены в статью/дополнительные материалы, дальнейшие запросы можно направлять соответствующему автору.
Вклады авторов
RE собрал и проанализировал данные. JY написал рукопись в консультации с RE и интерпретировал данные. Оба автора разработали исследование и отвечали за общее управление и планирование. Все авторы внесли свой вклад в статью и одобрили представленную версию.
Конфликт интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Примечание издателя
Все заявления, высказанные в этой статье, принадлежат исключительно авторам и не обязательно представляют заявления их аффилированных организаций или заявления издателя, редакторов и рецензентов. Любой продукт, который может быть оценен в этой статье, или заявление, которое может быть сделано его производителем, не гарантируется и не одобряется издателем.
Ссылки
- Абузайед А., Аль-Халифа Х. (2021). BERT для моделирования арабских тем: экспериментальное исследование техники BERTopic. Proc. Comput. Sci. 189, 191–194. 10.1016/j.procs.2021.05.096 [ DOI ] [ Google Scholar ]
- Albalawi R., Yeap TH, Benyoucef M. (2020). Использование методов тематического моделирования для данных с коротким текстом: сравнительный анализ. Front. Artif. Intellig. 3:42. 10.3389/frai.2020.00042 [ DOI ] [ Бесплатная статья PMC ] [ PubMed ] [ Google Scholar ]
- Алькофорадо А., Ферраз Т.П., Гербер Р., Бустос Э., Оливейра А.С., Велосо Б.М. и др. (2022). ZeroBERTo — использование нулевой классификации текста посредством тематического моделирования. arXiv [Препринт]. arXiv: 2201.01337. Чам: Форталеза, Португалия и Спрингер. Доступно онлайн по адресу: http://arxiv.org/pdf/2201.01337v1 [ Академия Google ]
- Alnusyan R., Almotairi R., Almufadhi S., Shargabi AA, Alshobaili J. (2020). «Полуконтролируемый подход к моделированию и классификации тем пользовательских отзывов», Международная конференция по вычислениям и информационным технологиям 2020 г. (Пискатауэй, Нью-Джерси: IEEE; ), 1–5. 10.1109/ICCIT-144147971.2020.9213721 [ DOI ] [ Google Scholar ]
- Андерсон К. (2008). Конец теории: поток данных делает научный метод устаревшим. Доступно онлайн по адресу: https://www.wired.com/2008/06/pb-theory/ (дата обращения: 1 февраля 2022 г.).
- Angelov D. (2020). Top2Vec: Распределенные представления тем. Доступно онлайн по адресу: http://arxiv.org/pdf/2008.09470v1 (дата обращения: 12 февраля 2022 г.).
- Арефьева В., Эггер Р., Ю Дж. (2021). Подход машинного обучения к кластеризации изображения места назначения в Instagram. Tour. Manag. 85:104318. 10.1016/j.tourman.2021.104318 [ DOI ] [ Google Scholar ]
- Ариффин SNAN, Тиун С. (2020). Нормализация текста на основе правил для малайских текстов социальных сетей. Int. J. Adv. Comput. Sci. Appl. 11:21. 10.14569/IJACSA.2020.0111021 [ DOI ] [ Google Scholar ]
- Bi J.-W., Liu Y., Fan Z.-P., Cambria E. (2019). Моделирование удовлетворенности клиентов из онлайн-обзоров с использованием ансамблевой нейронной сети и модели Кано на основе эффектов. Int. J. Prod. Res. 57, 7068–7088. 10.1080/00207543.2019.1574989 [ DOI ] [ Google Scholar ]
- Blair SJ, Bi Y., Mulvenna MD (2020). Агрегированные тематические модели для повышения согласованности тем в социальных сетях. Appl. Intellig. 50, 138–156. 10.1007/s10489-019-01438-z [ DOI ] [ Google Scholar ]
- Бочча Артьери Дж., Греко Ф., Ла Рокка Дж. (2021). Формирование значений #коронавируса в Twitter: анализ первоначальных реакций итальянцев. Int. Rev. Sociol. 31, 287–309. 10.1080/03906701.2021.1947950 [ DOI ] [ Google Scholar ]
- Брэдли SD, Мидс R. (2002). Трансформации поверхностной структуры и рекламные слоганы: аргументы в пользу умеренной синтаксической сложности. Psychol. Market. 19, 595–619. 10.1002/mar.10027 [ DOI ] [ Google Scholar ]
- Cai G., Sun F., Sha Y. (2018). Интерактивная визуализация для курирования тематической модели. Токио: IUI Workshops. [ Google Scholar ]
