«Разработайте конвейер обработки 10 миллионов документов без каких-либо искажений».
На первый взгляд, это похоже на проблему с моделью.
Возможно, ответ кажется простым: использовать самый мощный доступный LLM, увеличить контекстное окно, подключить его к векторной базе данных и позволить ему отвечать.
Но в масштабах предприятия такой подход быстро дает сбои.
Когда вы работаете с более чем 10 миллионами документов, сложность заключается не в их генерации. Сложность состоит в поиске правильных доказательств, подтверждении их достоверности и обеспечении соответствия модели этим доказательствам.
Даже мощная модель может давать ложные результаты, если поиск информации неэффективен. Большое контекстное окно может дать сбой, если вставлены неправильные фрагменты. Векторная база данных может возвращать семантически похожий, но фактически нерелевантный контент.
Вот почему серьезная система RAG — это не просто «LLM + встраивания».
Это полноценный конвейер для поиска, ранжирования, оценки достоверности, генерации, цитирования, анализа и мониторинга.
- Настоящая цель: не просто ответить — докажите правильность ответа ✅
- Шаг 1: Загрузка и нормализация документов 📚
- Шаг 2: Используйте гибридный поиск, а не только семантический поиск 🔎
- Шаг 3: Поиск с помощью искусственных нейронных сетей быстро находит кандидатов ⚡
- Шаг 4: Переранжирование повышает релевантность 🎯
- Шаг 5: Оценка достоверности источника 🧾
- Шаг 6: Генерация с ограничениями обеспечивает устойчивость модели 🤖
- Шаг 7: Ответы, подкрепленные ссылками, укрепляют доверие 📌
- Шаг 8: Добавьте резервный слой галлюцинаций 🚨
- Шаг 9: Непрерывная оценка обязательна 🧪
- Шаг 10: Кэширование и использование памяти улучшают задержку ⚡
- Шаг 11: Наблюдаемость повсюду 👀
- Почему качество поиска важнее, чем модель 🧠
- Заключительная мысль 💙
Настоящая цель: не просто ответить — докажите правильность ответа ✅
В обычном чат-боте пользователь задает вопрос, а модель отвечает.
В системе RAG с высокими ставками этого недостаточно.
Система должна отвечать только при наличии достаточных доказательств. Она должна указывать точные источники, которые были использованы. Она должна отвергать неполный контекст. Она должна объяснять неопределенность. Она должна фиксировать, как был получен ответ. А если доказательств недостаточно, она должна указать на это, вместо того чтобы придумывать правдоподобный ответ.
В этом и заключается истинный смысл выражения «никаких галлюцинаций».
Строго говоря, ни одна система искусственного интеллекта не может гарантировать абсолютное отсутствие галлюцинаций при любых возможных условиях. Но можно спроектировать архитектуру таким образом, чтобы галлюцинации становились намного сложнее, их было легче обнаружить и вероятность их появления у пользователя была значительно ниже.
Система должна вести себя не столько как писатель-самоучка, сколько как осторожный помощник исследователя.
Не следует задавать вопрос: «Какой ответ покажется вам хорошим?»
В задании следует спросить: «Что я могу доказать, используя полученные источники?» 🔐
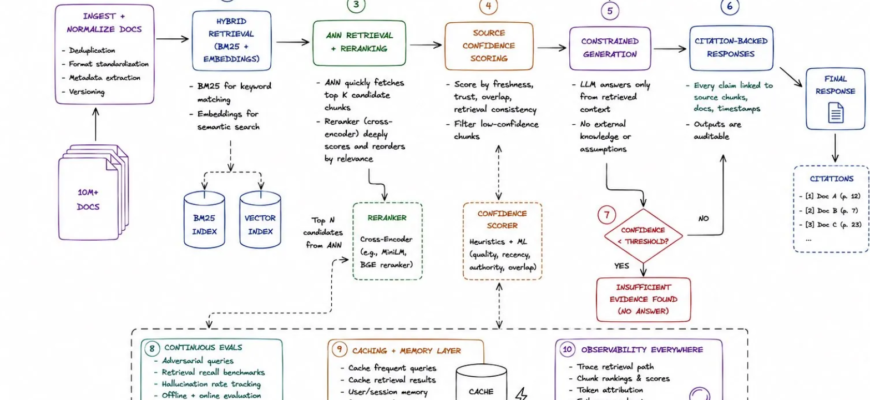
Шаг 1: Загрузка и нормализация документов 📚
Система RAG начинает работать задолго до того, как пользователь задаст вопрос.
Всё начинается с приема внутрь.
Когда у вас более 10 миллионов документов, они редко бывают идеально чистыми. Это могут быть PDF-файлы, HTML-страницы, файлы Word, электронные таблицы, вики-страницы, внутренние базы знаний, электронные письма, заявки, отсканированные документы и экспорт через API. Некоторые из них дублируются. Некоторые устарели. В некоторых отсутствуют метаданные. Некоторые имеют версии. Некоторые содержат таблицы, сноски, изображения или ссылки.
Если проглотить что-либо неаккуратно, то и извлечь это тоже будет неаккуратно.
Первый шаг — это всё нормализовать.
Документы следует дедуплицировать, чтобы система не получала один и тот же ответ из десяти немного отличающихся друг от друга копий. Форматы следует стандартизировать, чтобы обеспечить согласованность при последующей сегментации и индексировании. Метаданные следует извлекать тщательно: заголовок документа, автор, отдел, метка времени, версия, права доступа, исходная система, тип документа и уровень доверия.
История версий тоже имеет значение. Политика 2021 года может противоречить политике 2026 года. Если система не может определить актуальность информации, она может уверенно ссылаться на устаревшие данные.
Вот почему процесс приема данных — это не просто загрузка данных.
Это подготовка знаний. 🧠
Шаг 2: Используйте гибридный поиск, а не только семантический поиск 🔎
В масштабах, близких к реальным, одного лишь семантического поиска недостаточно.
Эмбеддинги отлично справляются с передачей смысла. Они помогают системе понять, что «срок возмещения расходов сотруднику» и «период подачи заявки на возмещение расходов» могут относиться к схожим понятиям.
Однако при работе с векторными представлениями могут возникать проблемы с точными идентификаторами, кодами продуктов, юридическими терминами, номерами полисов, сообщениями об ошибках, именами и редкими ключевыми словами.
Вот почему БМ25 по-прежнему имеет значение.
BM25 — это традиционный метод лексического поиска. Он хорошо справляется с сопоставлением ключевых слов. Если пользователь ищет конкретный код ошибки, номер нормативного документа, пункт договора или имя поля API, BM25 может превзойти векторные представления.
Надежная корпоративная система RAG сочетает в себе оба подхода:
BM25 для точной оценки ключевых слов.
Эмбеддинги для оценки семантического значения.
Этот гибридный подход повышает полноту и точность. Он выявляет документы, которые может пропустить чистый векторный поиск, и отфильтровывает нечеткие семантические совпадения, которые кажутся связанными, но на самом деле не имеют отношения к делу.
При объеме более 10 миллионов документов поиск не сводится к использованию одного-единственного хитрого метода поиска.
Речь идёт о сочетании взаимодополняющих сигналов. ⚙️
Шаг 3: Поиск с помощью искусственных нейронных сетей быстро находит кандидатов ⚡
Прямой поиск по миллионам фрагментов документов обходится дорого.
Именно поэтому в системах векторного поиска используется искусственная нейронная сеть (ИНС) — метод приблизительного поиска ближайшего соседа.
Методы искусственных нейронных сетей быстро извлекают наиболее похожие на векторное представление запроса фрагменты, являющиеся лучшими кандидатами. При этом они жертвуют небольшой точностью ради значительного повышения скорости.