- Cai T., Zhou Y. (2016). Что социологи должны знать о больших данных? ISA eSymposium 6, 1–9. Доступно онлайн по адресу: https://esymposium.isaportal.org/resources/resource/what-should-sociologists-know-about-big-data/ [ Google Scholar ]
- Campbell JC, Hindle A., Stroulia E. (2015). Скрытое распределение Дирихле: извлечение тем из данных по программной инженерии. Art Sci. Anal. Softw. Data 9, 139–159. 10.1016/B978-0-12-411519-4.00006-9 [ DOI ] [ Google Scholar ]
- Канали С. (2016). Большие данные, эпистемология и причинность: знание в и знание из в EXPOsOMICS. Big Data Soc. 3:205395171666953. 10.1177/2053951716669530 [ DOI ] [ Google Scholar ]
- Chen Y., Zhang H., Liu R., Ye Z., Lin J. (2019). Экспериментальные исследования по извлечению информации из коротких текстовых тем между схемами на основе LDA и NMF. Knowl. Based Syst. 163, 1–13. 10.1016/j.knosys.2018.08.011 [ DOI ] [ Google Scholar ]
- Чонг М., Чэнь Х. (2021). Расистское фрейминг через стигматизированное именование: тематический и геолокационный анализ #Chinavirus и #Chinesevirus в Twitter. Proc. Assoc. Inform. Sci. Technol. 58, 70–79. 10.1002/pra2.437 [ DOI ] [ Google Scholar ]
- Эггер Р. (2022a). «Текстовые представления и встраивание слов. Векторизация текстовых данных», в Прикладная наука о данных в туризме. Междисциплинарные подходы, методологии и приложения, под ред. Р. Эггера (Берлин: Springer; ), 16. 10.1007/978-3-030-88389-8_16 [ DOI ] [ Google Scholar ]
- Эггер Р. (2022b). «Моделирование тем. Моделирование скрытых семантических структур в текстовых данных», в Прикладная наука о данных в туризме. Междисциплинарные подходы, методологии и приложения, под ред. Р. Эггера (Берлин: Springer; ), 18. 10.1007/978-3-030-88389-8_18 [ DOI ] [ Google Scholar ]
- Эггер Р., Пагири А., Продингер Б., Лю Р., Веттингер Ф. (2022). «Тематическое моделирование туристического питания на основе модели GLOBE», в конференции ENTER22 e-Tourism (Берлин: Springer; ), 356–368. 10.1007/978-3-030-94751-4_32 [ DOI ] [ Google Scholar ]
- Эггер Р., Ю Дж. (2021). Выявление скрытых семантических структур в данных Instagram: сравнение моделирования тем. Tour. Rev. 2021:244. 10.1108/TR-05-2021-0244 [ DOI ] [ Google Scholar ]
- Эггер Р., Ю Дж. (2022). «Эпистемологические проблемы», в Прикладная наука о данных в туризме. Междисциплинарные подходы, методологии и приложения, под ред. Р. Эггера (Берлин: Springer; ), 2. 10.1007/978-3-030-88389-8_2 [ DOI ] [ Google Scholar ]
- Elragal A., Klischewski R. (2017). Прогнозирование, основанное на теории или процессе? Эпистемологические проблемы аналитики больших данных. J. Big Data 4:2. 10.1186/s40537-017-0079-2 [ DOI ] [ Google Scholar ]
- Femenia-Serra F., Gretzel U., Alzua-Sorzabal A. (2022). Instagram travel influencers in #quarantine: communication practices and roles during COVID-19. Tour. Manag. 89:104454. 10.1016/j.tourman.2021.104454 [ DOI ] [ Бесплатная статья PMC ] [ PubMed ] [ Google Scholar ]
- Галлахер Р.Дж., Рейнг К., Кейл Д., Вер Стиег Г. (2017). Объяснение закрепленной корреляции: тематическое моделирование с минимальным знанием предметной области. Trans. Assoc. Comput. Linguist. 5, 529–542. 10.1162/tacl_a_00078 [ DOI ] [ Google Scholar ]
- Ghasiya P., Okamura K. (2021). Исследование новостей COVID-19 в четырех странах: подход к моделированию тем и анализу настроений. IEEE Access 9, 36645–36656. 10.1109/ACCESS.2021.3062875 [ DOI ] [ Бесплатная статья PMC ] [ PubMed ] [ Google Scholar ]
- Гроотендорст М. (2020). BERTopic: Использование BERT и c-TF-IDF для создания легко интерпретируемых тем. Zenodo. 10.5281/zenodo.4430182 [ DOI ] [ Google Scholar ]
- Гроотендорст М. (2022). BERTopic: Моделирование нейронных тем с помощью процедуры TF-IDF на основе классов. arXiv:2203.05794v0571. Доступно онлайн по адресу: https://arxiv.org/pdf/2203.05794.pdf (дата обращения: 15 марта 2022 г.).