Это крайне важно в масштабах предприятия.
Система не может глубоко сравнивать пользовательский запрос с каждым фрагментом в корпусе из 10 миллионов документов. Вместо этого она сначала сужает пространство поиска. Искусственная нейронная сеть извлекает управляемый набор кандидатов, часто это 50, 100 или 500 лучших фрагментов.
Но искусственная нейронная сеть — это только первый этап.
Это быстро, но не идеально.
Многие команды допускают ошибку, отправляя результаты ANN напрямую в LLM. Это часто приводит к слабым результатам, поскольку лучшие совпадения векторов могут быть не самым надежным доказательством.
После получения списка кандидатов необходимо провести переранжирование.
Шаг 4: Переранжирование повышает релевантность 🎯
Переранжирование — это процесс, в результате которого качество поиска значительно улучшается.
После того как алгоритмы BM25 и векторный поиск извлекают подходящие фрагменты, алгоритм переранжирования оценивает их более глубоко. Например, алгоритм переранжирования на основе кросс-кодировщика сравнивает запрос и каждый подходящий фрагмент вместе, а не полагается только на предварительно вычисленные эмбеддинги.
Это позволяет получить более точный показатель релевантности.
Функция переранжирования может изменять порядок кандидатов, повышать в рейтинге наиболее релевантные фрагменты и понижать в рейтинге фрагменты, имеющие лишь косвенную связь.
Для этой цели обычно используются такие модели, как MiniLM, BGE-реранжировщики или другие подходы, основанные на кросс-кодировании. Точная модель зависит от требований к задержке, предметной области и точности.
Переранжирование особенно важно, когда корпус документов огромен, поскольку разница между «связанными» и «подтверждающими ответ» документами становится критической.
Фрагмент текста может быть семантически похожим, но при этом не давать ответа на вопрос.
Хороший инструмент для переранжирования помогает отделить полезные данные от фонового шума. ✨
Шаг 5: Оценка достоверности источника 🧾
Релевантность поиска не то же самое, что надежность источника.
Фрагмент данных может хорошо соответствовать запросу, но при этом быть устаревшим, малонадежным, дублирующимся, неполным или противоречить более надежным источникам.
Именно поэтому для серьезной системы обработки данных RAG необходима оценка достоверности источника.
Каждому полученному фрагменту следует присвоить оценку достоверности, основанную на таких факторах, как актуальность, авторитетность, уровень доверия к документу, совпадение с другими полученными источниками, согласованность поиска и качество метаданных.
Например, официальный документ с изложенной на прошлой неделе политикой должен иметь больший вес, чем старое сообщение в Slack трехлетней давности. Источник из утвержденной базы знаний должен иметь более высокий рейтинг, чем непроверенная заметка. Утверждению, подкрепленному несколькими независимыми фрагментами, следует доверять больше, чем утверждению, найденному в одном ненадежном источнике.
Фрагменты с низкой степенью достоверности не должны оказывать существенного влияния на генерацию.
В некоторых случаях их следует полностью отфильтровать.
Это одно из главных отличий между игрушечными и серийными игрушками RAG.
Производственный RAG должен знать не только то, что актуально, но и то, чему можно доверять. 🔐
Шаг 6: Генерация с ограничениями обеспечивает устойчивость модели 🤖
После того как система соберет и оценит доказательства, LLM сможет сгенерировать ответ.
Но модель должна быть ограничена.
Инструкция должна быть ясной: отвечайте, используя только полученный контекст. Не используйте внешние знания. Не заполняйте пробелы. Не гадайте. Если контекст не содержит достаточно доказательств, укажите, что доказательств было найдено недостаточно.
Это меняет роль модели.
Оно больше не выступает в роли механизма обобщения знаний. Оно действует как слой синтеза, накладываемый на полученные данные.
В командной строке для генерации запроса должны быть указаны пользовательский запрос, выбранные фрагменты исходного текста, метаданные о достоверности, идентификаторы цитирования и строгие правила вывода.
В критически важных ситуациях система может также потребовать от модели создания ссылок на уровне утверждений. Это означает, что каждое важное утверждение должно быть связано с фрагментом исходного текста.
Это заставляет модель оставаться подотчетной.
Без ограничений в генерации даже мощный конвейер извлечения данных может быть подорван чрезмерно самоуверенной моделью.
Шаг 7: Ответы, подкрепленные ссылками, укрепляют доверие 📌
Ответ RAG без ссылок на источники вряд ли заслуживает доверия.
Ответы, подкрепленные ссылками на источники, делают систему подлежащей аудиту.
Каждое важное утверждение должно содержать ссылку на документ, страницу, фрагмент текста, временную метку или идентификатор источника. Это позволит пользователям и аудиторам проверить, откуда получен ответ.
Например, вместо того чтобы сказать:
«Срок возмещения — 30 дней».
Система, подкреплённая ссылками, гласит:
«Согласно правилам командировок версии 4.2, страница 12, срок возмещения расходов составляет 30 дней после их утверждения».
Это гораздо эффективнее.
Ссылки также упрощают отладку. Если ответ неверный, инженеры могут проверить, был ли получен неверный документ, неправильно ли ранжировался вариант, был ли слишком завышен показатель достоверности источника или модель неправильно истолковала контекст.
Благодаря цитированию, RAG превращается из «черного ящика» в систему, подкрепленную доказательствами. 📚
Шаг 8: Добавьте резервный слой галлюцинаций 🚨
Иногда самый безопасный ответ — это отсутствие ответа.
Если уровень достоверности поиска падает ниже заданного порогового значения, система не должна генерировать ответ. Она должна вернуть что-то вроде:
«Для ответа на этот вопрос найдено недостаточно доказательств».
Это не неисправность. Это мера безопасности.
Наличие эффекта галлюцинаций в качестве запасного варианта предотвращает превращение слабых доказательств в уверенный ответ.
Пороговое значение может зависеть от области применения. Бот службы поддержки клиентов может допускать умеренную степень уверенности при ответе на общие вопросы. В юридических, медицинских, финансовых или нормативных системах потребуется гораздо более веское доказательство.
На этом уровне система отдает предпочтение доверию, а не полноте.
Пользователи могут предпочесть честное «Я не знаю» отполированному, но ложному ответу.
В корпоративном ИИ сдержанность — это отличительная черта. 🛡️
Шаг 9: Непрерывная оценка обязательна 🧪
Конвейер RAG никогда не завершается.
Документы меняются. Модели встраивания меняются. Поведение пользователей меняется. Появляются новые граничные случаи. Качество поиска снижается. Индексы устаревают. Стратегии сегментации данных быстро устаревают.
Постоянная оценка обеспечивает честность системы.
Конвейер обработки данных следует протестировать с помощью состязательных запросов, эталонных показателей точности поиска, тестов на фиктивные результаты, наборов данных для офлайн-оценки и отзывов реальных пользователей.
Особенно полезны запросы, направленные на выявление уязвимостей. Они проверяют, отвечает ли система, когда должна отказать, ссылается ли она на слабые источники, путает ли она похожие документы и выдумывает ли недостающие детали.
Показатели полноты поиска измеряют, присутствует ли правильный источник в наборе кандидатов. Это критически важно, поскольку, если поиск не удается, генерация не может быть восстановлена.
Отслеживание частоты галлюцинаций помогает измерить, как часто ответы содержат неподтвержденные утверждения.
Оценка должна проводиться непрерывно, а не один раз перед запуском.
Система RAG без оценок — это просто вибрации с векторной базой данных. 😅
Шаг 10: Кэширование и использование памяти улучшают задержку ⚡
При объеме более 10 миллионов документов поиск может быть дорогостоящим.