- Guo Y., Barnes SJ, Jia Q. (2017). Извлечение смысла из онлайн-рейтингов и обзоров: анализ удовлетворенности туристов с использованием латентного распределения Дирихле. Tour. Manag. 59, 467–483. 10.1016/j.tourman.2016.09.009 [ DOI ] [ Google Scholar ]
- Hannigan TR, Haans RFJ, Vakili K., Tchalian H., Glaser VL, Wang MS и др. (2019). Тематическое моделирование в исследованиях по менеджменту: создание новой теории из текстовых данных. Acad. Manag. Ann. 13, 586–632. 10.5465/annals.2017.0099 [ DOI ] [ Google Scholar ]
- Hendry D., Darari F., Nurfadillah R., Khanna G., Sun M., Condylis PC и др. (2021). «Моделирование тем для чатов обслуживания клиентов», Международная конференция по передовым компьютерным наукам и информационным системам 2021 г. (Пискатауэй, Нью-Джерси: IEEE; ), 1–6. 10.1109/ICACSIS53237.2021.9631322 [ DOI ] [ Google Scholar ]
- Хонг Л., Дэвисон Б.Д. (2010). Эмпирическое исследование моделирования тем в Twitter. Proc. First Workshop Soc. Media Analyt. 2010, 80–88. 10.1145/1964858.196487034208483 [ DOI ] [ Google Scholar ]
- Ху В. (2012). Настроения в Twitter в реальном времени по отношению к промежуточным экзаменам. Sociol. Mind 2, 177–184. 10.4236/sm.2012.22023 [ DOI ] [ Google Scholar ]
- Ислам Т. (2019). Йога-веганство: корреляционный анализ данных о здоровье в Twitter. Анкоридж, Аляска: Ассоциация вычислительной техники. [ Google Scholar ]
- Jaradat S., Matskin M. (2019). «О динамических тематических моделях для добычи социальных сетей», в Lecture Notes in Social Networks. Emerging Research Challenges and Opportunities in Computational Social Network Analysis and Mining, ред. N. Agarwal, N. Dokoohaki и S. Tokdemir (Берлин: Springer; ), 209–230. 10.1007/978-3-319-94105-9_8 [ DOI ] [ Google Scholar ]
- Жубер М., Костас Р. (2019). Знакомство с научными пользователями Twitter: пилотный анализ южноафриканских пользователей Twitter, которые пишут в Twitter о научных статьях. J. Altmetr. 2:2. 10.29024/joa.8 [ DOI ] [ Google Scholar ]
- Kasperiuniene J., Briediene M., Zydziunaite V. (2020). «Автоматический контент-анализ коротких текстов социальных сетей: обзор методов и инструментов», в Advances in Intelligent Systems and Computing. Computer Supported Qualitative Research, ред. AP Costa, LP Reis и A. Moreira (Берлин: Springer; ), 89–101. 10.1007/978-3-030-31787-4_7 [ DOI ] [ Google Scholar ]
- Китчин Р. (2014). Большие данные, новые эпистемологии и сдвиги парадигм. Big Data Soc. 1:205395171452848. 10.1177/2053951714528481 [ DOI ] [ Google Scholar ]
- Kraska T., Talwalkar A., Duchi JC, Griffith R., Franklin MJ, Jordan MI (2013). MLbase: распределенная система машинного обучения. CIDR 1, 1–7. Доступно онлайн по адресу: http://www.cidrdb.org/cidr2013/Papers/CIDR13_Paper118.pdf [ Google Scholar ]
- Кришна А., Сатулури П., Шарма С., Кумар А., Гоял П. (2016). «Идентификация типа соединения в санскрите: какую роль играют корпус и грамматика?» в Трудах 6-го семинара по обработке естественного языка в Южной и Юго-Восточной Азии (Осака: ), 1–10. [ Google Scholar ]
- Lazer D., Radford J. (2017). Данные из машины: введение в большие данные. Ann. Rev. Sociol. 43, 19–39. 10.1146/annurev-soc-060116-053457 [ DOI ] [ Google Scholar ]
- Lee DD, Seung HS (1999). Изучение частей объектов с помощью неотрицательной матричной факторизации. Nature 401, 788–791. 10.1038/44565 [ DOI ] [ PubMed ] [ Google Scholar ]
- Ли Цюй, Ли С., Чжан С., Ху Дж., Ху Дж. (2019). Обзор интеллектуального анализа больших данных по туризму на основе текстовых корпусов. Appl. Sci. 9:3300. 10.3390/app9163300 [ DOI ] [ Google Scholar ]
- Lu Y., Zheng Q. (2021). Динамика общественного мнения в Twitter о круизном туризме во время пандемии COVID-19. Curr. Iss. Tour. 24, 892–898. 10.1080/13683500.2020.1843607 [ DOI ] [ Google Scholar ]
- Lupton D. (2015). Тринадцать P больших данных. Эта социологическая жизнь. Доступно онлайн по адресу: https://simplysociology.wordpress.com/2015/05/11/the-thirteen-ps-of-big-data/ (дата обращения: 14 февраля 2022 г.).