Многие корпоративные пользователи задают повторяющиеся или похожие вопросы. Кэширование часто задаваемых запросов, результатов поиска, переранжированных фрагментов и окончательных ответов может значительно сократить задержку и снизить затраты.
Кэширование следует проводить с осторожностью.
Необходимо соблюдать права доступа, актуальность документа и контекст пользователя. Кэшированный ответ для одного пользователя может быть небезопасен для другого, если настройки доступа различаются. Кэшированный ответ может устареть, если изменится базовый документ.
Память также может помочь персонализировать ответы или сохранить контекст сессии. Но память не должна заменять доказательства, полученные в ходе последующего извлечения информации. Она должна поддерживать рабочий процесс, а не становиться неконтролируемым источником истины.
Лучшие системы кэшируют пути поиска и проверенные данные, а не случайные результаты работы модели.
Скорость полезна только тогда, когда сохраняется правильность. 🚀
Шаг 11: Наблюдаемость повсюду 👀
В таком масштабе необходимо заглянуть внутрь трубопровода.
Наблюдаемость должна отслеживать весь путь поиска: исходный запрос, переписанный запрос (если таковой имеется), результаты BM25, векторные результаты, кандидаты ANN, оценки переранжировщика, оценки достоверности, выбранные фрагменты, отклоненные фрагменты, подсказка для генерации, цитаты, использование токенов, задержка и конечный результат.
Это важно, потому что отказы RAG могут происходить на многих уровнях.
Запрос может быть неоднозначным.
Разбиение на фрагменты может быть некачественным.
Модель встраивания может пропустить нужный документ.
Система переранжирования может понизить рейтинг лучшего источника.
Система оценки достоверности может доверять устаревшему контенту.
LLM может неправильно интерпретировать таблицу.
Без возможности наблюдения команды не могут диагностировать эти сбои.
Панели мониторинга, трассировки, журналы сбоев и атрибуция токенов обеспечивают удобство сопровождения системы.
Если вы не можете выяснить, почему был получен тот или иной ответ, вы не сможете ответственно внедрить систему.
Почему качество поиска важнее, чем модель 🧠
Для документов объемом более 10 миллионов единиц модель «передовой технологии» не является основным узким местом.
Извлечение информации — это…
Убедительный магистерский диплом не сможет дать правильный ответ, если необходимые доказательства не попадут в контекст. Он может показаться более продуманным, но всё равно будет основан на неверной информации.
Именно поэтому качество RAG в значительной степени зависит от обработки данных, сегментации, метаданных, гибридного поиска, переранжирования, оценки достоверности и анализа.
Данная модель представляет собой финальный синтезатор.
Система поиска является основой.
Улучшение поиска информации зачастую повышает качество ответов больше, чем переход на более крупную модель.
В масштабах предприятия даже самая умная в мире модель по-прежнему ограничена теми данными, которые вы ей предоставляете. 🔍
Заключительная мысль 💙
Разработка конвейера RAG для обработки более 10 миллионов документов с практически нулевым уровнем искажений не сводится к подключению LLM к векторной базе данных.
Речь идёт о создании надёжной системы знаний.
Вам необходимы: корректный ввод данных, гибридный поиск, поиск с использованием искусственных нейронных сетей, переранжирование, оценка достоверности источника, генерация с ограничениями, ответы, подкрепленные цитированием, резервное поведение, непрерывная оценка, кэширование, память и наблюдаемость.
Самый важный принцип прост:
Система должна отвечать только на то, что может доказать.
Если доказательства убедительны, дайте обоснованный ответ.
Если доказательства слабы, так и скажите.
Если выдвигается утверждение, укажите на него источник.
Если что-то не подтверждается, проследите причину.
Так RAG переходит от демо-версии к производственной версии.
А в 2026 году искусственный интеллект в производстве — это уже не про то, чтобы казаться умным.
Речь идёт о том, чтобы быть заслуживающим доверия.