- Ma P., Zeng-Treitler Q., Nelson SJ (2021). Использование двух методов тематического моделирования для исследования нерешительности в отношении вакцины COVID. Int. Conf. ICT Soc. Hum. Beings 2021 384, 221–226. Доступно онлайн по адресу: https://www.ict-conf.org/wp-content/uploads/2021/07/04_202106C030_Ma.pdf [ Google Scholar ]
- Майер Д., Вальдхерр А., Милтнер П., Видеманн Г., Никлер А., Кейнерт А. и др. (2018). Применение тематического моделирования LDA в коммуникационных исследованиях: к действенной и надежной методологии. Коммун. Методы измерения. 12, 93–118. 10.1080/19312458.2018.1430754 [ DOI ] [ Академия Google ]
- Mazanec JA (2020). Скрытое теоретизирование в аналитике больших данных: со ссылкой на исследования дизайна туризма. Ann. Tour. Res. 83:102931. 10.1016/j.annals.2020.102931 [ DOI ] [ Google Scholar ]
- McFarland DA, Lewis K., Goldberg A. (2016). Социология в эпоху больших данных: подъем судебной социальной науки. Am. Sociol. 47, 12–35. 10.1007/s12108-015-9291-8 [ DOI ] [ Google Scholar ]
- Moreau N., Roy M., Wilson A., Atlani Duault L. (2021). «Жизнь важнее футбола»: сравнительный анализ твитов и комментариев в Facebook относительно отмены Кубка африканских наций 2015 года в Марокко. Int. Rev. Sociol. Sport 56, 252–275. 10.1177/1012690219899610 [ DOI ] [ Google Scholar ]
- Müller O., Junglas I., vom Brocke J., Debortoli S. (2016). Использование аналитики больших данных для исследования информационных систем: проблемы, обещания и рекомендации. Eur. J. Inform. Syst. 25, 289–302. 10.1057/ejis.2016.2 [ DOI ] [ Google Scholar ]
- Murthy D. (2012). На пути к социологическому пониманию социальных медиа: теоретизирование Twitter. Социология 46, 1059–1073 10.1177/0038038511422553 [ DOI ] [ Google Scholar ]
- Нагисетти В. (2021). Тестирование и обучение нейронных сетей на основе знаний предметной области. (Магистерская диссертация: ), Университет Ватерлоо, Ватерлоо, Онтарио, Канада. [ Google Scholar ]
- Обадиму А., Мид Э., Агарвал Н. (2019). «Выявление скрытых токсичных функций на YouTube с использованием неотрицательной матричной факторизации», в Девятой международной конференции по технологиям социальных сетей, коммуникации и информатике (Валенсия: ), 1–6. [ Google Scholar ]
- Park S., Ok C., Chae B. (2016). Использование данных Twitter для маркетинга и исследований круизного туризма. J. Travel Tour. Market. 33, 885–898. 10.1080/10548408.2015.1071688 [ DOI ] [ Google Scholar ]
- Пассос А., Уоллах Х. М., МакКаллум А. (2011). «Корреляции и антикорреляции в выводе LDA», в Трудах семинара 2011 года по проблемам в обучении иерархическим моделям: трансферное обучение и оптимизация (Гранада), 1–5. [ Google Scholar ]
- Qiang J., Qian Z., Li Y., Yuan Y., Wu X. (2020). Методы моделирования тем коротких текстов, приложения и производительность: обзор. IEEE Trans. Know. Data Eng. 34, 1427–1445. 10.1109/TKDE.2020.2992485 [ DOI ] [ Google Scholar ]
- Queiroz MM (2018). Структура, основанная на Twitter и аналитике больших данных для повышения показателей устойчивости. Environ. Qual. Manag. 28, 95–100. 10.1002/tqem.21576 [ DOI ] [ Google Scholar ]
- Reisenbichler M., Reutterer T. (2019). Тематическое моделирование в маркетинге: последние достижения и исследовательские возможности. J. Bus. Econ. 89, 327–356. 10.1007/s11573-018-0915-7 [ DOI ] [ Google Scholar ]
- Rizvi RF, Wang Y., Nguyen T., Vasilakes J., Bian J., He Z., Zhang R. (2019). Анализ данных социальных сетей для понимания потребностей потребителей в информации о пищевых добавках. Stud. Health Technol. Inform. 264, 323–327. 10.3233/SHTI190236 [ DOI ] [ Бесплатная статья PMC ] [ PubMed ] [ Google Scholar ]
- Sabate F., Berbegal-Mirabent J., Cañabate A., Lebherz PR (2014). Факторы, влияющие на популярность брендированного контента на фан-страницах Facebook. Eur. Manag. J. 32, 1001–1011. 10.1016/j.emj.2014.05.001 [ DOI ] [ Google Scholar ]
- Sánchez-Franco MJ, Rey-Moreno M. (2022). Зависят ли отзывы путешественников от места назначения? Анализ прибрежных и городских одноранговых мест размещения. Psychol. Market. 39, 441–459. 10.1002/mar.21608 [ DOI ] [ Google Scholar ]
- Шафкат В., Бюн Й.-Ч. (2020). Механизм рекомендаций для недооцененных туристических мест с использованием тематического моделирования и анализа настроений. Устойчивость 12:320. 10.3390/su12010320 [ DOI ] [ Google Scholar ]
- She J., Zhang T., Chen Q., Zhang J., Fan W., Wang H. и др. (2022). Какие посты в социальных сетях вызывают наибольший ажиотаж? Данные из WeChat. Internet Res. 32, 273–291. 10.1108/INTR-12-2019-0534 [ DOI ] [ Google Scholar ]
- Симсек З., Ваара Э., Паручури С., Надкарни С., Шоу Дж. Д. (2019). Новые способы просмотра больших данных. акад. Менеджер. Дж. 62, 971–978. 10.5465/amj.2019.4004 [ DOI ] [ Академия Google ]
- Thielmann AF, Weisser C., Kneib T., Saefken B. (2021). «Кластеризация документов на основе согласованности», в The International Conference on Learning Representations (Online), 1–14. [ Google Scholar ]
- Vu HQ, Li G., Law R. (2019). Выявление неявных предпочтений в активности в маршрутах путешествий с помощью тематического моделирования. Tour. Manag. 75, 435–446. 10.1016/j.tourman.2019.06.011 [ DOI ] [ Google Scholar ]
- Wang J., Zhang X.-L. (2021). Deep NMF Topic Modeling. Доступно онлайн по адресу: http://arxiv.org/pdf/2102.12998v1 (дата обращения: 18 января 2022 г.).
- Witkemper C., Lim CH, Waldburger A. (2012). Социальные медиа и спортивный маркетинг: изучение мотивов и ограничений пользователей Twitter. Sport Market. Quart. 21, 170–183. Доступно онлайн по адресу: https://is.muni.cz/el/1423/podzim2013/ZUR589b/um/SM_W8_Twitter_Sports_Marketing.pdf [ Google Scholar ]
- Xue J., Chen J., Hu R., Chen C., Zheng C., Su Y. и др. (2020). Обсуждения и эмоции в Twitter по поводу пандемии COVID-19: подход машинного обучения. J. Med. Internet Res. 22:e20550. 10.2196/20550 [ DOI ] [ Бесплатная статья PMC ] [ PubMed ] [ Google Scholar ]
- Ян М., Назир С., Сюй Ц., Али С. (2020). Алгоритмы глубокого обучения и многокритериальное принятие решений, используемые в больших данных: систематический обзор литературы. Complexity 2020, 1–18. 10.1155/2020/6618245 [ DOI ] [ Google Scholar ]
- Ю Дж., Эггер Р. (2021). Цвет и вовлеченность в туристических фотографиях в Instagram: подход машинного обучения. Ann. Tour. Res. 2021:103204. 10.1016/j.annals.2021.103204 [ DOI ] [ Google Scholar ]
- Чжоу Л., Пан С., Ван Дж., Василакос А.В. (2017). Машинное обучение на больших данных: возможности и проблемы. Neurocomputing 237, 350–361. 10.1016/j.neucom.2017.01.026 [ DOI ] [ Google Scholar ]